一眼看懂
封面预览
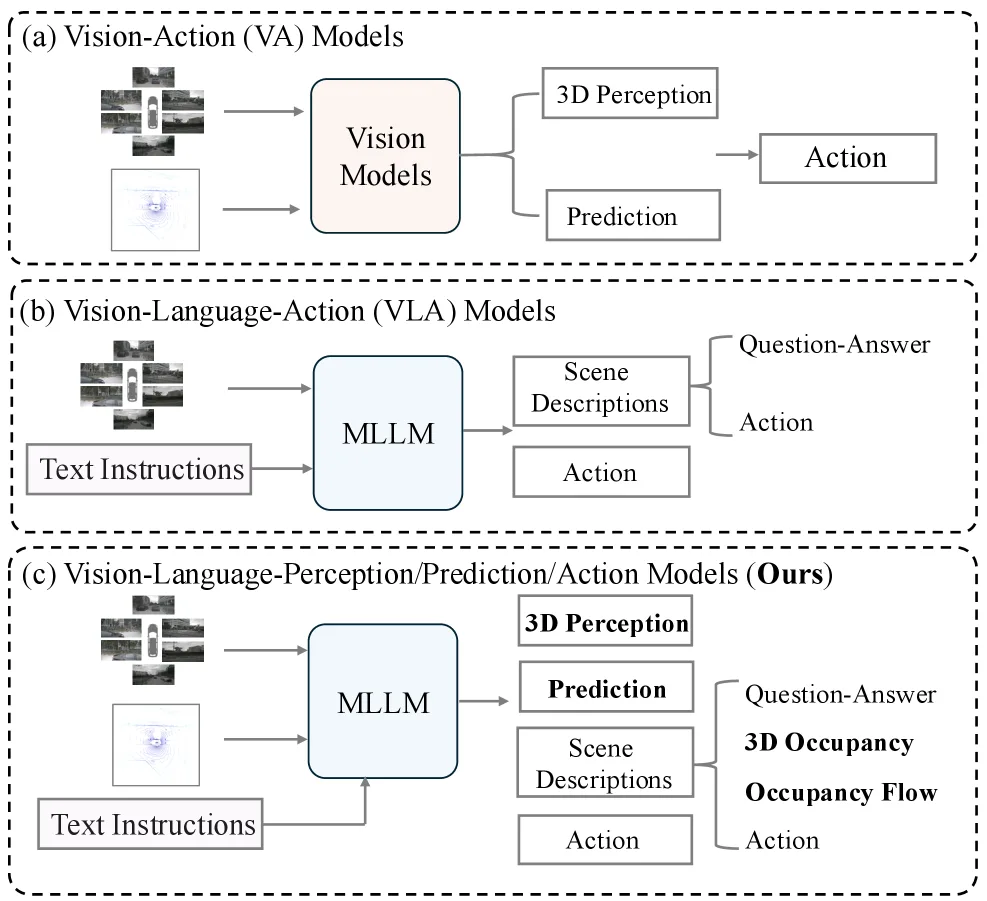
提出 DrivePI,首个统一的空间感知 4D 多模态大语言模型(MLLM)框架,用于端到端自动驾驶
- 提出 DrivePI,首个统一的空间感知 4D 多模态大语言模型(MLLM)框架,用于端到端自动驾驶
- 同时实现粗粒度的语言空间理解与细粒度的 3D 感知(occupancy)、预测(flow)和规划(planning),弥合视觉-动作(VA)模…
- 解决现有 VLA 模型缺乏细粒度 3D 中间输出导致的可解释性和安全性不足问题,以及 VA 模型缺乏自然语言交互能力的问题
Card 01
研究单位
研究单位
- The University of Hong Kong(香港大学)
- Yinwang Intelligent Technology Co. Ltd.(引望智能技术有限公司)
- Tianjin University(天津大学)
- Huazhong University of Science and Technology(华中科技大学)
Card 02
论文概述
论文概述
- 提出 DrivePI,首个统一的空间感知 4D 多模态大语言模型(MLLM)框架,用于端到端自动驾驶
- 同时实现粗粒度的语言空间理解与细粒度的 3D 感知(occupancy)、预测(flow)和规划(planning),弥合视觉-动作(VA)模型与视觉-语言-动作(VLA)模型之间的鸿沟
- 解决现有 VLA 模型缺乏细粒度 3D 中间输出导致的可解释性和安全性不足问题,以及 VA 模型缺乏自然语言交互能力的问题
Card 03
核心贡献
核心贡献
- 提出首个统一的空间感知 4D MLLM 框架 DrivePI,无缝集成粗粒度语言理解与细粒度 3D 感知能力
- 引入 LiDAR 作为补充感知模态,结合多视角图像提供精确 3D 几何信息,增强 MLLM 的空间理解能力
- 开发数据引擎生成 text-occupancy 和 text-flow QA 对,构建 4D 空间理解基准测试
- 仅用 0.5B 参数的 Qwen2.5 作为 MLLM 主干,在 3D occupancy、flow 和规划任务上超越现有专用 VA 模型,同时保持与 VLA 框架相当的语言交互能力
Card 04
方法描述
方法描述
- 采用多模态视觉编码器处理多视角图像和 LiDAR 点云,生成潜在 BEV 特征
- 设计 Spatial Projector 将 BEV 特征映射到语言空间,通过 patchify 和交叉注意力机制保留细粒度空间信息
- 四个专用输出头:Text Head(场景理解)、3D Occupancy Head(体素级感知)、Occupancy Flow Head(像素级运动预测)、Action Diffusion Head(轨迹规划)
- 端到端联合优化所有任务,采用加权损失函数平衡语言理解、3D 感知、预测和规划目标
Card 05
数据集与资源
数据集与资源
- nuScenes 数据集(750 训练场景,150 验证场景,150 测试场景)
- OpenOcc 和 Occ3D 用于 3D occupancy 评估
- nuScenes-QA(377k QA 对)及自生成数据(84k 场景描述、560k 4D 空间推理 QA、24k 规划推理 QA)
- 模型规模:0.5B 参数(Qwen2.5-0.5B),可选 3B 版本
- 训练资源:8 × NVIDIA L40S GPUs
Card 06
评估与结果
评估与结果
- 3D Occupancy (OpenOcc):RayIoU 49.3%,超越 FB-OCC 10.3%,超越 ALOcc-Flow-3D 7.4%
- Occupancy Flow (OpenOcc):mAVE 0.509,优于 FB-OCC 的 0.591
- Planning (nuScenes):L2 error 0.40m,碰撞率 0.11%(使用 ego status),比 ORION 降低 70% 碰撞率(0.37%→0.11%),比 VAD 降低 32% L2 误差(0.72m→0.49m,无 ego status)
- Text Understanding (nuScenes-QA):准确率 60.7%,超越 OpenDriveVLA-7B 2.5%
- Occ3D:RayIoU 46.0%,超越 OPUS 4.8%