一眼看懂
封面预览
提出了一种名为 HiMoE-VLA 的新型视觉-语言-动作(VLA)框架,旨在从大规模、高度异质的机器人数据中学习通用策略。
- 提出了一种名为 HiMoE-VLA 的新型视觉-语言-动作(VLA)框架,旨在从大规模、高度异质的机器人数据中学习通用策略。
- 核心问题是解决机器人数据固有的异质性挑战,例如不同的动作空间(关节空间 vs. 末端执行器空间)、机器人本体、传感器配置和控制频率等,这些因素…
- 提出了一种新颖的分层专家混合(Hierarchical Mixture-of-Experts, HiMoE)架构,用于动作模块,以显式地处理数…
Card 01
研究单位
研究单位
- 复旦大学
- 微软亚洲研究院 (Microsoft Research Asia)
- 西安交通大学
- 清华大学
Card 02
论文概述
论文概述
- 提出了一种名为 HiMoE-VLA 的新型视觉-语言-动作(VLA)框架,旨在从大规模、高度异质的机器人数据中学习通用策略。
- 核心问题是解决机器人数据固有的异质性挑战,例如不同的动作空间(关节空间 vs. 末端执行器空间)、机器人本体、传感器配置和控制频率等,这些因素使得现有模型难以有效整合数据并进行泛化。
Card 03
核心贡献
核心贡献
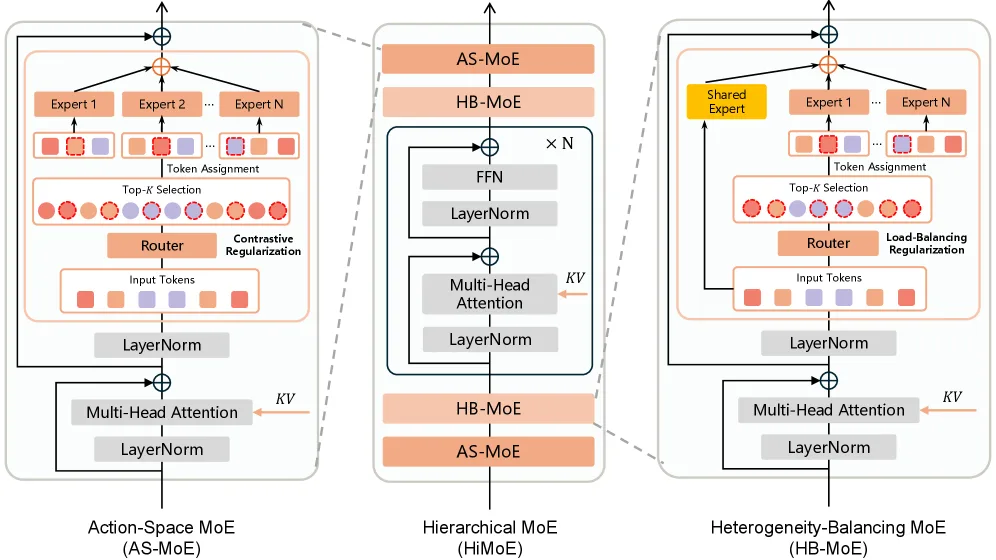
- 提出了一种新颖的分层专家混合(Hierarchical Mixture-of-Experts, HiMoE)架构,用于动作模块,以显式地处理数据异质性。
- 设计了两种互补的MoE模块:位于浅层的动作空间专家(AS-MoE) 专门处理不同动作空间之间的差异;位于相邻层的异质性平衡专家(HB-MoE) 负责整合更广泛的异质来源(如机器人本体和传感器差异)。
- 引入了两种目标正则化:动作空间正则化(AS-Reg) 增强AS-MoE专家的专业化;异质性平衡正则化(HB-Reg) 促进HB-MoE的均衡知识抽象,二者结合流匹配(flow-matching)损失共同优化模型。
- 在仿真(CALVIN, LIBERO)和真实世界(xArm7单臂和ALOHA双臂机器人)基准测试上,HiMoE-VLA实现了最先进的性能,在成功率、长任务序列执行和泛化能力(到未见过的物体和场景)方面均超越了现有VLA基线模型。
Card 04
方法描述
方法描述
- 模型架构:包含一个预训练的视觉-语言骨干模型(PaliGemma)和一个带有分层MoE的专用动作专家模块。
- 创新技术:
- 分层MoE设计:在浅层使用AS-MoE捕捉动作空间的精细差异,在相邻层使用HB-MoE抽象更广泛的异质性,中间穿插标准的Transformer块以整合为共享知识表示。
- 正则化技术:使用AS-Reg(对比损失)促使AS-MoE中的专家针对不同动作空间进行专业化;使用HB-Reg(路由平衡损失)确保HB-MoE中专家负载均衡,促进知识的有效整合。
- 训练目标:采用流匹配损失来建模多模态的动作分布,生成平滑、连续的动作序列。
Card 05
数据集与资源
数据集与资源
- 主要数据集:结合了Open X-Embodiment (OXE) 数据集(22.5M帧)和公开的ALOHA数据集(1.6M帧),总计约24.1M帧的机器人演示数据。
- 模型规模与参数量:HiMoE-VLA 总参数量为 4B。
- 训练资源:在 16 块 NVIDIA A100 GPU上使用DeepSpeed优化进行端到端训练。
Card 06
评估与结果
评估与结果
- 评估环境:在仿真基准(CALVIN, LIBERO)和真实机器人平台(xArm7, ALOHA)上进行了广泛评估和消融实验。
- 主要评估指标:任务成功率、连续完成任务的平均数量(CALVIN)、以及对于多阶段任务的分阶段成功率。
- 关键实验结果:
- 在CALVIN的 D→D 设置中,模型连续完成1-5个任务的总分达到 3.967,超越所有基线模型。
- 在LIBERO的四个任务套件(Spatial, Object, Goal, Long)上,平均成功率高达 97.8%,达到新的SOTA。
- 在真实世界xArm7上的三个任务平均成功率 75.0%,显著优于π₀等基线。
- 在真实世界ALOHA双臂机器人任务上的平均成功率为 63.7%,同样优于所有基线。
- 泛化测试表明,模型在面对未见过的干扰物和新物体时,仍能保持稳健的性能,优于基线。