一眼看懂
封面预览
提出 BLURR,一个轻量级的 VLA (Vision-Language-Action) 模型推理加速框架,可在无需重新训练的情况下直接应用于…
- 提出 BLURR,一个轻量级的 VLA (Vision-Language-Action) 模型推理加速框架,可在无需重新训练的情况下直接应用于…
- 解决 VLA 模型推理延迟过高(超过 30-50 Hz 实时控制需求)的问题,使其能够在消费级 GPU 上实现响应式网页演示和高频机器人控制
- 通过在 π₀ (Pi-0) 模型上的实例化验证,实现了数量级的推理加速,同时保持原始模型的观测接口和检查点不变
Card 01
研究单位
研究单位
- University of Notre Dame (圣母大学)
- Lehigh University (里海大学)
Card 02
论文概述
论文概述
- 提出 BLURR,一个轻量级的 VLA (Vision-Language-Action) 模型推理加速框架,可在无需重新训练的情况下直接应用于现有 VLA 控制器
- 解决 VLA 模型推理延迟过高(超过 30-50 Hz 实时控制需求)的问题,使其能够在消费级 GPU 上实现响应式网页演示和高频机器人控制
- 通过在 π₀ (Pi-0) 模型上的实例化验证,实现了数量级的推理加速,同时保持原始模型的观测接口和检查点不变
Card 03
核心贡献
核心贡献
- 无需重新训练或修改模型架构:BLURR 作为推理包装器,可直接应用于现有 OpenVLA、Pi-0、TraceVLA 等检查点,不改变模型参数
- 多维度推理优化:结合指令前缀 KV 缓存、BF16 混合精度执行、单步控制策略、torch.compile 图编译和 FlashAttention 内核,实现全方位加速
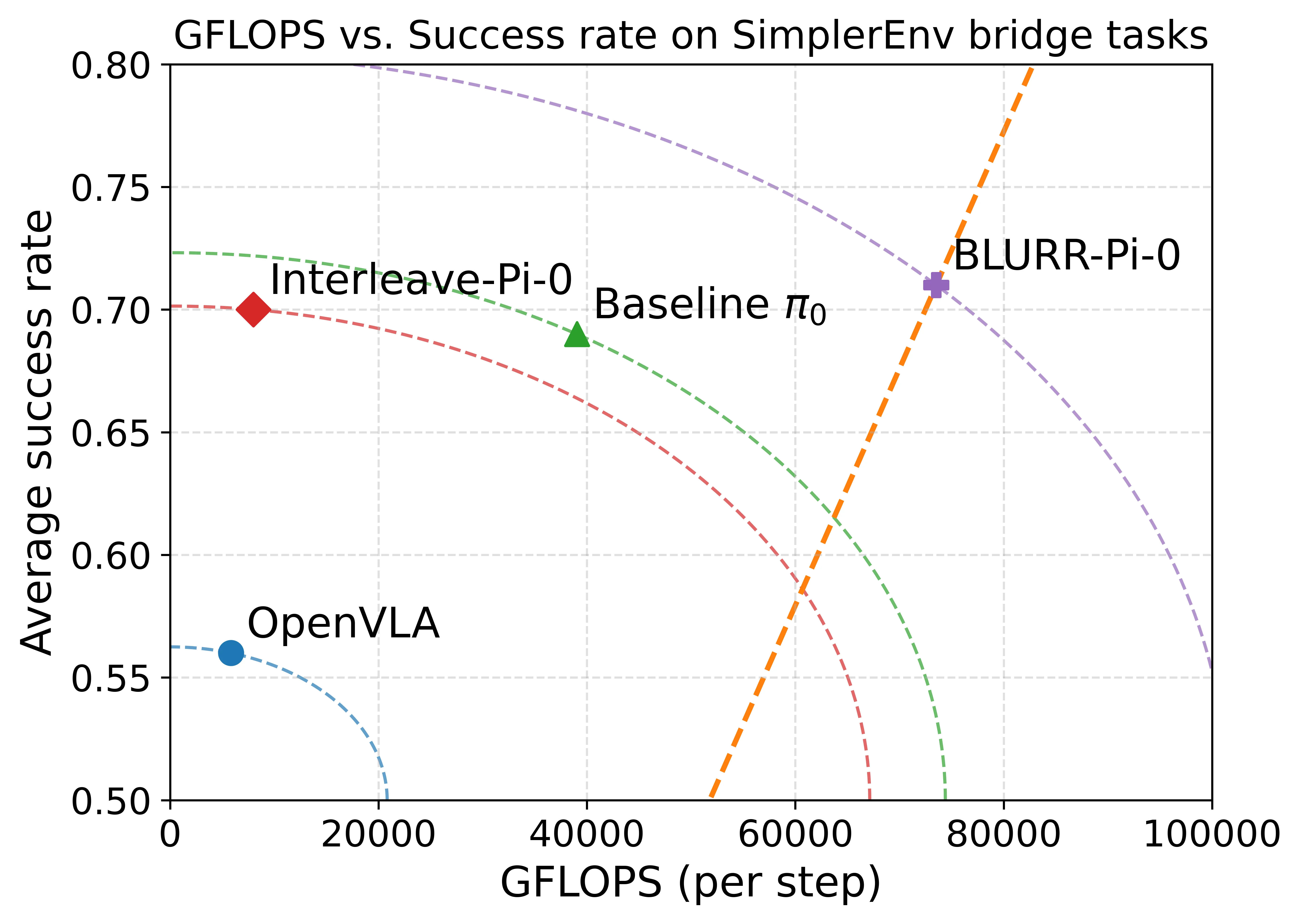
- 显著的效率提升:在 H100 GPU 上实现 9.5× 延迟降低、0.53× 峰值显存占用、9.2× 有效 GFLOPS 提升
- 保持任务性能:在 SimplerEnv 四项操作任务上,平均成功率 (0.71) 与基线相当甚至略优
- 交互式演示系统:提供实时网页演示,用户可切换控制器并调整推理选项,直观观察速度与精度的权衡
