一眼看懂
封面预览
本文提出了一种新颖的微调框架 StARe-VLA,旨在解决对 视觉-语言-动作 (VLA) 模型进行长时程轨迹级微调时的 信用分配 困难和训练…
- 本文提出了一种新颖的微调框架 StARe-VLA,旨在解决对 视觉-语言-动作 (VLA) 模型进行长时程轨迹级微调时的 信用分配 困难和训练…
- 核心思想是将机器人操作的长时程动作轨迹,按照其语义分解为因果链式、难度不同的阶段(如Reach→Grasp→Transport→Place)…
- 论文要解决的问题是:直接应用轨迹级偏好优化(如TPO)或强化学习(如PPO)来微调VLA模型时,由于优化空间大、奖励稀疏,导致梯度信号模糊、训…
Card 01
研究单位
研究单位
- 华为技术有限公司慕尼黑研究院 (Munich Research Center, Huawei Technologies)
- 帝国理工学院 (Imperial College London)
Card 02
论文概述
论文概述
- 本文提出了一种新颖的微调框架 StARe-VLA,旨在解决对 视觉-语言-动作 (VLA) 模型进行长时程轨迹级微调时的 信用分配 困难和训练不稳定问题。
- 核心思想是将机器人操作的长时程动作轨迹,按照其语义分解为因果链式、难度不同的阶段(如Reach→Grasp→Transport→Place),并进行阶段感知的渐进式优化,而非整体轨迹优化。
- 论文要解决的问题是:直接应用轨迹级偏好优化(如TPO)或强化学习(如PPO)来微调VLA模型时,由于优化空间大、奖励稀疏,导致梯度信号模糊、训练效率低。
Card 03
核心贡献
核心贡献
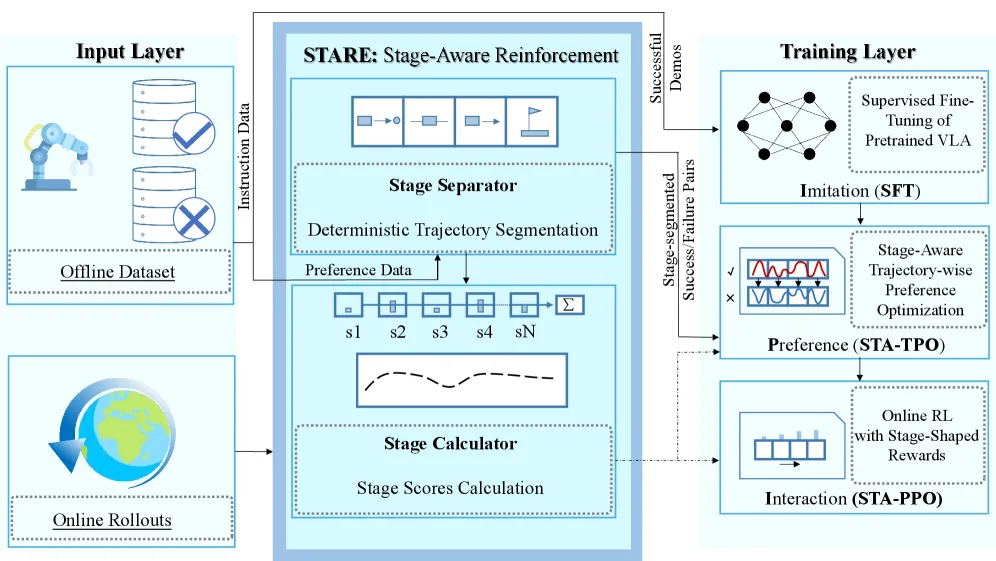
- 提出了 Stage-Aware Reinforcement (StARe),一个基于规则的模块,用于将长时程动作轨迹分解为语义上有意义的阶段,并提供密集的、可解释的阶段对齐强化信号。
- 基于 StARe 模块,提出了两种阶段感知微调方法:用于离线阶段偏好对齐的 Stage-Aware TPO (StA-TPO) 和用于在线阶段内交互的 Stage-Aware PPO (StA-PPO),以提供更精确的信用分配。
- 提出了一个序列化的三阶段微调流程 Imitation → Preference → Interaction (IPI),整合了监督微调(SFT)、StA-TPO 和 StA-PPO,以实现VLA模型的充分微调。
- 在 SimplerEnv 和 ManiSkill3 两个机器人操作基准测试中进行了广泛的实验,验证了所提方法的有效性,并取得了最先进的成功率。
Card 04
方法描述
方法描述
- 核心技术是 StARe 模块,包含阶段分离器(基于末端执行器位姿的事件规则判断阶段转换时机)和阶段计算器(计算阶段成本和基于势函数的密集奖励)。
- 将 StARe 集成到TPO中,得到 StA-TPO:在阶段层面构建成对偏好,并引入阶段成本作为惩罚项,实现阶段级的偏好对齐。
- 将 StARe 集成到PPO中,得到 StA-PPO:在在线交互过程中提供密集的阶段内奖励塑形,替代稀疏的终端奖励,稳定并加速训练。
- IPI 训练流程:首先使用专家演示进行 SFT,然后使用 StA-TPO 进行离线阶段偏好优化,最后使用 StA-PPO 进行在线交互式强化学习微调。
Card 05
数据集与资源
数据集与资源
- 主要使用 SimplerEnv 和 ManiSkill3 两个机器人仿真环境中的任务进行评估。
- 在 SimplerEnv-WidowX 中评估了四个单物体操作任务:放置勺子、胡萝卜、堆叠方块、放置茄子。
- 在 ManiSkill3-Franka 中评估了 StackCube 和三个接触丰富的任务:PushCube, PullCube, LiftPegUpright。
- 模型基于预训练的 OpenVLA-7B 和 pi0.5_base VLA模型进行微调。
Card 06
评估与结果
评估与结果
- 评估基准:在 SimplerEnv 和 ManiSkill3 环境下,对比了多种基线方法(如RT-1-X, Octo, RoboVLM, SpatialVLA, GRAPE, RL4VLA)。
- 主要评估指标:任务成功率(平均超过300个评估回合),并在部分任务中额外报告抓取成功率。
- 关键实验结果:
- 在 SimplerEnv 上,完整的 IPI 流程达到了 98.0% 的平均成功率,显著优于所有基线(包括SFT、GRAPE等)。
- 在 ManiSkill3 上,IPI 实现了 96.4% 的平均成功率,展示了其在更复杂、接触丰富的任务上的泛化能力。
- 消融实验证明了 StA-PPO 相较于标准PPO能提供更稳定的训练和更快的收敛速度。