一眼看懂
封面预览
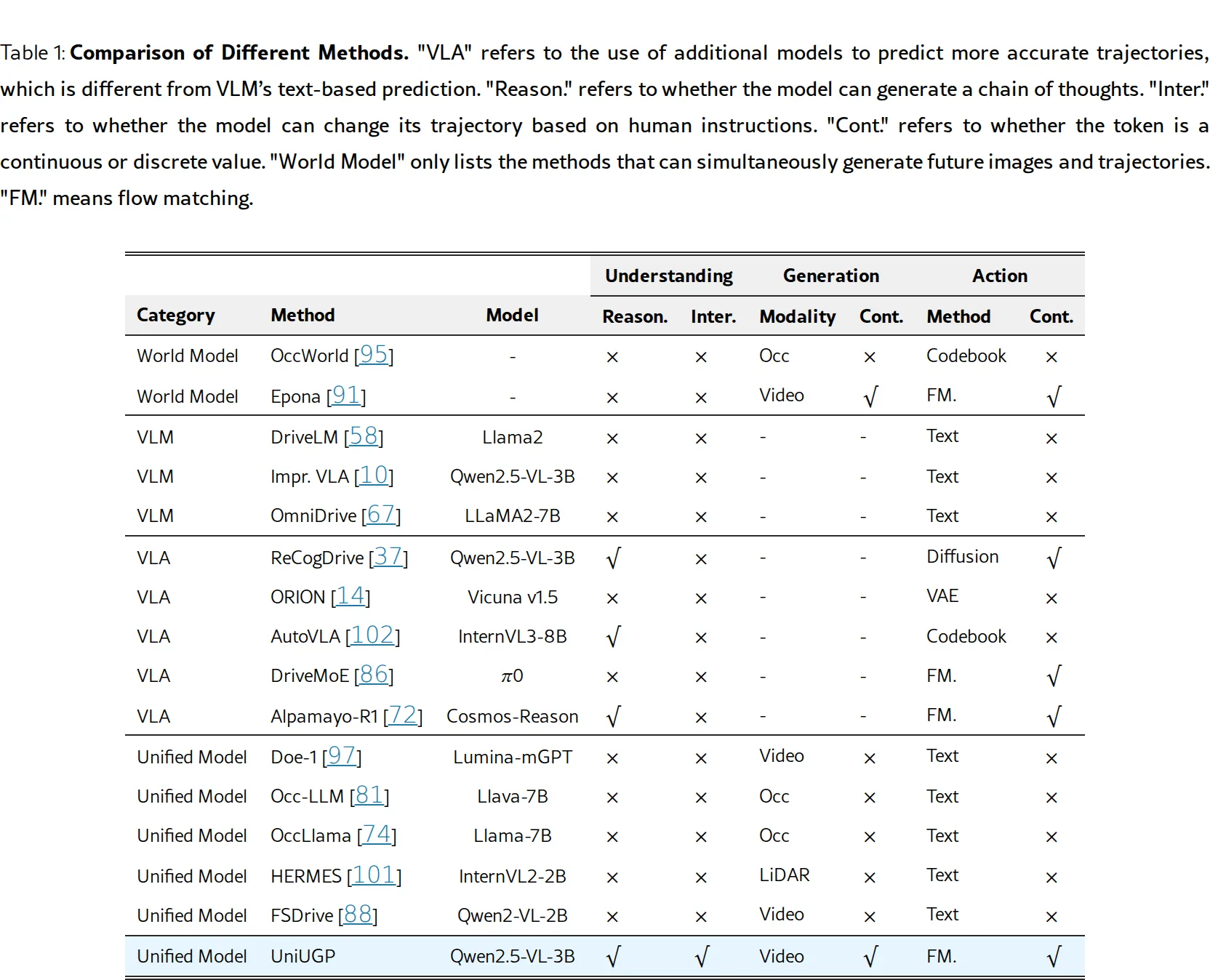
提出 UniUGP 统一框架,将场景理解、未来视频生成和轨迹规划三大能力整合到端到端自动驾驶系统中
- 提出 UniUGP 统一框架,将场景理解、未来视频生成和轨迹规划三大能力整合到端到端自动驾驶系统中
- 解决现有 VLA 方法无法利用无标签视频进行视觉因果学习、世界模型缺乏大语言模型推理能力的局限性
- 针对长尾场景(罕见但关键的驾驶情况)提升自动驾驶系统的泛化能力和安全性
Card 01
研究单位
研究单位
- ByteDance Seed
Card 02
论文概述
论文概述
- 提出 UniUGP 统一框架,将场景理解、未来视频生成和轨迹规划三大能力整合到端到端自动驾驶系统中
- 解决现有 VLA 方法无法利用无标签视频进行视觉因果学习、世界模型缺乏大语言模型推理能力的局限性
- 针对长尾场景(罕见但关键的驾驶情况)提升自动驾驶系统的泛化能力和安全性
Card 03
核心贡献
核心贡献
- 构建了多个专门的自动驾驶数据集,为复杂场景提供解释、推理和规划标注
- 提出基于混合专家架构的 UniUGP 统一理解-生成-规划框架,协同场景推理、未来视频生成和轨迹规划
- 设计四阶段训练策略,逐步建立基础场景理解、视觉动态建模、文本推理和多能力融合
- 整合预训练 VLM(Qwen2.5-VL)和视频生成模型(Wan2.1)的知识优势
- 实现可解释的链式思维推理、物理一致的轨迹预测和连贯的未来视频生成
Card 04
方法描述
方法描述
- 混合专家架构:包含理解专家(基于 Qwen2.5-VL-3B)、规划专家(流匹配生成连续轨迹)和生成专家(基于 Wan2.1 的未来视频生成)
- Mixture-of-Transformers (MoT):理解专家和规划专家共享注意力机制但使用独立的前馈网络
- 流匹配(Flow Matching):用于连续轨迹规划和视频生成,支持可微分优化
- 四阶段训练:阶段1(理解专家连续训练)→ 阶段2(视觉动态建模与规划训练)→ 阶段3(文本推理学习)→ 阶段4(混合训练实现多能力融合)
Card 05
数据集与资源
数据集与资源
- 训练数据集:自定义长尾数据集、ImpromptuVLA、nuScenes、NuPlan、Waymo、Lyft、Cosmos
- 评估数据集:DADA2000、Lost and Found (LaF)、StreetHazards (StHa)、SOM、AADV、Waymo-E2E、DriveLM
- 模型规模:基于 Qwen2.5-VL-3B 骨干网络
- 训练资源:每阶段 8 节点 × 8 GPU(80GB),共 64 张 GPU
- 训练步数:阶段1(1M)、阶段2(4M)、阶段3(1M)、阶段4(4M)
Card 06
评估与结果
评估与结果
- 理解能力评估:在长尾场景理解基准上,Small 物体识别达 89.3%、事故主体关系 88.6%、异常预测 95.8%,超越 GPT-4o 和 Qwen-2.5-VL-72B
- 规划能力评估:在 nuScenes 上,仅使用前相机输入时平均 L2 误差 1.23m,碰撞率 0.33%,优于 Doe-1、Epona 等方法
- 生成能力评估:未来帧生成质量在 FID 指标上显著优于 DriveDreamer、Drive-WM、GenAD 等基线方法
- 指令跟随能力:L2 (3s) 误差 1.40,支持自然语言交互调整轨迹