一眼看懂
封面预览
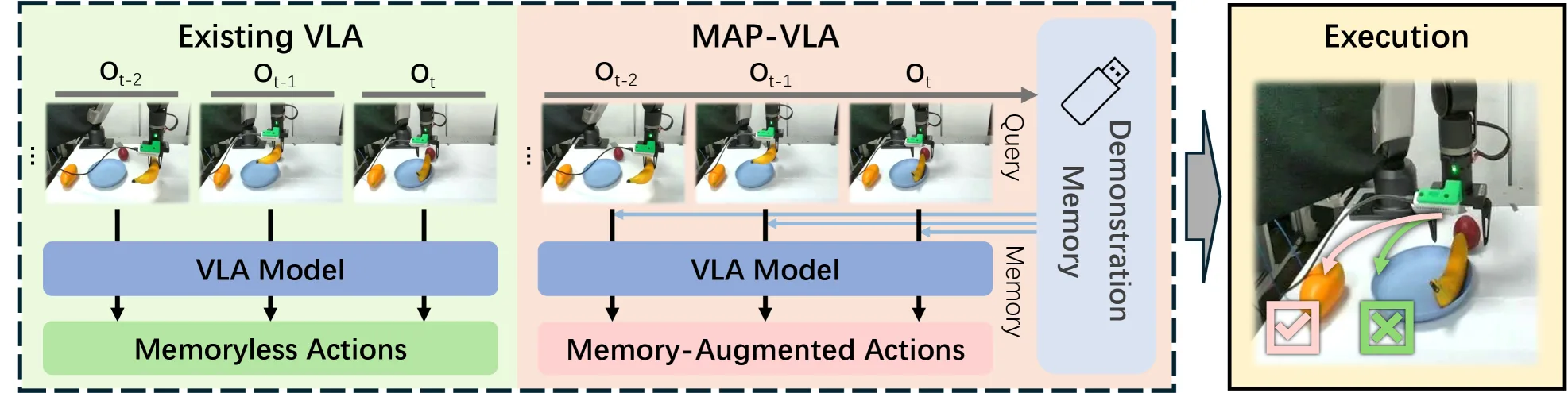
论文提出了 MAP-VLA 框架,旨在通过演示派生的记忆提示增强预训练视觉-语言-动作(VLA)模型,以解决长视野机器人操作任务。
- 论文提出了 MAP-VLA 框架,旨在通过演示派生的记忆提示增强预训练视觉-语言-动作(VLA)模型,以解决长视野机器人操作任务。
- 针对现有 VLA 模型缺乏记忆机制、仅依赖即时感官输入导致在长视野任务中表现不佳的问题,该框架引入了情景记忆能力。
- 该方法作为一个即插即用模块,无需修改模型内部权重,通过提示调优和检索增强生成来提升任务适应性。
Card 01
研究单位
研究单位
- Nanyang Technological University (新加坡南洋理工大学)
- VinUniversity (越南维诺大学)
- Beijing University of Posts and Telecommunications (北京邮电大学)
- Tsinghua University (清华大学)
- South China University of Technology (华南理工大学)
Card 02
论文概述
论文概述
- 论文提出了 MAP-VLA 框架,旨在通过演示派生的记忆提示增强预训练视觉-语言-动作(VLA)模型,以解决长视野机器人操作任务。
- 针对现有 VLA 模型缺乏记忆机制、仅依赖即时感官输入导致在长视野任务中表现不佳的问题,该框架引入了情景记忆能力。
- 该方法作为一个即插即用模块,无需修改模型内部权重,通过提示调优和检索增强生成来提升任务适应性。
Card 03
核心贡献
核心贡献
- 提出了 MAP-VLA 框架,利用演示派生的记忆提示增强预训练 VLA 模型,实现了无需修改模型权重即可进行的任务适应。
- 设计了记忆提示构建(MPC)模块,将专家演示中的阶段特定知识编码为提示库;开发了记忆增强动作生成(MAAG)模块,实现了记忆检索与动态提示集成。
- 在仿真基准和真实机器人评估中,MAP-VLA 在长视野任务上显著超越了现有的最先进方法(如 OpenVLA 和 $\pi_0$)。
Card 04
方法描述
方法描述
- 基于 $\pi_0$ 模型,通过 LoRA 进行微调后冻结模型权重。
- Memory Prompt Construction (MPC):使用 RDP 算法识别关键姿态并利用 DTW 算法对齐轨迹,将演示分割为阶段,并为每个阶段通过提示调优优化可学习的软提示。
- Memory-Augmented Action Generation (MAAG):在线执行时,通过计算轨迹相似度(L2 距离)检索最相关的记忆提示和演示动作。
- Memory-aware Prompt Ensembling:动态加权检索到的记忆提示预测与基础提示预测,结合检索到的专家动作先验生成最终动作。
Card 05
数据集与资源
数据集与资源
- 仿真环境使用了 LIBERO 基准测试,特别是其中的长视野任务套件 LIBERO-Long。
- 真实机器人实验使用了 6-DoF Galaxea A1 机械臂。
- 模型训练使用了 6 张 NVIDIA RTX 6000 Ada GPU,真实机器人推理使用了 NVIDIA RTX 4090 GPU。
Card 06
评估与结果
评估与结果
- 主要对比基准为 OpenVLA 和 $\pi_0$ 模型。
- 在 LIBERO-Long 仿真基准上,MAP-VLA 平均成功率达到 83.4%,相比最强基线 $\pi_0$ 提升了 7.0% 的绝对性能。
- 在真实机器人长视野任务评估中,MAP-VLA 的完全成功率相比基线实现了 25.0% 的绝对提升。
- 实验还表明该方法在视觉变化(如模糊、光照变化)和少样本(10-shot/20-shot)设置下均表现出更强的鲁棒性。