一眼看懂
封面预览
提出一种名为 SemanticVLA 的新型视觉-语言-动作模型框架,旨在实现高效且可解释的机器人操作。
- 提出一种名为 SemanticVLA 的新型视觉-语言-动作模型框架,旨在实现高效且可解释的机器人操作。
- 解决现有VLA模型在部署中面临的两个核心瓶颈:感知冗余(处理无关视觉输入效率低)和 指令-视觉对齐浅层化(阻碍动作的语义基础)。
- 通过语义对齐的稀疏化与增强技术,在降低计算成本的同时提升任务性能与推理能力。
Card 01
研究单位
研究单位
- 论文作者包括 Wei Li, Renshan Zhang, Rui Shao, Zhijian Fang, Kaiwen Zhou, Zhuotao Tian, Liqiang Nie,但原文中未明确列出其所属的具体研究机构名称。
Card 02
论文概述
论文概述
- 提出一种名为 SemanticVLA 的新型视觉-语言-动作模型框架,旨在实现高效且可解释的机器人操作。
- 解决现有VLA模型在部署中面临的两个核心瓶颈:感知冗余(处理无关视觉输入效率低)和 指令-视觉对齐浅层化(阻碍动作的语义基础)。
- 通过语义对齐的稀疏化与增强技术,在降低计算成本的同时提升任务性能与推理能力。
Card 03
核心贡献
核心贡献
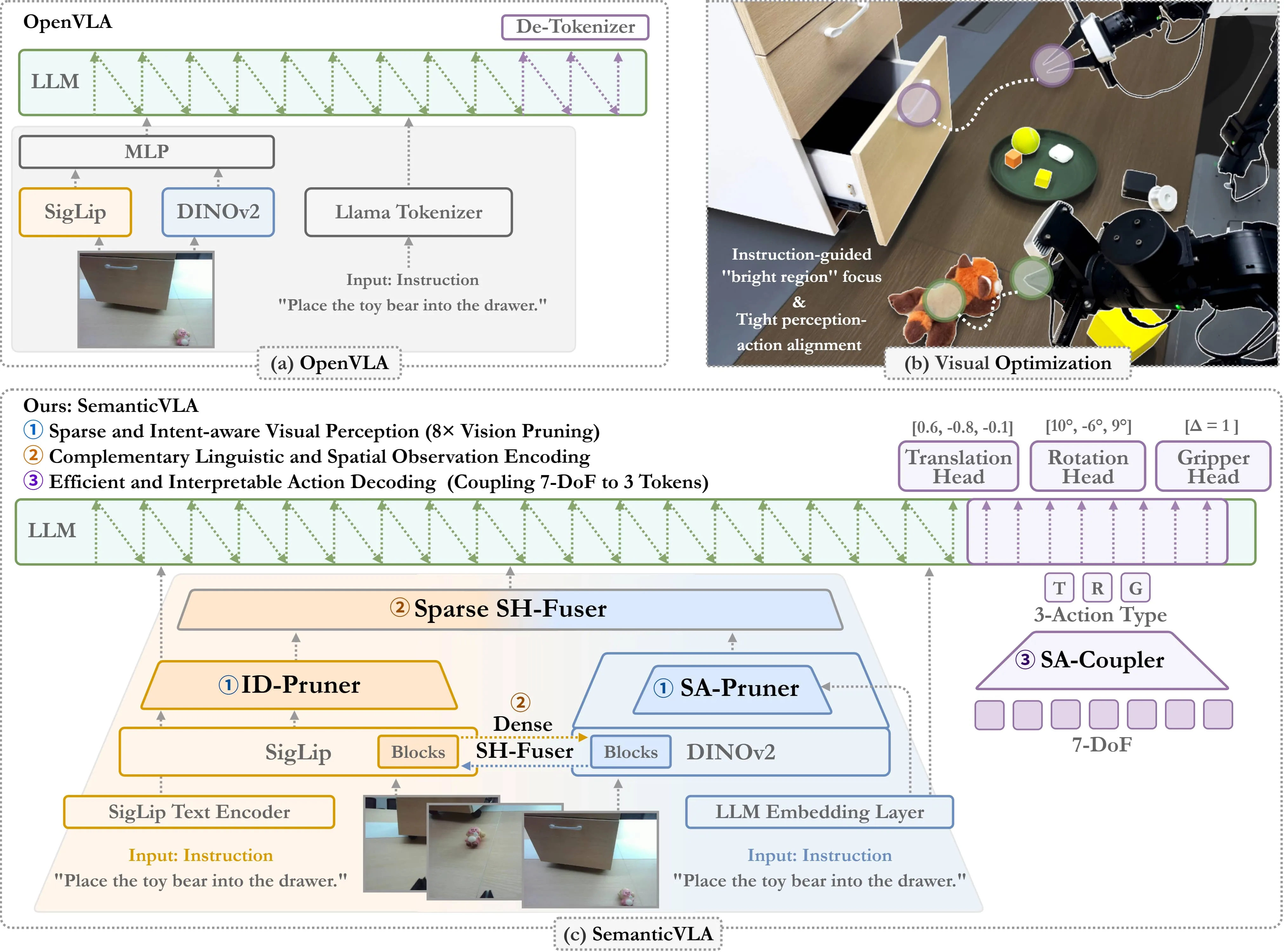
- 提出 SD-Pruner (语义引导双视觉修剪器),通过 ID-Pruner 和 SA-Pruner 分别对 SigLIP 和 DINOv2 编码器进行指令感知与几何感知的联合修剪,大幅剪除冗余感知信息。
- 设计 SH-Fuser (语义互补层次融合器),通过双流融合机制,整合来自 SigLIP 和 DINOv2 的密集块特征与稀疏语义标记,增强指令语义与空间结构的对齐。
- 引入 SA-Coupler (语义条件化动作耦合器),将感知表示映射到语义动作类型,替代传统观测到自由度的映射,实现更高效、可解释的行为建模。
