一眼看懂
封面预览
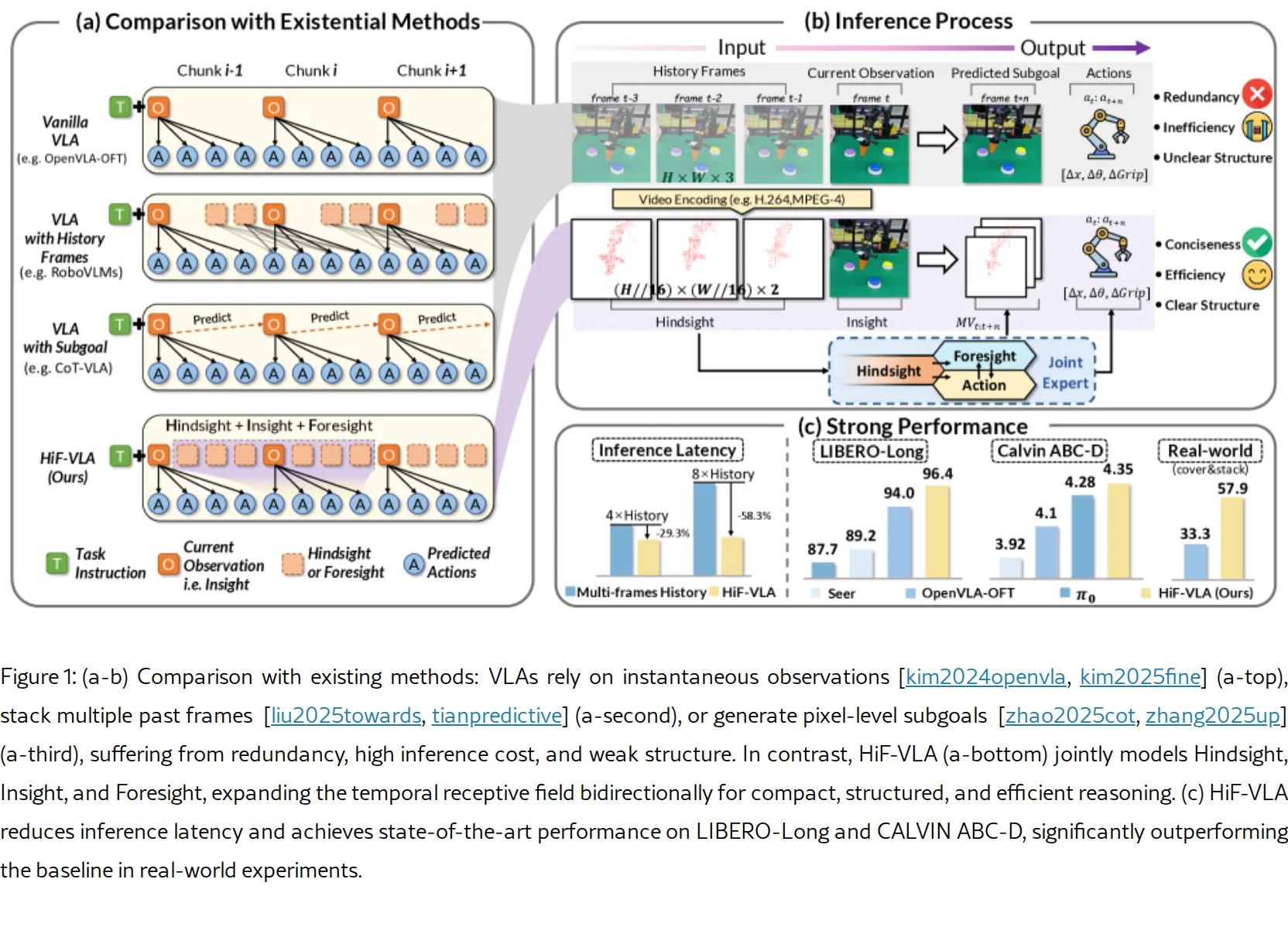
论文提出 HiF-VLA(Hindsight, Insight and Foresight for Vision-Language-Actio…
- 论文提出 HiF-VLA(Hindsight, Insight and Foresight for Vision-Language-Actio…
- 通过将运动视为紧凑且信息丰富的时间上下文表示,HiF-VLA 实现了对过去动态的后见之明(hindsight)、对当前状态的洞察(insigh…
- 提出 HiF-VLA 框架,通过低维运动向量作为结构化时间基元,显式扩展时间感受野,实现时间一致且高效的动作预测
Card 01
研究单位
研究单位
- Westlake University(西湖大学)
- Zhejiang University(浙江大学)
- HKUST(GZ)(香港科技大学广州校区)
- Nanjing University(南京大学)
- Westlake Robotics(西湖机器人)
Card 02
论文概述
论文概述
- 论文提出 HiF-VLA(Hindsight, Insight and Foresight for Vision-Language-Action Models),一个利用运动表示进行双向时间推理的统一框架,解决现有 VLA 模型因马尔可夫假设导致的时间近视(temporal myopia)问题
- 通过将运动视为紧凑且信息丰富的时间上下文表示,HiF-VLA 实现了对过去动态的后见之明(hindsight)、对当前状态的洞察(insight)和对未来运动的预见(foresight),从而支持"边思考边行动(think-while-acting)"的长程操作范式
Card 03
核心贡献
核心贡献
- 提出 HiF-VLA 框架,通过低维运动向量作为结构化时间基元,显式扩展时间感受野,实现时间一致且高效的动作预测
- 提出后见调制联合专家(hindsight-modulated joint expert),在统一空间内融合时间和动作表示,实现因果一致的长程运动生成
- 在 LIBERO-Long 和 CALVIN ABC-D 基准测试上达到 SOTA 性能,同时具有可忽略的额外推理延迟
- 在真实世界长程操作任务中取得显著提升,验证了实际机器人环境中的广泛有效性
Card 04
