一眼看懂
封面预览
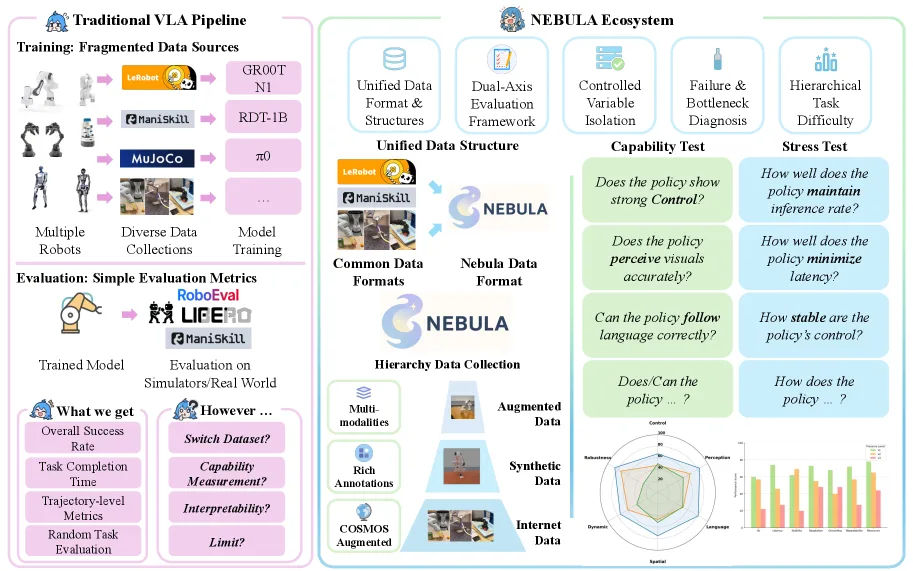
论文针对当前 VLA (Vision-Language-Action) 智能体评估方法存在的问题提出批评:现有基准测试主要使用粗粒度的任务成功…
- 论文针对当前 VLA (Vision-Language-Action) 智能体评估方法存在的问题提出批评:现有基准测试主要使用粗粒度的任务成功…
- 研究目标:构建一个统一的生态系统 NEBULA,用于单臂操作的诊断性和可重复评估,解决数据碎片化问题并建立双轴评估框架
- 核心创新:结合细粒度的 能力测试 (Capability Tests) 进行精确技能诊断,并通过系统的 压力测试 (Stress Tests)…
Card 01
研究单位
研究单位
- Case Western Reserve University (凯斯西储大学) - Department of Computer & Data Sciences
- 作者包括:Jierui Peng, Yanyan Zhang (通讯作者), Yicheng Duan, Tuo Liang, Vipin Chaudhary, Yu Yin
Card 02
论文概述
论文概述
- 论文针对当前 VLA (Vision-Language-Action) 智能体评估方法存在的问题提出批评:现有基准测试主要使用粗粒度的任务成功率指标,无法提供精确的技能诊断或衡量对真实世界扰动的鲁棒性
- 研究目标:构建一个统一的生态系统 NEBULA,用于单臂操作的诊断性和可重复评估,解决数据碎片化问题并建立双轴评估框架
- 核心创新:结合细粒度的 能力测试 (Capability Tests) 进行精确技能诊断,并通过系统的 压力测试 (Stress Tests) 衡量智能体在真实扰动下的鲁棒性
Card 03
核心贡献
核心贡献
- 提出 NEBULA 统一 VLA 生态系统,提供标准化 API 和大规模聚合数据集,支持跨数据集训练和基准测试
- 设计 双轴评估协议,将能力评估与压力测试分离,结合能力测试(6 种核心技能)和压力测试(5 个操作约束维度)
- 对当前主流 VLA 模型进行深入基准测试研究,揭示了空间推理和动态适应等关键失败模式,这些通常被传统成功率指标所掩盖
Card 04
方法描述
方法描述
- 统一数据平台:基于 SAPIEN 引擎和 ManiSkill3 框架构建,提供结构化的episode格式和多模态观测(RGB、深度、分割图像 + 本体感受)
- 双轴评估框架:
- 能力测试任务:Control (控制)、Perception (感知)、Language (语言)、Dynamic Adaptation (动态适应)、Spatial Reasoning (空间推理)、Robustness/Generalization (鲁棒性/泛化),每个家族分为 Easy/Medium/Hard 三个难度等级
- 压力测试任务:Inference Frequency (推理频率)、Latency (延迟)、Stability Score (稳定性评分)、Adaptability (适应性)、Resources (资源),每个指标在三个压力水平 (v1-v3) 上进行测试
Card 05
数据集与资源
数据集与资源
- NEBULA-Alpha:54,000+ 专家演示轨迹,覆盖 5 个能力家族(控制、感知、语言、动态、空间),共 222,000 个视频,38,015 条描述
- NEBULA-Beta:轻量级版本(每个任务约 10%),部分任务使用人类远程操作收集
- 模拟平台:基于 SAPIEN 引擎和 ManiSkill3 框架
- 评估模型:GR00T-1.5、SpatialVLA、RDT-1B、MT-ACT、Diffusion Policy、ACT
Card 06
评估与结果
评估与结果
- 能力测试结果:大多数模型在 Perception 和 Language 任务上表现良好;Control 和 Spatial 任务表现各异;所有模型在 Dynamic Adaptation 和 Robustness 任务上表现较差,雷达图分数接近零
- 压力测试结果:随着压力水平增加,所有模型性能一致下降;GR00T-1.5 保持最高推理频率(约 17Hz,v3 水平)和最低延迟(约 58.62ms);DP 显示延迟显著增加,v3 水平接近 800ms
- 关键发现:空间推理是主要瓶颈;快速推理是动态适应的关键(GR00T-1.5 是唯一显示有意义适应的模型,成功率 28%);VLM 的强推理能力不能保证成功的具身行为,关键瓶颈在于动作头部将抽象计划转换为精确控制动作的能力