一眼看懂
封面预览
该论文是一篇关于视觉-语言-动作(Vision-Language-Action, VLA)模型的综合综述,旨在推动机器人在现实世界中的应用
- 该论文是一篇关于视觉-语言-动作(Vision-Language-Action, VLA)模型的综合综述,旨在推动机器人在现实世界中的应用
- VLA模型通过将视觉、语言和动作数据统一学习,使机器人能够跨不同任务、物体、形态和环境进行泛化
- 论文涵盖VLA的设计策略与架构演进、架构与组件、模态处理技术、学习范式,以及机器人平台、数据集、评估基准等实践内容
Card 01
研究单位
研究单位
- 东京大学工学部情报理工学系(日本东京)
- 牛津大学工程科学系(英国牛津)
- 德克萨斯大学奥斯汀分校计算机科学系(美国德克萨斯州)
Card 02
论文概述
论文概述
- 该论文是一篇关于视觉-语言-动作(Vision-Language-Action, VLA)模型的综合综述,旨在推动机器人在现实世界中的应用
- VLA模型通过将视觉、语言和动作数据统一学习,使机器人能够跨不同任务、物体、形态和环境进行泛化
- 论文涵盖VLA的设计策略与架构演进、架构与组件、模态处理技术、学习范式,以及机器人平台、数据集、评估基准等实践内容
Card 03
核心贡献
核心贡献
- 提供全面的全栈式综述,整合VLA系统的软件和硬件组件
- 系统回顾VLAs的策略与架构转变,包括从早期CNN模型到最新的分层控制框架
- 详细分析七种传感运动模型架构变体及世界模型、仿射模型的设计模式
- 总结训练策略(监督学习、自监督学习、强化学习)和训练阶段(预训练、后训练)
- 整理常用机器人平台、公开数据集、数据增强方法和评估基准
Card 04
方法描述
方法描述
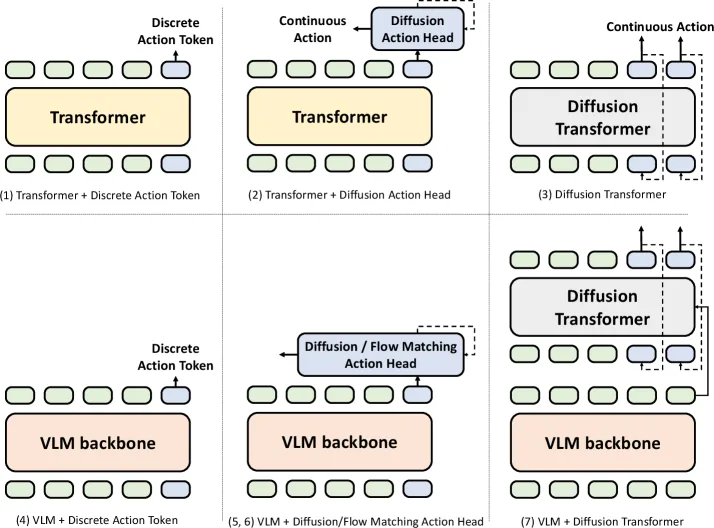
- 设计策略转变:从早期CNN端到端模型(如CLIPort)→ Transformer序列模型(Gato, VIMA)→ 统一真实世界策略(RT系列、OpenVLA)→ 扩散策略(Octo)→ 流匹配策略(π₀)→ 分层策略(RT-H, π₀.₅, GR00T N1)
- 架构分类:传感运动模型(七种变体)、世界模型(三种设计模式)、仿射模型(三种类型)
- 模态处理:视觉(ViT, CLIP, SigLIP, DINOv2)、语言(T5, LLaMA tokenizer)、动作(离散标记、连续动作、扩散/流匹配)
Card 05
数据集与资源
数据集与资源
- 数据集:Open X-Embodiment (OXE)、Ego4D、EPIC-KITCHENS、COCO Captions等
- 模型规模:典型VLA模型参数量从数十亿到上百亿不等(如RDT-1B为10亿参数)
- 训练资源:需要大规模GPU集群进行预训练和微调
Card 06
评估与结果
评估与结果
- 评估基准:涵盖模拟环境和真实机器人平台的多任务评估
- 应用领域:物体操作、运动导航、人形机器人控制、移动操作等
- 主要指标:任务成功率、泛化能力、零样本迁移能力