一眼看懂
封面预览
提出 TEAM-VLA (Token Expand-and-Merge-VLA),一种无需训练的token压缩框架,用于加速视觉-语言-动作(…
- 提出 TEAM-VLA (Token Expand-and-Merge-VLA),一种无需训练的token压缩框架,用于加速视觉-语言-动作(…
- 解决VLA模型参数量巨大(数十亿参数)、推理计算开销高、难以实时部署的问题
- 核心思想:通过动态token扩展和选择性合并,在保持任务性能的同时显著降低计算延迟
Card 01
研究单位
研究单位
- Hamad Bin Khalifa University (卡塔尔,科学与工程学院)
- Mohamed bin Zayed University of Artificial Intelligence (阿联酋)
- Zhejiang University (中国,计算机科学与技术学院)
Card 02
论文概述
论文概述
- 提出 TEAM-VLA (Token Expand-and-Merge-VLA),一种无需训练的token压缩框架,用于加速视觉-语言-动作(VLA)模型的推理
- 解决VLA模型参数量巨大(数十亿参数)、推理计算开销高、难以实时部署的问题
- 核心思想:通过动态token扩展和选择性合并,在保持任务性能的同时显著降低计算延迟
Card 03
核心贡献
核心贡献
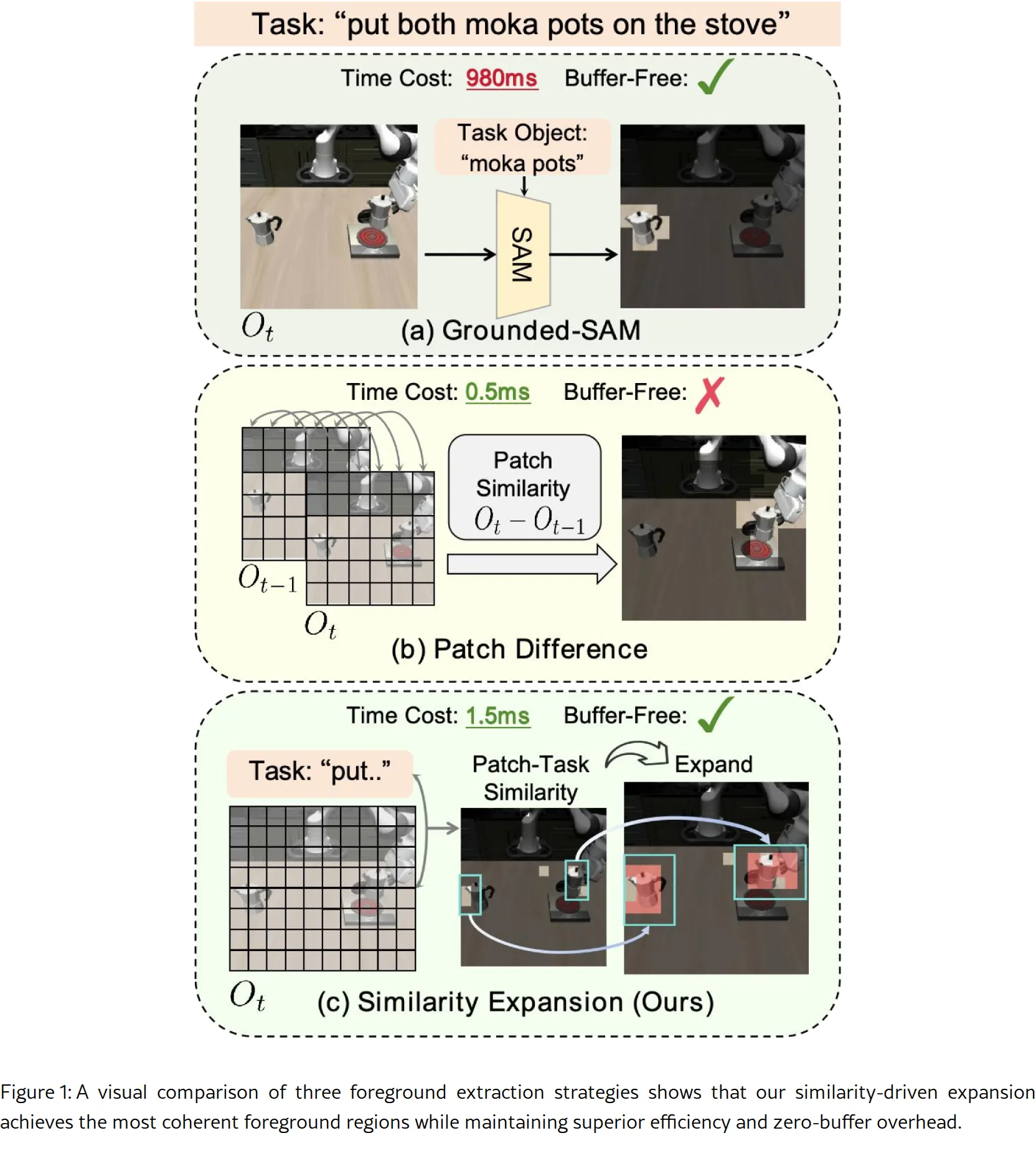
- 提出首个完全无需训练、无需历史帧缓冲、仅依赖当前观测的VLA token压缩框架
- 设计Token Expanding机制:从稀疏的vision-language相似性信号中重建密集的前景区域,增强上下文完整性
- 设计Action-Guided Token Merging机制:在深层网络中基于动作感知引导进行软二分图合并,保留关键语义信息
- 在LIBERO基准上实现1.5倍加速,同时保持与完整模型相当甚至更高的任务成功率
Card 04
方法描述
方法描述
- 两阶段压缩策略:(1) 早期剪枝——在输入LLM主干前进行;(2) 中层合并——在LLM中间层进行
- Token Expanding:计算图像token与语言token的余弦相似度,通过卷积密度估计和区域扩展(确定性扩展+随机扩展)重建完整前景
- Context Sampling:随机采样少量背景token保持空间感知
- Task-Guided Bipartite Merging:基于与动作token的相似度选择top-M源token,通过软匹配将目标token加权聚合到源token
- 关键创新:扩展与合并耦合在单次前向传播中完成,无需重新训练
Card 05
数据集与资源
数据集与资源
- 数据集:LIBERO基准,包含四个子集:LIBERO-Spatial、LIBERO-Object、LIBERO-Goal、LIBERO-Long
- 基础模型:基于 OpenVLA-OFT 实现,使用 LightVLA 代码库
- 实验平台:单张 NVIDIA A100-40GB GPU
- 模型规模:7B参数级别的VLA模型
Card 06
评估与结果
评估与结果
- 评估指标:成功率(SR)、FLOPs、CUDA延迟(ms)
- 主要结果:
- 将OpenVLA-OFT的推理时间从109ms降至72.1ms,实现1.5倍加速
- 平均成功率96.6%,与原始模型持平
- FLOPs降低至39%,显著优于VLA-Cache(83%)、SpecPrune-VLA(43%)等方法
- 在LIBERO-Spatial上达到99.2%成功率,LIBERO-Object上96.5%
- 关键发现:
- 合并策略在深层(Layer 16)效果最佳,成功率93.8% vs 剪枝的92.1%
- 最优参数:扩展阈值τ=1,上下文采样率u∈[0.1,0.35],合并token数M∈[50,130]
- 相比其他无需训练方法,TEAM-VLA保留的token数显著更少(平均432个),性能却更优