一眼看懂
封面预览
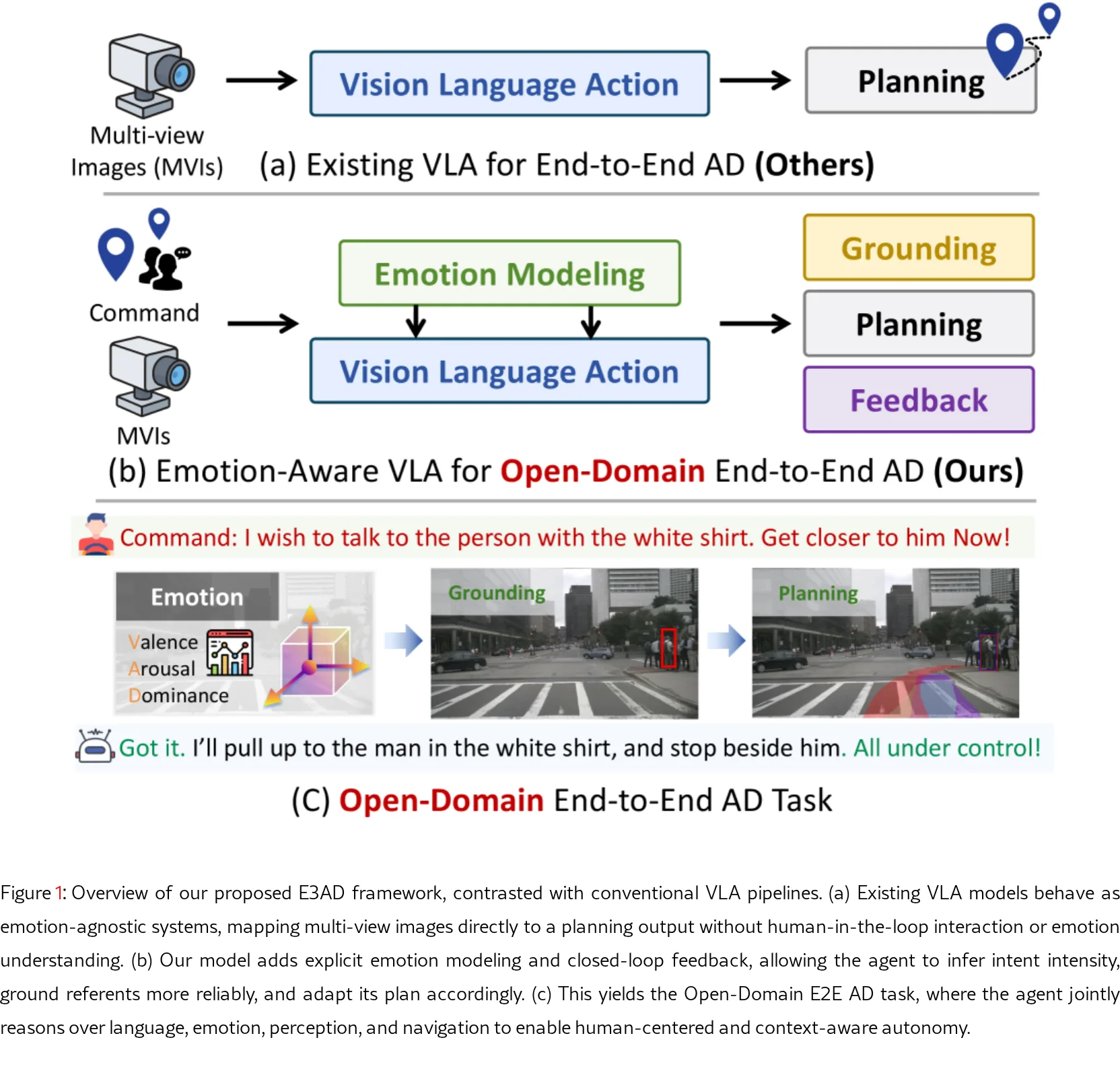
提出 Open-Domain End-to-End (OD-E2E) 自动驾驶新任务,要求自动驾驶车辆能够理解自由形式的自然语言指令,推断乘客…
- 提出 Open-Domain End-to-End (OD-E2E) 自动驾驶新任务,要求自动驾驶车辆能够理解自由形式的自然语言指令,推断乘客…
- 现有端到端视觉-语言-动作模型通常忽视乘客的情感状态,这构成了技术系统与人类信任和舒适度之间的“情感鸿沟”。
- 论文旨在解决如何使自动驾驶系统不仅理解指令的“内容”,还能感知指令的“表达方式”(情绪和紧迫感),从而生成更符合人类期望的、以人为本的驾驶行为。
Card 01
研究单位
研究单位
- McGill University
- University of Macau
- The Hong Kong Polytechnic University
- Massachusetts Institute of Technology (MIT)
- University of Washington
Card 02
论文概述
论文概述
- 提出 Open-Domain End-to-End (OD-E2E) 自动驾驶新任务,要求自动驾驶车辆能够理解自由形式的自然语言指令,推断乘客情绪,并规划物理可行的轨迹。
- 现有端到端视觉-语言-动作模型通常忽视乘客的情感状态,这构成了技术系统与人类信任和舒适度之间的“情感鸿沟”。
- 论文旨在解决如何使自动驾驶系统不仅理解指令的“内容”,还能感知指令的“表达方式”(情绪和紧迫感),从而生成更符合人类期望的、以人为本的驾驶行为。
Card 03
核心贡献
核心贡献
- 定义了 OD-E2E 这一新的以人为本的自动驾驶任务,统一了语义、情感和空间推理。
- 提出了 E3AD 情感感知的视觉-语言-动作框架,将连续的 Valence-Arousal-Dominance 情感建模与受认知启发的 双路径空间推理模块 集成到一个统一的端到端流程中。
- 设计了一种一致性导向的三阶段训练策略(模态预训练、联合微调、情感-动作对齐),通过偏好优化确保情感意图与驾驶行为之间的一致性。
- 在多个真实世界数据集上验证了 E3AD 在视觉定位、情感估计和路径点规划方面均优于现有先进方法,尤其在情感敏感和角点场景中表现出显著优势。
- 提供了以人为本的言语反馈,根据情绪状态调整交互,以缓解乘客的“黑箱”焦虑,增强系统透明度和信任度。
Card 04
方法描述
方法描述
- 框架基于 Qwen2.5-VL-7B-Instruct 模型构建。
