一眼看懂
封面预览
DiffVLA++ 是一个增强的自动驾驶框架,通过度量引导对齐机制桥接认知推理与端到端规划
- DiffVLA++ 是一个增强的自动驾驶框架,通过度量引导对齐机制桥接认知推理与端到端规划
- 解决传统 E2E 模型缺乏世界知识导致的长尾场景泛化问题,以及 VLA 模型 3D 推理能力不足导致的物理不可行动作问题
- 在 ICCV 2025 Autonomous Grand Challenge 排行榜上取得 EPDMS 49.12 的成绩
Card 01
研究单位
研究单位
- RIX, Bosch: Yu Gao, Yiru Wang, Zhigang Sun, Heng Yuwen, Wang Shuo, Hao Sun
- AIR, Tsinghua University: Wang Jijun, Hao Zhao
- Shanghai Jiao Tong University: Hao Jiang
Card 02
论文概述
论文概述
- DiffVLA++ 是一个增强的自动驾驶框架,通过度量引导对齐机制桥接认知推理与端到端规划
- 解决传统 E2E 模型缺乏世界知识导致的长尾场景泛化问题,以及 VLA 模型 3D 推理能力不足导致的物理不可行动作问题
- 在 ICCV 2025 Autonomous Grand Challenge 排行榜上取得 EPDMS 49.12 的成绩
Card 03
核心贡献
核心贡献
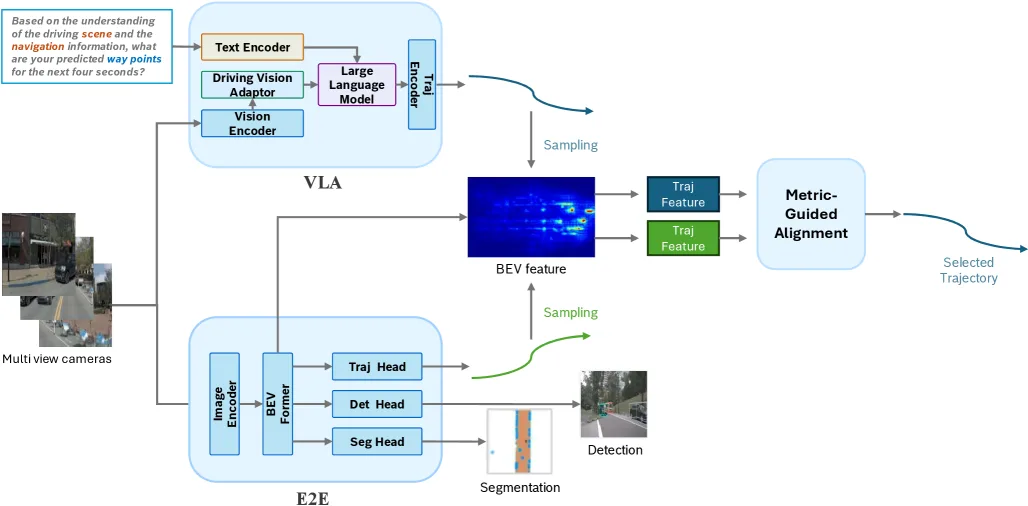
- 构建了全可微分的 VLA 模块,直接生成语义基础的驾驶轨迹,包含显式 3D 推理能力
- 设计了基于密集 BEV 的传统 E2E 模块,配备 Transformer 轨迹头和密集轨迹词汇表(M=8192),确保物理可行性
- 引入度量引导轨迹评分器(MLP-based),将 VLA 和 E2E 模块的输出投影到共享度量空间,实现显式对齐
- VLA 模块采用 CLIP ViT-L/14 视觉编码器和 Vicuna-v1.5-7B 大语言模型
- E2E 模块使用 BevFormer 生成 BEV 表示,VoVNet-99 作为图像主干
Card 04
方法描述
方法描述
- VLA 模块:CLIP ViT-L/14 编码多视角图像,经 Driving Vision Adapter 压缩,与导航指令文本一起输入 Vicuna-7B,LLM 最后层直接预测 4 秒未来的 8 个航点(2Hz,x, y, θ)
- E2E 模块:BevFormer 生成 128×128 BEV 特征图(覆盖 64×64 米),包含agent检测头、语义分割头和轨迹规划头;轨迹规划头基于 K-means 聚类专家轨迹构建的 8192 条轨迹词汇表
- 度量引导对齐:评分器使用 8 个 MLP 头预测 NC、DAC、DDC、TLC、EP、TTC、LK、HC 等度量,通过加权求和选择最优轨迹
Card 05
数据集与资源
数据集与资源
- 数据集:Navsim 数据集(navtrain split 用于训练)
- VLA 模型:约 7B 参数(Vicuna-v1.5-7B + CLIP ViT-L/14)
- E2E 模块:VoVNet-99 主干 + BevFormer,特征维度 d=256
- 训练资源:VLA 训练使用 8 张 NVIDIA A800 GPU,batch size=8,lr=1e-5;E2E+评分器训练使用 4 张 A800 GPU,batch size=8,lr=1e-4,训练 30 epochs
Card 06
评估与结果
评估与结果
- 评估基准:NavsimV2 / ICCV 2025 Autonomous Grand Challenge
- 评估指标:Extended Predictive Driver Model Score (EPDMS)
- 关键结果:
- VLA 分支:EPDMS 48.0
- E2E 分支:EPDMS 43.7
- 最终集成模型:EPDMS 49.12
- NC(一阶段):98.21,DAC:98.57,DDC(一阶段):100,EP:79.51