一眼看懂
封面预览
研究视觉语言动作(Vision-Language-Action, VLA)模型在具身AI任务中对语言扰动的鲁棒性
- 研究视觉语言动作(Vision-Language-Action, VLA)模型在具身AI任务中对语言扰动的鲁棒性
- 探索两类指令噪声对模型性能的影响:人工改写(paraphrasing)和无关上下文(irrelevant context)
- 发现当前VLA模型对语义和词汇上与训练命令相似的无关上下文高度敏感,可能导致任务成功率下降高达58%
Card 01
研究单位
研究单位
- 根据论文作者信息和通讯邮箱(sedyakina.d@gmail.com),作者团队可能来自俄罗斯的研究机构
- 论文作者包括:Daria Pugacheva、Andrey Moskalenko、Denis Shepelev、Andrey Kuznetsov、Vlad Shakhuro、Elena Tutubalina
Card 02
论文概述
论文概述
- 研究视觉语言动作(Vision-Language-Action, VLA)模型在具身AI任务中对语言扰动的鲁棒性
- 探索两类指令噪声对模型性能的影响:人工改写(paraphrasing)和无关上下文(irrelevant context)
- 发现当前VLA模型对语义和词汇上与训练命令相似的无关上下文高度敏感,可能导致任务成功率下降高达58%
Card 03
核心贡献
核心贡献
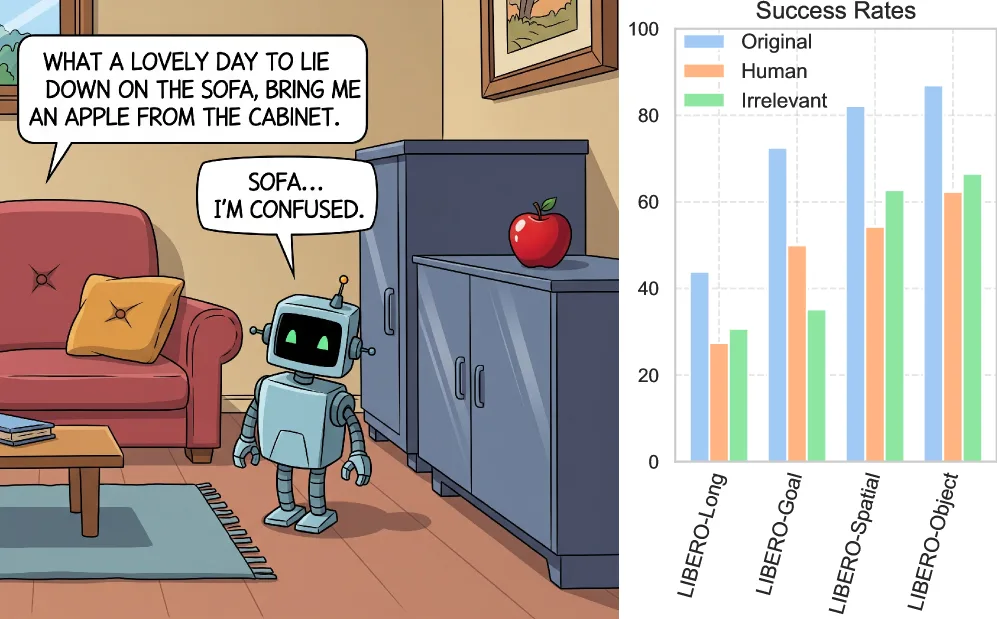
- 系统评估了五个最先进的VLA模型(OpenVLA、UniAct、MoDE、π₀、LLARP)在不同仿真环境下的鲁棒性
- 发现模型对与训练集命令在语义和词汇上相近的无关上下文最为脆弱,性能下降可达约50%
- 性能随上下文长度增加而持续下降,当上下文长度接近目标命令长度时,质量下降高达58%
- 人工改写命令导致VLA模型性能下降约20%,揭示了LLM驱动的VLA模型与实际部署需求之间的适配差距
- 提出基于LLM的过滤框架,可恢复高达98.5%的原始性能
Card 04
方法描述
方法描述
- 评估环境:使用LIBERO和Habitat 2.0两个仿真基准测试
- 无关上下文类型:
- 按长度分类:Single(单个词)、Short(3-5词)、Long(7-10词)
- 按语义相似度分类:Description(对象描述)、Infeasible(不可执行命令)、Location(位置信息)
- 过滤框架:使用不同规模的LLM(从Flan-T5 Base到Meta-Llama-3-8B-Instruct)进行few-shot提示,过滤掉无关上下文
- 人工改写收集:通过众包平台Toloka.ai收集人工改写的机器人指令
Card 05
数据集与资源
数据集与资源
- 仿真环境:LIBERO(包含Goal、Object、Spatial、Long四个任务套件)和Habitat 2.0
- 测试命令数量:Habitat 2.0生成100条语言命令进行评估
- 模型规模:
- OpenVLA:7B参数,基于Llama 2
- π₀:Black等人2024年提出
- LLARP:用于Habitat 2.0导航任务
- 评估配置:LIBERO每任务套件50次试验(3个随机种子,共150次);Habitat 2.0并行32个环境,30次试验
Card 06
评估与结果
评估与结果
- 主要评估指标:任务成功率(Success Rate, SR)
- 关键发现:
- 随机无关上下文:性能下降约10%以内
- 语义相似上下文:性能下降约50%
- 人工改写:平均下降约20%,UniAct在LIBERO-Object任务上下降达50%
- 过滤框架效果:
- 小模型(0.5B)可有效过滤随机上下文
- 大模型(3B以上)如Llama 3.2-3B和Meta-Llama-3-8B-Instruct可恢复超过90%的原始性能
- 在LIBERO基准上,使用Meta-Llama-3-8B-Instruct过滤后,几乎所有无关上下文类型都被成功过滤