一眼看懂
封面预览
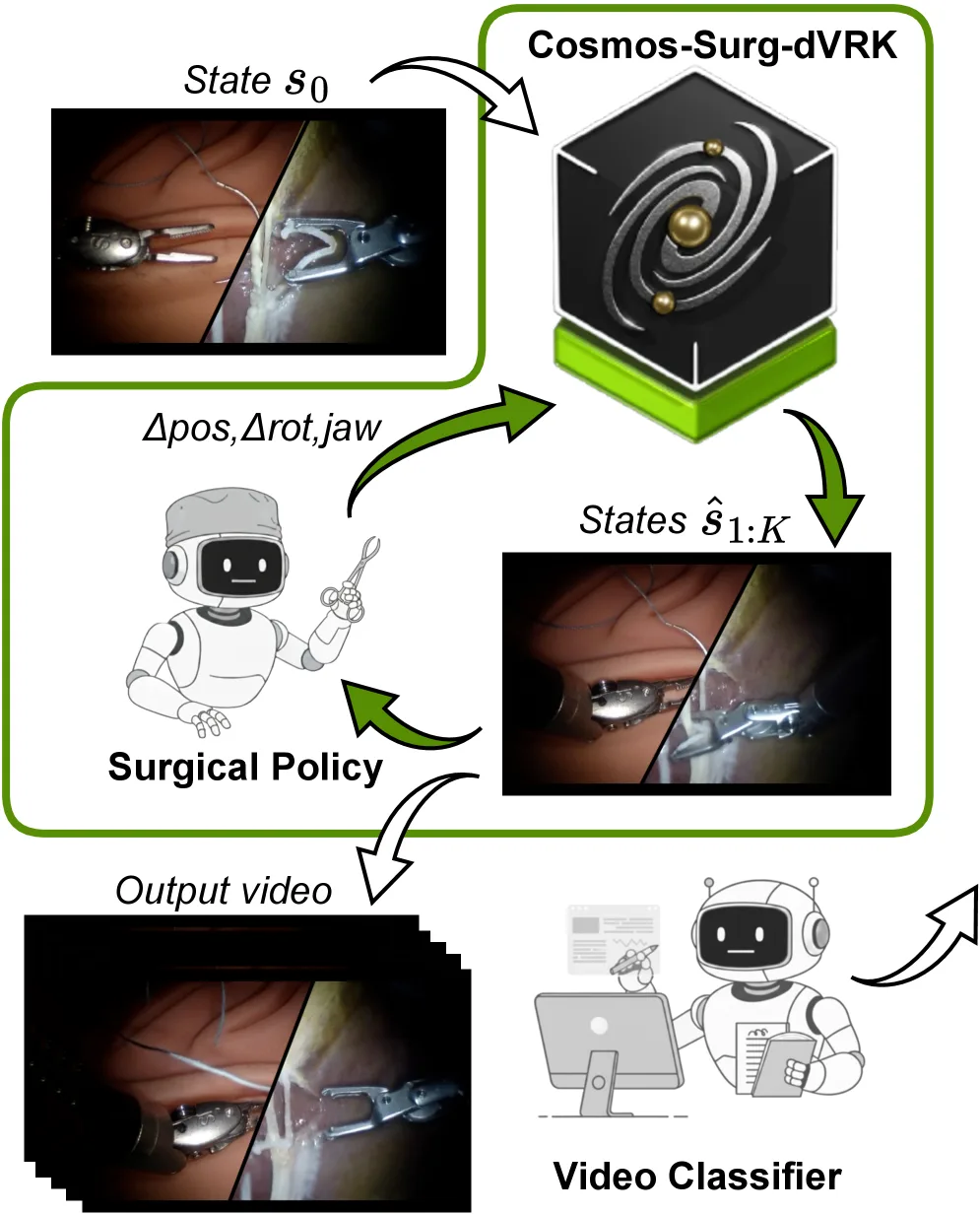
论文提出 Cosmos-Surg-dVRK,一种基于 Cosmos 世界基础模型的外科手术微调版本,用于在模拟环境中自动评估手术机器人策略
- 论文提出 Cosmos-Surg-dVRK,一种基于 Cosmos 世界基础模型的外科手术微调版本,用于在模拟环境中自动评估手术机器人策略
- 研究目标是通过世界模型模拟替代真实的 dVRK Si 机器人平台评估,解决外科手术策略评估成本高、时间长、可重复性差的问题
- 在桌面缝合任务和离体猪胆囊切除术任务上验证了模拟与真实机器人性能之间的强相关性
Card 01
研究单位
研究单位
- NVIDIA - Lukas Zbinden, Nigel Nelson, Mahdi Azizian, Sean Huver
- Johns Hopkins University - Juo-Tung Chen, Xinhao Chen, Ji Woong (Brian) Kim, Axel Krieger
- Stanford University - Ji Woong (Brian) Kim
Card 02
论文概述
论文概述
- 论文提出 Cosmos-Surg-dVRK,一种基于 Cosmos 世界基础模型的外科手术微调版本,用于在模拟环境中自动评估手术机器人策略
- 研究目标是通过世界模型模拟替代真实的 dVRK Si 机器人平台评估,解决外科手术策略评估成本高、时间长、可重复性差的问题
- 在桌面缝合任务和离体猪胆囊切除术任务上验证了模拟与真实机器人性能之间的强相关性
Card 03
核心贡献
核心贡献
- 证明 Cosmos-Surg-dVRK 能够进行手术策略的在线评估,在桌面任务上与真实世界策略性能呈强正相关(Pearson r=0.718)
- 构建了完全自动化的策略评估流程,视频分类器(V-JEPA 2)与人类标注者之间达到良好的一致性(ICC=0.836)
- 将 Cosmos-Surg-dVRK 扩展到离体猪胆囊切除术的在线策略评估,展示了模拟复杂真实组织变形的能力
