一眼看懂
封面预览
提出了一种可解释且对抗鲁棒的视觉-语言-动作模型,用于智能农业场景中的机器人操作任务。
- 提出了一种可解释且对抗鲁棒的视觉-语言-动作模型,用于智能农业场景中的机器人操作任务。
- 旨在解决智能农业系统中,RGB摄像头和机器人机械臂在面对色调、光照和噪声等光度扰动(对抗性攻击)时容易失效的问题。
- 通过在现有VLA模型中集成一个对抗攻击检测与解释模块,提升模型的鲁棒性与可解释性。
Card 01
研究单位
研究单位
- Department of Computer Science and Engineering, Gyeongsang National University
- Department of AI Convergence Engineering, Gyeongsang National University
Card 02
论文概述
论文概述
- 提出了一种可解释且对抗鲁棒的视觉-语言-动作模型,用于智能农业场景中的机器人操作任务。
- 旨在解决智能农业系统中,RGB摄像头和机器人机械臂在面对色调、光照和噪声等光度扰动(对抗性攻击)时容易失效的问题。
- 通过在现有VLA模型中集成一个对抗攻击检测与解释模块,提升模型的鲁棒性与可解释性。
Card 03
核心贡献
核心贡献
- 提出了一个基于OpenVLA-OFT框架的可解释对抗鲁棒视觉-语言-动作模型。
- 设计并集成了一个名为 Evidence-3 的模块,用于检测光度扰动并以自然语言解释其成因和影响。
- 提出了一种联合训练策略,同时优化动作预测损失和可解释性损失,使模型在对抗条件下更准确、更可解释。
- 在模拟环境中生成了包含随机光度变换的对抗性数据集,用于模型训练和评估。
- 实验表明,该模型在对抗条件下显著提升了动作预测精度,并实现了极高的解释准确性。
Card 04
方法描述
方法描述
- 该方法在 OpenVLA-OFT 框架基础上进行扩展。Evidence-3模块 使用三种统计度量(HSV马氏距离、高频能量比、局部熵标准差)来检测图像中的异常。
- 检测到的统计线索被嵌入到用户指令中,作为额外输入提供给基于 Llama2 的主干模型。
- 模型包含两个输出头:一个用于预测当前和后续机器人动作(最小化L1损失),另一个用于生成描述对抗攻击的XAI令牌(最小化交叉熵损失)。
- 关键创新在于将对抗检测统计量与语言指令融合,并通过多任务损失函数联合训练,同时优化动作预测和解释生成。
Card 05
数据集与资源
数据集与资源
- 使用 Franka Emika Panda 机械臂和RGB相机在 Isaac Sim 仿真环境中收集数据。
- 通过应用随机光度变换(色调偏移、光照调整、噪声注入)生成对抗性变体,构建训练数据集。
- 模型基于 OpenVLA-OFT 和 Llama2 主干。论文未明确提及模型的具体参数量和训练所使用的硬件资源。
Card 06
评估与结果
评估与结果
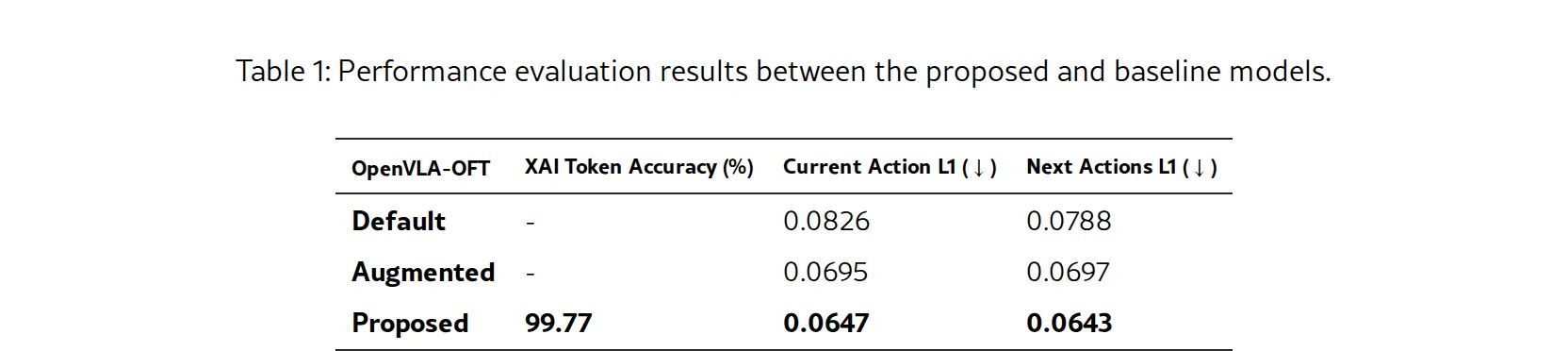
- 评估基准:与基线模型(Default)和仅使用数据增强的对抗训练模型(Augmented)进行比较。
- 主要评估指标:XAI令牌准确率、当前动作L1损失、后续动作L1损失(均越低越好)。
- 关键实验结果:所提出的模型在XAI令牌准确率上达到 99.77%。与基线模型相比,当前动作L1损失降低了21.7%(从0.0826降至0.0647),后续动作L1损失降低了18.4%(从0.0788降至0.0643),同时性能也优于仅使用数据增强的模型。