一眼看懂
封面预览
研究旨在解决机器人研究中的数据稀缺问题,通过将人类活动视频"机器人化"(robotize)为人形机器人视频,以训练 VLA(视觉-语言-动作)…
- 研究旨在解决机器人研究中的数据稀缺问题,通过将人类活动视频"机器人化"(robotize)为人形机器人视频,以训练 VLA(视觉-语言-动作)…
- 提出 X-Humanoid 方法,将强大的 Wan 2.2 视频生成模型适配为视频到视频的编辑架构,并进行微调以实现人类到人形机器人的转换
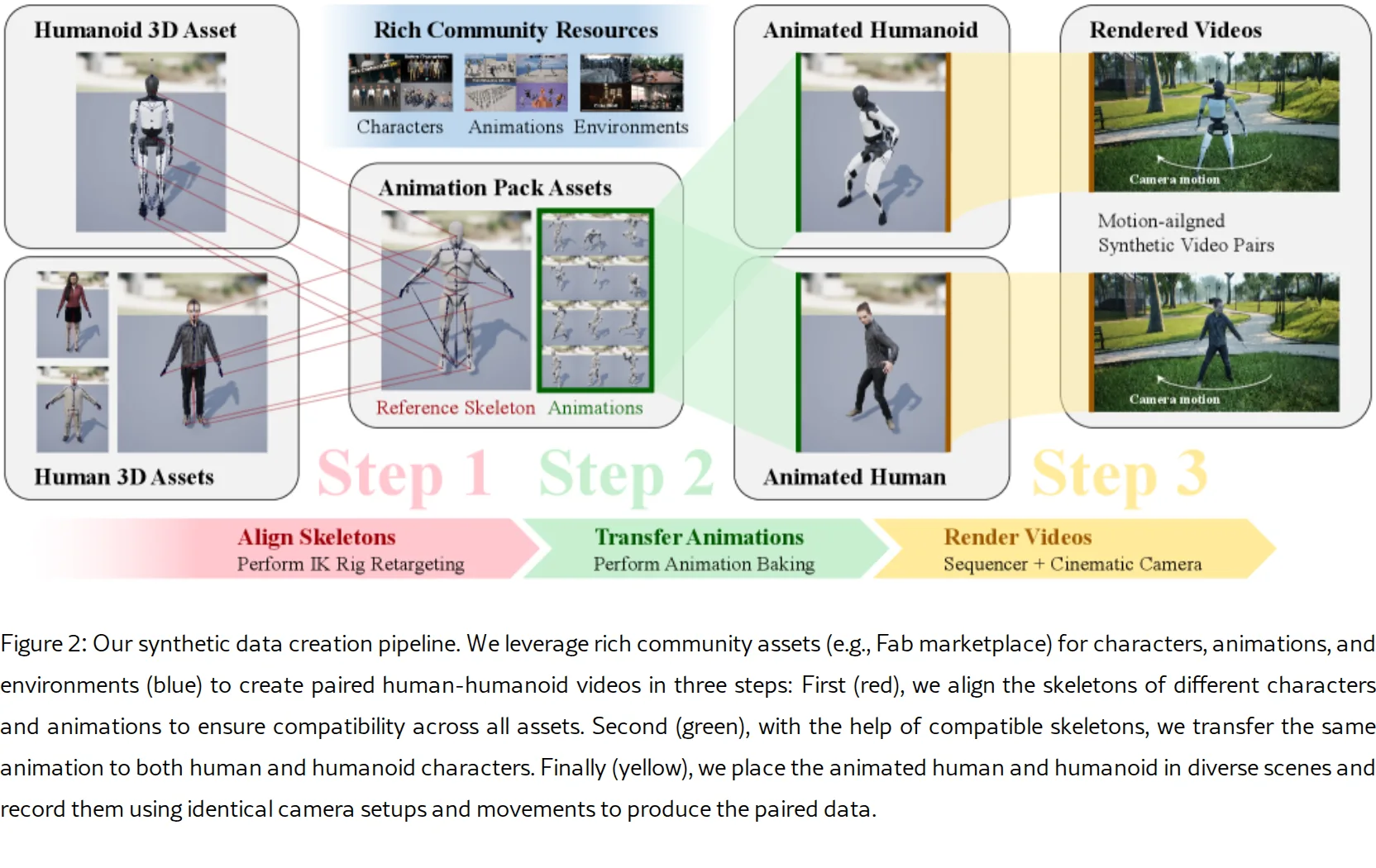
- 构建了可扩展的数据合成管道,使用 Unreal Engine 生成了超过 17 小时 的配对人类-人形机器人视频,并将其应用于 Ego-Exo…
Card 01
研究单位
研究单位
- Show Lab, National University of Singapore(新加坡国立大学 Show 实验室)
Card 02
论文概述
论文概述
- 研究旨在解决机器人研究中的数据稀缺问题,通过将人类活动视频"机器人化"(robotize)为人形机器人视频,以训练 VLA(视觉-语言-动作)模型和世界模型
- 提出 X-Humanoid 方法,将强大的 Wan 2.2 视频生成模型适配为视频到视频的编辑架构,并进行微调以实现人类到人形机器人的转换
- 构建了可扩展的数据合成管道,使用 Unreal Engine 生成了超过 17 小时 的配对人类-人形机器人视频,并将其应用于 Ego-Exo4D 数据集,生成了 60 小时(360 万帧)的机器人化视频数据集
Card 03
核心贡献
核心贡献
- 引入生成式视频编辑方法来解决机器人研究中的数据稀缺问题,通过适配和微调现代视频生成模型
- 设计了可扩展的管道,在 Unreal Engine 中合成配对的人类-人形机器人视频,发布了新的 17+ 小时 1080p 30fps 数据集用于模型训练
- 创建并发布了从 Ego-Exo4D 编辑的 60+ 小时"机器人化"数据集,以 Tesla Optimus 人形机器人为特征,帮助缓解机器人数据稀缺问题
