一眼看懂
封面预览
论文提出了 dVLM-AD,一个基于扩散模型的视觉-语言模型,用于端到端自动驾驶,旨在统一感知、结构化推理和低层规划。
- 论文提出了 dVLM-AD,一个基于扩散模型的视觉-语言模型,用于端到端自动驾驶,旨在统一感知、结构化推理和低层规划。
- 该模型旨在解决现有自回归(AR)模型在自动驾驶中面临的两个核心问题:推理-动作不一致 和 生成不可控。
- 通过将生成过程重构为迭代去噪,并利用模板锚定的约束填充,实现了更具可控性和全局一致性的推理与动作生成。
Card 01
研究单位
研究单位
- University of Wisconsin-Madison
- NVIDIA
- Stanford University
- Johns Hopkins University
Card 02
论文概述
论文概述
- 论文提出了 dVLM-AD,一个基于扩散模型的视觉-语言模型,用于端到端自动驾驶,旨在统一感知、结构化推理和低层规划。
- 该模型旨在解决现有自回归(AR)模型在自动驾驶中面临的两个核心问题:推理-动作不一致 和 生成不可控。
- 通过将生成过程重构为迭代去噪,并利用模板锚定的约束填充,实现了更具可控性和全局一致性的推理与动作生成。
Card 03
核心贡献
核心贡献
- 提出了 dVLM-AD 框架,这是首个将离散扩散视觉-语言模型应用于自动驾驶领域并进行可控推理的工作。
- 设计了 动态去噪策略,通过引入“归约令牌”解决了固定长度槽位带来的“长度匹配偏差”问题,实现了变长内容的可控生成。
- 构建了包含 145k 驾驶相关QA对和 53k 结构化推理-动作标注的训练数据集,以增强模型在驾驶领域的理解和规划能力。
- 在 nuScenes 和 WOD-E2E 基准上进行了广泛实验,证明了dVLM-AD在推理-动作一致性和规划性能上优于自回归基线模型。
Card 04
方法描述
方法描述
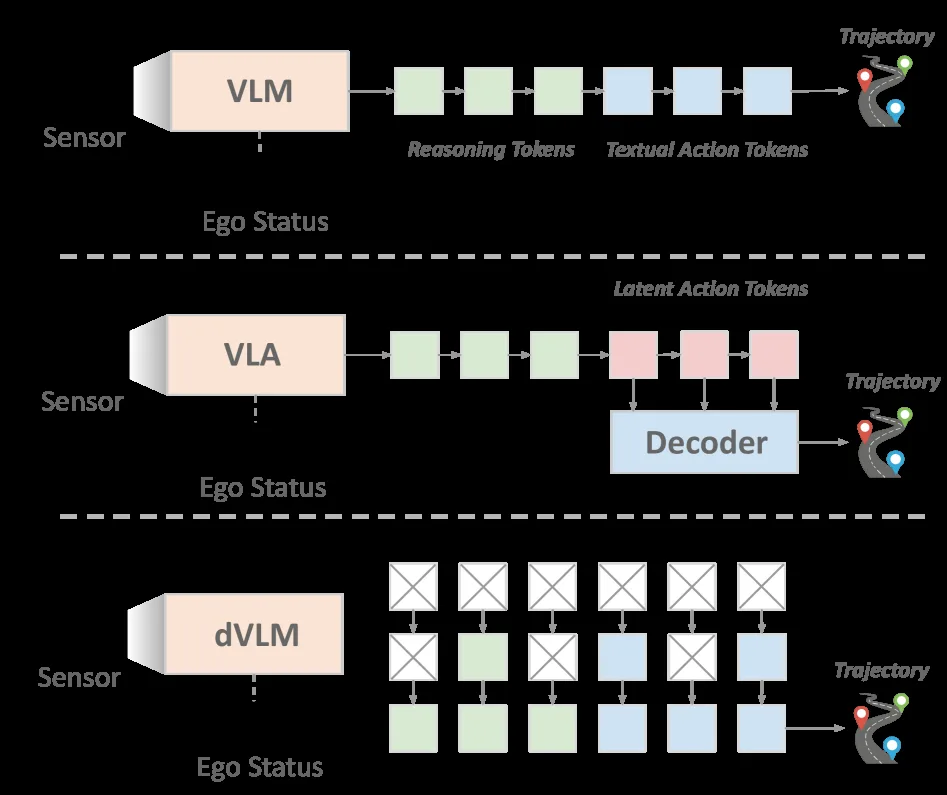
- 模型架构基于 LLaDA-V,由LLM主干、视觉编码器和多模态投影器组成,采用文本航点作为动作表示。
- 核心创新在于将自由形式生成转换为 模板锚定的约束填充。通过初始化带有可见锚点的部分掩码序列,强制生成过程遵循结构化模板(如:物体检测->解释->未来行为->轨迹)。
- 为了解决固定模板槽位长度不匹配的问题,提出了 动态去噪策略。该策略允许模型在去噪过程中,当对“归约令牌”的置信度超过阈值时,提前终止当前槽位的生成并修剪后续掩码令牌。
Card 05
数据集与资源
数据集与资源
- 使用的数据集:nuScenes 和 Waymo Open Dataset End-to-End (WOD-E2E)。
- 训练数据:
- 第一阶段:来自多个开源数据集的 145k 驾驶相关QA对,用于领域对齐。
- 第二阶段:为nuScenes和WOD-E2E分别构建了 23k 和 30k 条结构化推理-动作标注数据,用于监督微调。
- 模型基础:基于 LLaDA-V (使用 LLaDA-8B-Instruct 作为LLM主干)。
Card 06
评估与结果
评估与结果
- 评估环境:在 nuScenes 和 WOD-E2E 数据集上进行了开环评估。
- 主要评估指标:
- 规划性能:L2误差、平均位移误差(ADE)、评估者反馈分数(RFS)。
- 一致性:物体-解释一致性、行为-轨迹一致性。
- 关键实验结果:
- 一致性:dVLM-AD的物体-解释一致性接近 99%,行为-轨迹一致性(平均)达到 87.8% (nuScenes) 和 80.1% (WOD-E2E),显著优于自回归基线。
- 规划性能:在WOD-E2E长尾场景测试集上,dVLM-AD取得了最高的RFS (7.633) 和最低的ADE@3s (1.285),超越了使用更强骨干和更多训练数据的AutoVLA。
- 鲁棒性:在对抗性的提示扰动(如顺序扰动、轨迹遗漏)实验中,dVLM-AD的性能几乎不受影响,而自回归模型的性能则严重下降,证明了其生成的高度可控性和鲁棒性。