一眼看懂
封面预览
提出 FASTer 框架,旨在解决自回归视觉语言动作模型在动作标记化和推理效率上面临的权衡问题。
- 提出 FASTer 框架,旨在解决自回归视觉语言动作模型在动作标记化和推理效率上面临的权衡问题。
- 通过引入一个可学习的神经动作标记器 (FASTerVQ) 和一个构建在其上的自回归策略 (FASTerVLA),实现高效、通用的机器人学习。
- 提出 FASTerVQ:一个紧凑、高压缩率的动作标记器,结合了基于Transformer的残差向量量化和轻量级混合机制,将动作序列联合压缩到统…
Card 01
研究单位
研究单位
- 清华大学
- 复旦大学
- 上海创新研究院
- Galaxea AI
- 天津大学
- 香港大学
- 加州大学圣地亚哥分校 (UCSD)
Card 02
论文概述
论文概述
- 提出 FASTer 框架,旨在解决自回归视觉语言动作模型在动作标记化和推理效率上面临的权衡问题。
- 通过引入一个可学习的神经动作标记器 (FASTerVQ) 和一个构建在其上的自回归策略 (FASTerVLA),实现高效、通用的机器人学习。
Card 03
核心贡献
核心贡献
- 提出 FASTerVQ:一个紧凑、高压缩率的动作标记器,结合了基于Transformer的残差向量量化和轻量级混合机制,将动作序列联合压缩到统一的离散码本中。
- 提出 FASTerVLA:引入了块级自回归解码以实现高效的动作令牌建模,并配备了与VLM骨干对齐的共享结构化动作专家,从而实现更快的推理和更高的准确性。
- 在涵盖四个真实机器人和四个模拟环境的全面基准测试中进行了广泛实验,为VLA的动作标记化提供了首次系统性分析,并展示了SOTA性能。
Card 04
方法描述
方法描述
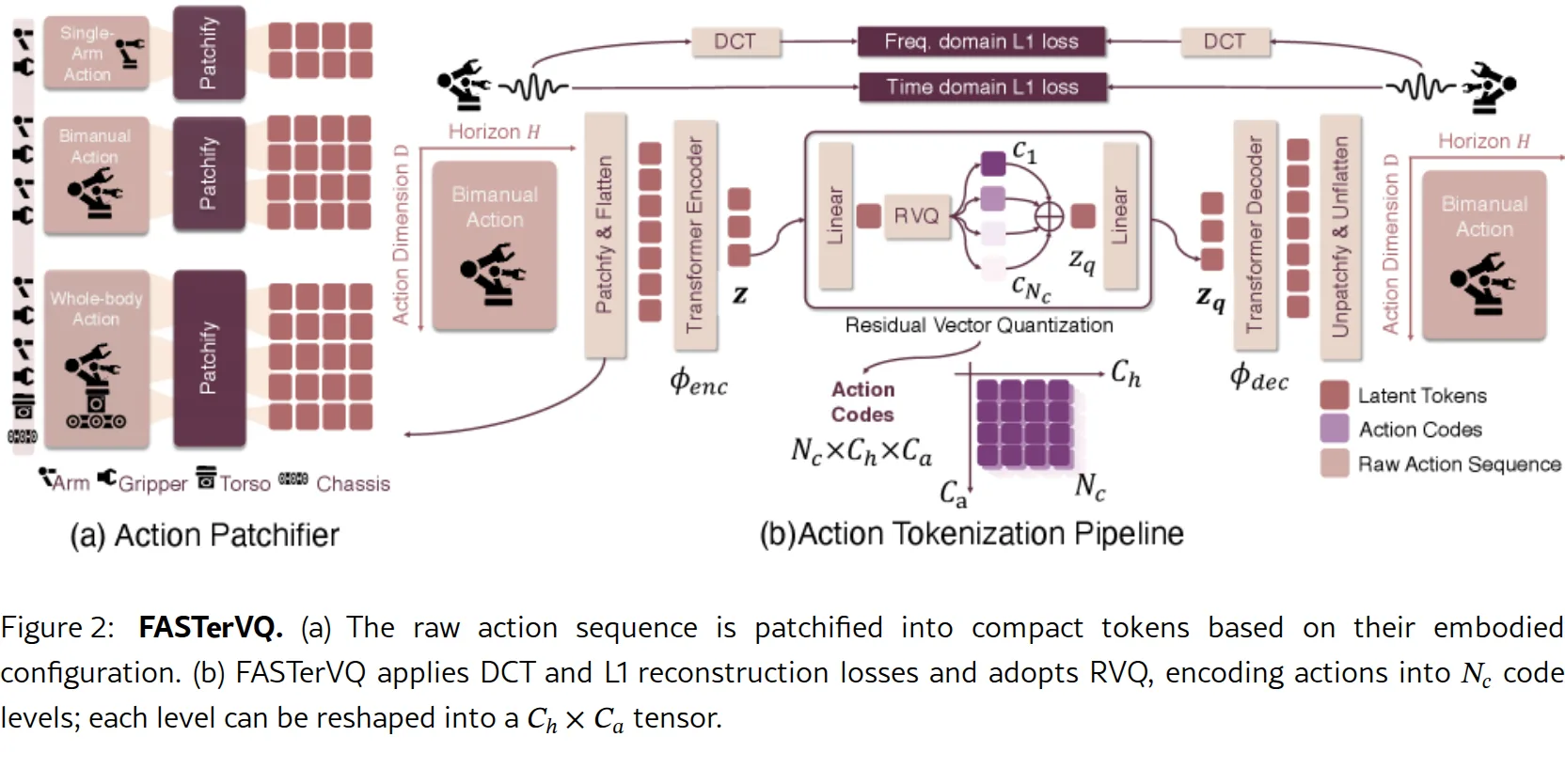
- FASTerVQ:首先通过动作分块器对动作序列进行非均匀分组,然后通过残差向量量化(RVQ)标记器提取潜在表示并进行量化。该设计结合了时域和频域(DCT)重建损失,实现了高保真重建和高压缩比。
- FASTerVLA:基于 FASTerVQ,采用块级自回归解码和轻量级动作专家。块级解码通过块内并行预测减少了自回归步骤,而动作专家则在保持参数高效的同时,桥接了语言推理与连续控制之间的模态差距。
Card 05
数据集与资源
数据集与资源
- 使用的数据集包括:LIBERO、Simpler-Bridge、BridgeData、DROID、VLABench、Galaxea Open Dataset、Kuka、Fractal等。
- 模型规模:FASTerVQ 模型参数量约为 8M (单臂) 至 13M (全身控制)。
- 训练资源:在 8× H100 GPUs 上训练模型,推理测试在 RTX 5090 GPU上进行。
Card 06
评估与结果
评估与结果
- 评估环境:在模拟环境(LIBERO, Simpler-Bridge, VLABench, GalaxeaManipSim)和真实机器人(XArm, R1Lite, WidowX, Franka)上进行评估。
- 主要评估指标:任务成功率、有效重建率(VRR)、推理延迟、代码利用率。
- 关键实验结果:
- 在 LIBERO 基准测试中达到 97.9% 的平均成功率,创造了新的 SOTA。
- 在 Simpler-Bridge 基准测试中达到 87.9% 的成功率,优于次优模型 12.9%。
- FASTerVLA 的推理速度比 π₀-FAST 快 3倍,在复杂任务(如全身控制)中优势更明显。
- FASTerVQ 显示出卓越的跨任务、跨具身和跨动作类型的泛化能力,且重建质量随着数据规模扩大而提升。