Card 04
方法描述
方法描述
- 模型架构:将 Wan 2.2(Diffusion Transformer)适配为视频输入输出结构,编码输入视频为条件标记(condition tokens),与生成标记(generation tokens)拼接
- 关键创新:在自注意力中使用单向掩码,防止条件标记关注生成标记,确保时空对应关系;使用相同的位置嵌入
- 微调方法:采用 LoRA 微调(rank-96),使用流匹配(flow-matching)目标函数,预测从噪声到干净潜在标记的速度向量
- 条件文本:使用固定提示词 "Humanoid video" 作为条件文本嵌入
Card 05
数据集与资源
数据集与资源
- 合成数据集:11172 对视频,14 个虚拟场景,1080p 30fps,总计 280 万帧,渲染耗时 10 天(单块 RTX 3060)
- 真实数据集:60 小时(360 万帧)来自 Ego-Exo4D 数据集的机器人化视频
- 训练资源:4 块 NVIDIA H200 GPU,DDP 并行,batch size 为 1,AdamW 优化器,lr=1e-4,500 步微调,2.5 小时完成
- 模型规模:基于 Wan2.2-TI2V-5B 模型,仅使用 6.4% 的合成数据进行训练
- 推理成本:编辑 480p 90 帧视频约需 7.5 分钟,显存约 56.2GB
Card 06
评估与结果
评估与结果
- 评估方法:用户研究(29 名参与者)+ 定量指标(PSNR、SSIM、MSE)
- 基准对比:与 Kling、MoCha、Runway Aleph 三种图像条件视频编辑模型对比
- 关键结果:
- 运动一致性:69.0% 用户首选(最佳)
- 背景一致性:75.9% 用户首选(最佳)
- 化身一致性:62.1% 用户首选(最佳)
- 整体质量:62.1% 用户首选(最佳)
- 定量指标:PSNR 21.836、SSIM 0.671、MSE 459.302,均显著优于基准
- 消融实验:5B 模型优于 14B 模型(计算成本低 10 倍以上);500 步为最佳微调步数;使用 "Humanoid video" 提示效果最佳