- 通过消融研究强调了失败 episode 数据对于有效学习手术任务仿真的重要性
Card 04
方法描述
方法描述
- 基于 Cosmos-Predict2-2B-Video2World 模型进行外科手术微调,使用 10Hz 采样率、20,000 步训练
- 采用动作条件预测:给定当前状态 s_i 和策略生成的动作序列 a_{i:i+K-1},预测后续 K=12 帧
- 使用 V-JEPA 2(Vision Joint Embedding Predictive Architecture)作为冻结的视频特征提取器,训练 4 层注意力探针分类器进行成功/失败/异常分类
- 自动化评估采用分块处理策略:将长视频分为 32 帧片段(6 帧重叠),逐块分类后根据最早出现的结果确定最终标签
Card 05
数据集与资源
数据集与资源
- 数据集:桌面缝合数据集(3,036 episodes,约13小时)和离体猪胆囊切除数据集(16,506 episodes,约18小时)
- 模型规模:Cosmos-Predict2-2B 参数约 20 亿
- 训练资源:32 块 A100 GPU,Global Batch Size 768,Learning Rate 2.4×10⁻⁴,训练 20,000 步
- 策略模型:π₀、GR00T N1、GR00T N1.5 和 SRT-H
Card 06
评估与结果
评估与结果
- 桌面任务评估:手动评估 Pearson r=0.718(p<0.001),MMRV=0.129;自动化评估 Pearson r=0.756,MMRV=0.10
- 人类一致性:两位标注者 ICC(2,1)=0.811;V-JEPA 2 与人类标注者 ICC=0.836
- 偏差分析:MBE=0.140(手动)和 0.153(自动化),Cosmos-Surg-dVRK 存在正向偏差(倾向于高估成功率)
- 离体胆囊切除:dVRK 7/9 成功,Cosmos-Surg-dVRK 8/9 成功
- 消融实验:不含失败数据的模型 MBE 显著增加到 0.325,证明失败 episode 对学习效果至关重要