Card 04
方法描述
方法描述
- 指令前缀 KV 缓存:将语言指令编码为前缀 KV 缓存,每轮只处理一次,后续控制步骤仅注入新的视觉和本体感受 token
- 单步控制策略:将控制范围从 10 步缩减为 1 步,消除冗余推理,将时间平滑委托给环境和底层控制器
- BF16 高效解码器:解码器层采用 BF16 执行,减少约 2× 内存带宽需求,充分利用张量核心加速器
- 图编译优化:使用 torch.compile 包装完整前向传播,实现内核融合并消除 Python 开销
- FlashAttention 内核:通过 PyTorch SDPA 后端启用融合、IO 感知的注意力内核,显著减少内存 I/O
Card 05
数据集与资源
数据集与资源
- 数据集/环境:SimplerEnv 仿真环境,包含四项桥接操作任务(Carrot-on-plate、Eggplant-in-container、Spoon-on-plate、Stack-blocks)
- 基础模型:π₀ (Pi-0) 预训练检查点,基于 PaliGemma 风格多模态解码器和 SigLIP 视觉编码器
- 硬件资源:单张 NVIDIA H100 GPU 进行推理评测
- 输入配置:224×224 RGB 图像,256 token 预算
Card 06
评估与结果
评估与结果
- 评估基准:SimplerEnv 四项桥接操作任务,每项任务 100 轮闭环评估 episode
- 主要对比方法:OpenVLA、MiniVLA、Pi-0 baseline、Interleave-Pi-0(基线复现)、BLURR-Pi-0(本文方法)
- 关键性能指标:
- 延迟:从 Interleave-Pi-0 的 162.1 ms 降至 17.1 ms(约 58 Hz 控制频率)
- 显存占用:从 13.61 GB 降至 7.20 GB
- 有效 GFLOPS:从 7,989 提升至 73,525
- 任务成功率:BLURR-Pi-0 平均成功率 0.71,与 Interleave-Pi-0 (0.70) 和 Pi-0 baseline (0.69) 基本持平,在 Spoon (0.91) 和 Eggplant (0.93) 任务上达到最优