一眼看懂
封面预览
提出 Motus,一个统一的潜动作世界模型(Unified Latent Action World Model),旨在解决现有具身智能方法中模…
- 提出 Motus,一个统一的潜动作世界模型(Unified Latent Action World Model),旨在解决现有具身智能方法中模…
- 整合五种主流范式(VLA、世界模型、IDM、视频生成模型、视频-动作联合预测模型)于单一框架,实现场景理解、未来想象、后果预测和动作生成的统一
- 解决两大核心挑战:统一多模态生成能力,以及利用大规模异构数据(互联网视频、人类演示、多机器人轨迹)进行预训练
Card 01
研究单位
研究单位
- 清华大学计算机科学与技术系、人工智能研究院、BNRist中心、THBI实验室、清华-博世联合机器学习研究中心
- 北京大学
- 地平线机器人(Horizon Robotics)
Card 02
论文概述
论文概述
- 提出 Motus,一个统一的潜动作世界模型(Unified Latent Action World Model),旨在解决现有具身智能方法中模型碎片化的问题
- 整合五种主流范式(VLA、世界模型、IDM、视频生成模型、视频-动作联合预测模型)于单一框架,实现场景理解、未来想象、后果预测和动作生成的统一
- 解决两大核心挑战:统一多模态生成能力,以及利用大规模异构数据(互联网视频、人类演示、多机器人轨迹)进行预训练
Card 03
核心贡献
核心贡献
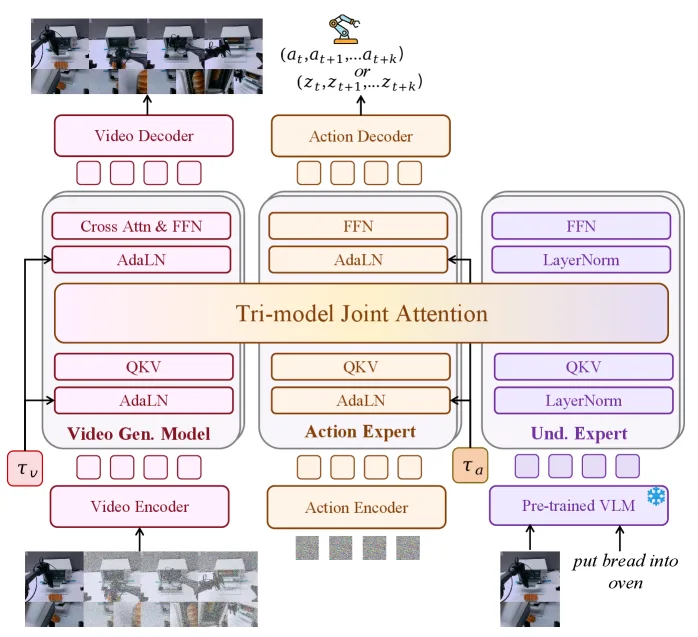
- 首个统一五种主流具身智能范式的端到端基础模型,通过 Mixture-of-Transformers (MoT) 架构融合预训练专家(VGM、VLM、动作专家)
- 提出基于光流(Optical Flow)的潜动作表示,将像素级运动信息编码为可共享的"delta动作",实现跨具身迁移
- 设计三阶段训练流程(视频预训练→潜动作预训练→目标机器人微调)和六层数据金字塔,支持从网络规模数据到目标机器人数据的分层利用
- 提出 Tri-model Joint Attention 机制和 UniDiffuser-style 调度器,实现多专家间的跨模态知识融合与灵活推理模式切换
- 在仿真环境(RoboTwin 2.0)和真实世界任务中均取得显著提升,相比 X-VLA 提升 +15%,相比 π₀.₅ 提升 +45%
Card 04
方法描述
方法描述
- 架构设计:采用 MoT(Mixture-of-Transformers) 架构,三个专家(生成专家-Wan 2.2 5B、理解专家-Qwen3-VL-2B、动作专家)共享多头自注意力层,保持独立前馈网络
- 潜动作学习:使用 DC-AE(Deep Compression Autoencoder) 将光流压缩为14维潜向量,通过90%无标签数据自监督重建 + 10%有标签数据弱监督对齐真实动作空间
- 训练策略:Action-Dense Video-Sparse Prediction —— 视频帧率降为动作帧率的1/6,平衡视频token与动作token数量,防止过拟合视频预测
- 推理灵活性:通过分配不同时间步和噪声尺度,支持五种推理模式自适应切换(VLA、WM、IDM、VGM、Joint Prediction)
Card 05
数据集与资源
数据集与资源
- 六层数据金字塔:Level 1(Web数据)、Level 2(第一人称人类视频)、Level 3(合成数据)、Level 4(任务无关数据)、Level 5(多机器人任务轨迹)、Level 6(目标机器人任务数据)
- 数据来源:AgiBotWorld、RoboMind、RDT、EgoDex、RoboTwin等
- 基础模型:Wan 2.2 5B(视频生成)、Qwen3-VL-2B(视觉-语言理解)
- 光流计算:DPFlow
Card 06
评估与结果
评估与结果
- 仿真环境:RoboTwin 2.0(50+任务,Clean/Randomized双设置)
- 对比基线:π₀.₅、X-VLA、无预训练版本、仅Stage-1版本
- 关键结果:
- 在 *Pick Dual Bottles* 任务:Motus 96% vs π₀.₅ 10%(Clean)、90% vs 6%(Randomized)
- 在 *Stack Blocks Three* 任务:Motus 91% vs X-VLA 6%(Clean)
- 在 *Turn Switch* 任务:Motus 84% vs π₀.₅ 5%、X-VLA 40%
- 真实世界:相比 π₀.₅ 提升 +11%~48%