一眼看懂
封面预览
研究视觉语言动作(VLA)模型中的具身思维链忠实性(embodied CoT faithfulness)问题:模型生成的文本计划与实际执行的低…
- 研究视觉语言动作(VLA)模型中的具身思维链忠实性(embodied CoT faithfulness)问题:模型生成的文本计划与实际执行的低…
- 提出SEAL(Steering for Embodied Reasoning-Action Alignment)方法,通过运行时验证和策略引导…
- 在LIBERO基准上验证,方法在分布外(OOD)场景和新型为组合任务上实现最高15%的性能提升
Card 01
研究单位
研究单位
- NVIDIA(第一作者单位)
- 卡内基梅隆大学(Carnegie Mellon University)
- 犹他大学(University of Utah)
- 悉尼大学(University of Sydney)
Card 02
论文概述
论文概述
- 研究视觉语言动作(VLA)模型中的具身思维链忠实性(embodied CoT faithfulness)问题:模型生成的文本计划与实际执行的低层次动作之间存在不匹配,导致即使有正确的文本计划,生成的动作也无法实现预期结果
- 提出SEAL(Steering for Embodied Reasoning-Action Alignment)方法,通过运行时验证和策略引导来强制推理-动作对齐,无需额外微调数据即可提升任务成功率和鲁棒性
- 在LIBERO基准上验证,方法在分布外(OOD)场景和新型为组合任务上实现最高15%的性能提升
Card 03
核心贡献
核心贡献
- 运行时策略引导框架:在推理VLA执行动作前,采样多个候选动作序列,通过VLM验证器预测每个序列的结果,选择与文本计划对齐的动作执行
- 泛化能力与Scaling分析:通过受控的OOD转移和为组合任务实验,证明方法在不同规模的训练数据上均优于基线,且性能随数据规模提升
- 推理标注的VLA数据集:贡献了推理标注的LIBERO-100数据集和扩展的基准测试,用于研究推理VLAs的泛化能力
Card 04
方法描述
方法描述
- 推理VLA训练:基于OneTwoVLA架构,使用Gemini自动生成中间文本推理标注,通过监督微调训练能够交错生成文本推理和动作的模型
- 运行时策略引导三阶段过程:
- Hypothesize:从推理VLA采样K个候选动作序列
- Predict:使用动力学模型模拟预测每个候选序列的结果图像
- Verify:使用预训练的VLM(如GPT-4o)作为验证器,评估预测结果与文本计划的对齐程度,选择得分最高的动作执行
- 技术创新:采用异步验证和早退策略减少延迟,实现347ms的推理时间
Card 05
数据集与资源
数据集与资源
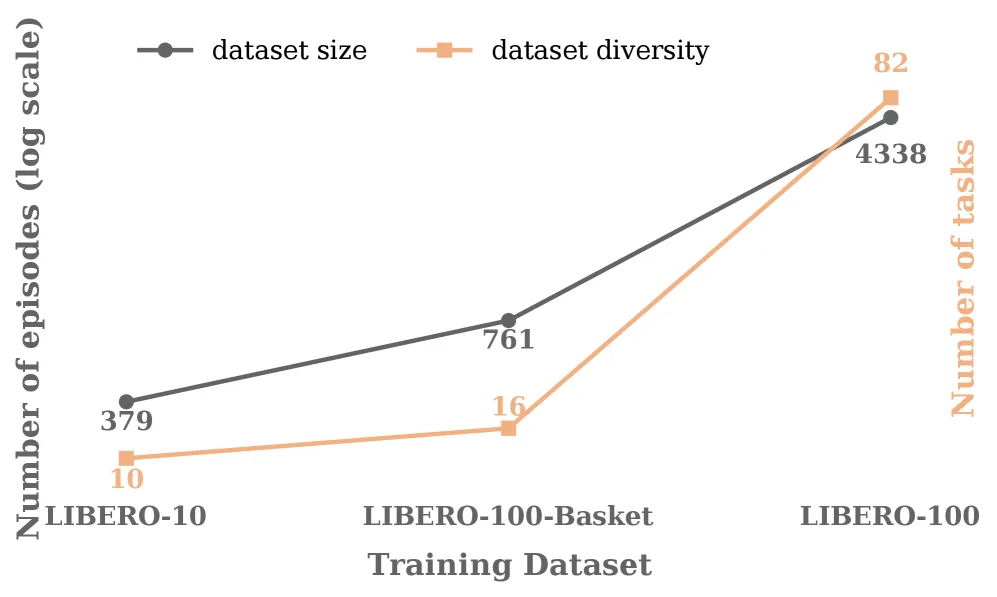
- 训练数据集:三个规模的推理标注数据集——LIBERO-10-R、LIBERO-100-Basket-R、LIBERO-100-R
- 评估基准:LIBERO-10测试集、四种OOD变体(语义OOD和视觉OOD)、新型为组合任务(LIBERO-10/100-Compose)
- 模型基础:基于π₀ VLA架构,训练使用8块A100 GPU,约20小时完成
Card 06
评估与结果
评估与结果
- 分布内任务:SEAL在ID任务上达到94-97%成功率,优于基线方法
- OOD鲁棒性:在语义和视觉OOD转移测试中,SEAL保持最佳性能,在最具挑战性的Visual-Viewpoint场景下领先基线超过17%
- 为组合任务:在新型为组合任务上,SEAL展现出正Scaling趋势,尤其在大型多样训练数据上优势明显
- 运行时Scaling:增加候选序列数量K可提升性能,K=10时实现最佳延迟-性能平衡