方法描述
方法描述
- 后见先验获取(Hindsight Prior Acquisition):使用 MPEG-4 标准提取运动向量(Motion Vectors, MVs),将历史帧序列编码为紧凑的后见令牌,避免像素级冗余
- 预见推理与洞察(Foresight Reasoning with Insight):引入可学习的预见查询令牌和动作令牌,通过 VLM 并行推理未来运动和潜在动作
- 后见调制联合专家(Hindsight-Modulated Joint Expert):采用 AdaLN(Adaptive Layer Normalization) 将后见信息作为条件注入,通过交叉流联合注意力机制融合预见运动和动作表示
- 训练目标结合动作预测损失和运动重建损失,平衡因子 λ = 0.01
Card 05
数据集与资源
数据集与资源
- 数据集:LIBERO-Long(10 个多子目标操作任务)、CALVIN ABC-D(4 个室内环境,A-C 训练,D 测试)、真实世界自定义任务(AgileX Piper 机器人,3 个长程任务,各 100 次演示)
- 模型规模:基于 Prismatic-7B VLM 主干,使用 DINOv2 和 SigLIP 视觉编码器
- 训练资源:8 张 NVIDIA A100 GPU,全局 batch size 64
- 训练设置:LIBERO 微调 150k 步,CALVIN 微调 80k 步,动作和预见时间窗口 n=8,后见窗口默认 h=8
Card 06
评估与结果
评估与结果
- LIBERO-Long:第三视角设置下平均成功率 94.4%(比基线提升 3.4%),多视角设置下达 96.4%
- CALVIN ABC-D:平均任务完成长度达 4.35(第三视角 4.08),超越基线 OpenVLA-OFT 的 4.10 和 VPP 的 4.33
- 效率分析:相比帧堆叠基线(延迟 229.5ms,3.15×),HiF-VLA 后见+预见仅增加 1.67× 延迟(121.6ms),GPU 内存仅 1.05×(32.2GB vs 30.8GB)
- 推理可扩展性:随着历史长度增加,基线延迟线性增长(8 帧时 4.5×),而 HiF-VLA 保持几乎恒定低延迟
- 真实世界实验:在 Press-Buttons-Order 等长程任务上显著优于基线(基线 17.4% vs HiF-VLA 大幅提升),验证了时间一致性检测能力