- 在仿真和真实世界任务中进行了广泛实验,证明了模型在性能与效率上均达到SOTA水平。
Card 04
方法描述
方法描述
- 模型采用双视觉编码器架构:SigLIP 用于指令感知编码,DINOv2 用于空间感知编码。
- ID-Pruner 计算指令-图像跨模态相似性,通过视觉到语言映射和语言到视觉过滤两条路径,提取全局动作线索和局部语义锚点,生成稀疏视觉标记。
- SA-Pruner 利用聚合标记和 FiLM 层对 DINOv2 的空间特征进行指令调制与聚合,产生几何丰富且任务相关的稀疏标记。
- SH-Fuser 包含 Dense-Fuser(跨编码器块交换块级信息)和 Sparse-Fuser(合并修剪后的显著标记),实现层次化融合。
- SA-Coupler 将每个未来动作表示为平移、旋转和夹持三个独立的标记,并通过专用预测头直接回归连续运动参数,实现并行解码。
Card 05
数据集与资源
数据集与资源
- 仿真实验使用 LIBERO 基准,包含 Spatial、Object、Goal、Long 四个任务套件,每个套件500个人工遥操作演示。
- 真实世界实验在 AgileX Cobot Magic 平台上进行,涵盖物体放置、抽屉操作、T恤折叠等长视野任务。
- 模型以 OpenVLA 为骨干,采用 LoRA 微调。实验在 8× A800 (80GB) GPU 上进行。
Card 06
评估与结果
评估与结果
- 在 LIBERO 基准上,SemanticVLA 取得 97.7% 的总体成功率,排名第一,显著超越基线模型。
- 效率方面,相比 OpenVLA,训练成本降低 3.0倍,推理延迟降低 2.7倍,视觉输入标记减少至 1/16 或 1/8,动作表示标记减少至 3/7。
- 在真实世界长视野任务中,SemanticVLA 的成功率达到 77.8%,比最佳基线 OpenVLA-OFT 高出 22.2%。
- 消融实验验证了各组件的有效性,并表明在8倍稀疏化率下取得了性能与效率的最佳平衡。