一眼看懂
封面预览
提出统一的两阶段标记器 OmniSAT,通过 B-spline 编码进行一致性处理,然后对位置、旋转、夹爪子空间进行分组残差量化,产生粗细粒度…
- 提出统一的两阶段标记器 OmniSAT,通过 B-spline 编码进行一致性处理,然后对位置、旋转、夹爪子空间进行分组残差量化,产生粗细粒度…
- 开发跨实体操作学习策略,在统一的动作模式空间上混合机器人和人类演示数据,实现可扩展的辅助监督
- 在真实机器人和仿真基准上实现一致的压缩效率和下游 VLA 性能提升,训练收敛更快,性能更强
Card 01
研究单位
研究单位
- 中国科学院自动化研究所
- 中国科学院大学
- 中国科学院计算研究所
- 北京人工智能研究院
- 北京大学
- 鹏城实验室
##论文概述
- 论文提出 OmniSAT(Omni Swift Action Tokenizer),旨在解决视觉-语言-动作(VLA)模型中动作标记化的效率问题,特别是针对自回归(AR)模型的压缩需求
- 现有方法(如 FAST、BEAST)在高压缩比下存在重建质量差或域外泛化能力弱的问题;OmniSAT 通过两阶段方法实现 6.8 倍压缩同时保持毫米级重建精度
- 论文进一步探索跨实体操作学习,结合人类演示数据增强模型的泛化能力和可扩展性
Card 02
核心贡献
核心贡献
- 提出统一的两阶段标记器 OmniSAT,通过 B-spline 编码进行一致性处理,然后对位置、旋转、夹爪子空间进行分组残差量化,产生粗细粒度相结合的压缩离散标记
- 开发跨实体操作学习策略,在统一的动作模式空间上混合机器人和人类演示数据,实现可扩展的辅助监督
- 在真实机器人和仿真基准上实现一致的压缩效率和下游 VLA 性能提升,训练收敛更快,性能更强
Card 03
方法描述
方法描述
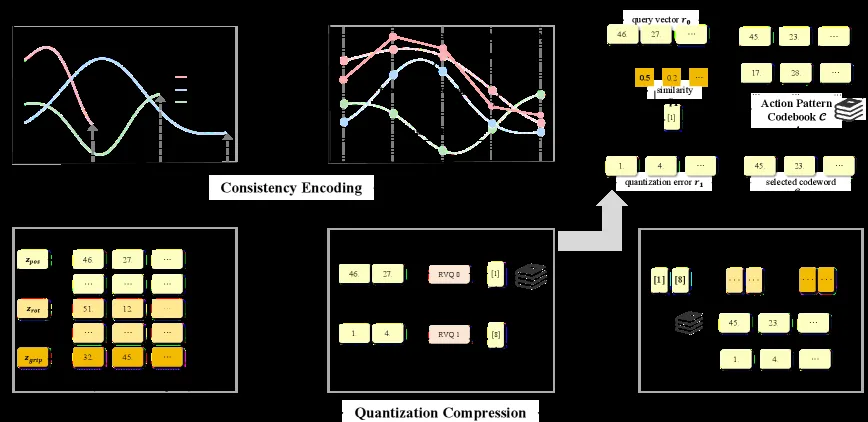
- 一致性编码(Consistency Encoding):使用 B-spline 基矩阵将不同时间范围的轨迹归一化到固定长度的控制点表示,实现数值和时间维度的一致性
- 量化压缩(Quantization Compression):采用残差向量量化 VAE 技术,对位置、旋转、夹爪三个语义组分别进行 L 层残差量化,每层选择最近的码字,最终得到离散标记序列
- 训练目标:包含重建损失、承诺损失和量化层 dropout 损失的组合,确保码本稳定性和表达能力的平衡
Card 04
数据集与资源
数据集与资源
- 预训练数据:Droid 数据集(76k 演示轨迹)
- 真实世界基准:PlaceObj、ZipSeal、TubeRack(自收集)
- 仿真基准:LIBERO(4 个任务套件)、SimplerEnv、RoboCasa、RoboTwin2.0
- 人类演示:EgoDex(200 任务,300k 回合)
- 模型规模:真实世界使用 Emu3-Base(8.5B 参数),仿真使用 Florence-2 Large(0.77B 参数)
- 压缩配置:控制点长度 Tc=8,位置/旋转码本 K=256,夹爪 K=64,残差深度 L=8
Card 05
评估与结果
评估与结果
- 压缩质量:OmniSAT 在 Droid 上达到 6.8×-8.1× 压缩比,MAE 低至 9.4e-4,性能优于 FAST(3.7×)和 BEAST(4.6×)
- LIBERO 基准:平均成功率 93.4%(第一),Object 和 Goal 子任务达到 98.7% 和 94.6%
- SimplerEnv 基准:总体成功率 55.2%,在所有任务上均优于基线
- 真实机器人实验:PlaceObj 73%、ZipSeal 63%、TubeRack 48%;加入人类数据后(OmniSAT-M)提升至 80%、66%、58%
- 收敛效率:OmniSAT 在 2.5k 步达到收敛,比 FAST(3.5k)和 BEAST(4k)更快