- 情感建模:将自然语言指令映射到连续的Valence-Arousal-Dominance 空间,以捕捉语调和紧迫感。通过指令微调和情感感知指令增强技术进行训练,以区分意图与情感。
- 空间推理:采用双系统设计,融合自我中心视图(用于动作导向的即时感知)和异我中心视图(用于基于地图的全局结构),模拟人类空间认知。
- 动作解码与反馈:在VLA骨干网络后接一个轻量级动作解码器,生成精确的轨迹。同时,模型会根据预测的情绪状态、定位目标和规划轨迹,生成自适应的人类中心言语反馈。
- 训练策略:采用三阶段一致性训练:1) 模态预训练(情感和空间);2) 联合微调,将情感、定位和轨迹规划整合到单一自回归生成链中;3) 情感-动作对齐,利用DPO 算法和伪偏好数据对,强化情绪与行为的一致性。
Card 05
数据集与资源
数据集与资源
- 使用多个自动驾驶数据集进行评估,包括 Talk2Car、DrivePilot、MoCAD 和 Talk2Car-Trajectory。还引入了 Long-Text 和 Corner-Case 子集来测试鲁棒性。
- 模型规模和参数量:基础模型为 Qwen2.5-VL-7B。训练时冻结主干网络,仅使用 LoRA 微调低秩适配器(秩为16,缩放因子为32),使得可训练参数量与基线相当或更少。
- 训练资源:在 8 × NVIDIA H200 GPUs 上进行训练。
Card 06
评估与结果
评估与结果
- 评估环境与基准:在定义的 OD-E2E 任务下,与多种SOTA基线进行比较,包括传统轨迹预测模型(PTPC, PECNet等)和大型视觉语言模型(Qwen2.5-VL-72B, Qwen3-VL-8B, FSDrive-Finetuned, CAVG等)。
- 主要评估指标:轨迹规划(ADE, FDE, Fréchet, DTW, SSPD, PA2/PA4);视觉定位(IoU);情感估计(Spearman's ρ, Kendall's τ 相关性)。
- 关键实验结果:
- 端到端规划:E3AD 在所有七项轨迹指标上全面超越所有基线。与最佳基线PTPC相比,ADE降低 17.01%,FDE降低 20.00%,PA4提升 18.10%。
- 视觉定位:在多个数据集的测试集上,E3AD 的IoU得分显著高于包括CAVG在内的SOTA方法,例如在Talk2Car上达到 80.12%,比CAVG提升 6.86%。在具有挑战性的角点场景测试集上优势更明显。
- 情感估计:在VAD相关性评估中,E3AD 取得了SOTA结果(如 Valence 的 Spearman's ρ 达到 0.95),远超大型语言模型(如Qwen2.5-7B-Instruct的0.11)和基于BERT的方法。
- 空间推理:在Talk2Car上的定位IoU显著优于原始Qwen2.5-VL-7B模型(80.12% vs 40.23%)。