一眼看懂
封面预览
研究目标:解决现有视觉语言动作(VLA)模型推理成本过高的问题
- 研究目标:解决现有视觉语言动作(VLA)模型推理成本过高的问题
- 核心问题:OpenVLA 等 VLA 模型参数量超过 7B,即使使用 NVIDIA 4090 GPU 也只能达到 6Hz 推理速度
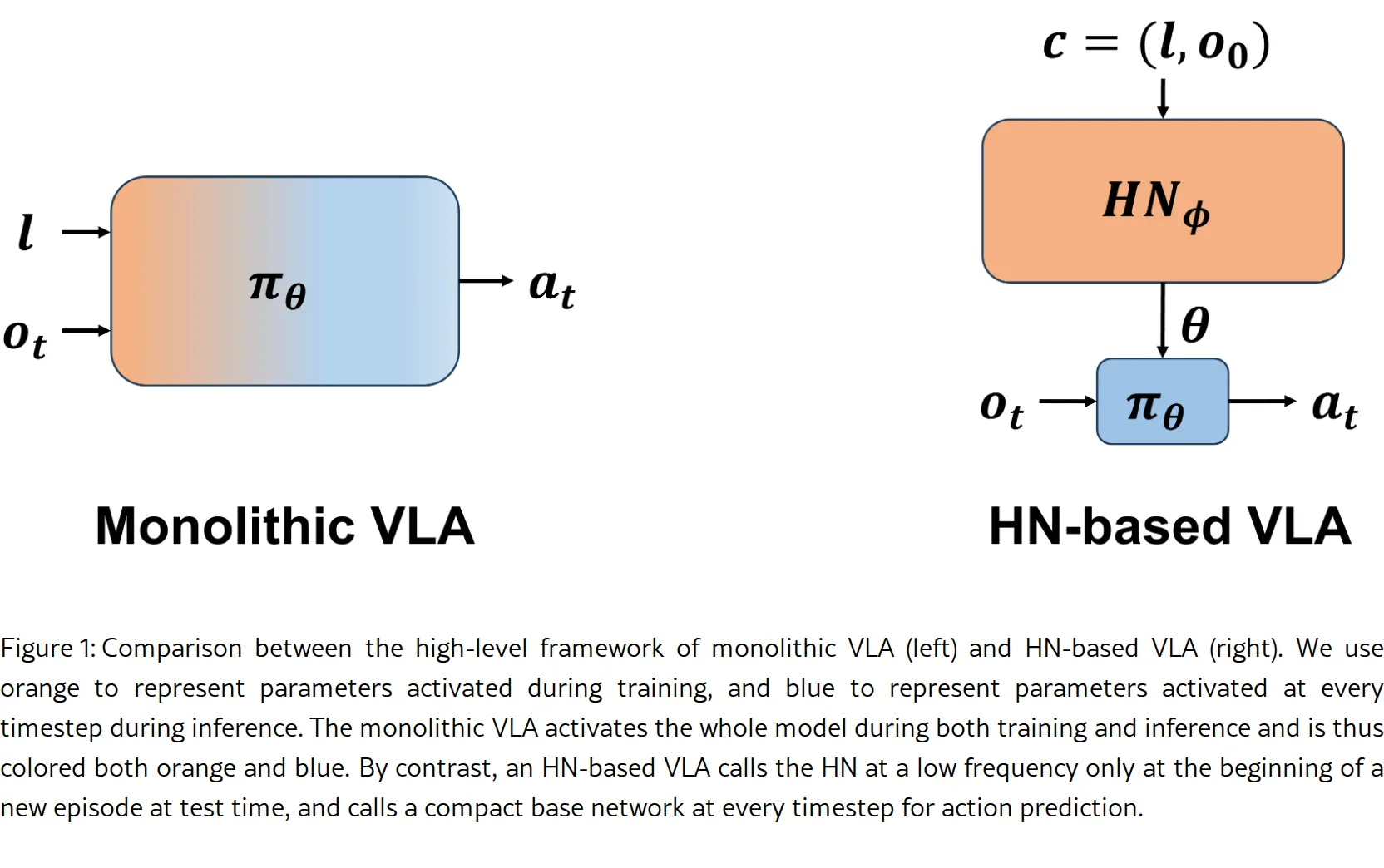
- 解决方案:提出 HyperVLA,利用超网络(Hypernetwork)架构,在推理时仅激活紧凑的任务特定策略
Card 01
研究单位
研究单位
- University of Oxford(牛津大学)
- 作者:Zheng Xiong, Kang Li, Zilin Wang, Matthew Jackson, Jakob Foerster, Shimon Whiteson
Card 02
论文概述
论文概述
- 研究目标:解决现有视觉语言动作(VLA)模型推理成本过高的问题
- 核心问题:OpenVLA 等 VLA 模型参数量超过 7B,即使使用 NVIDIA 4090 GPU 也只能达到 6Hz 推理速度
- 解决方案:提出 HyperVLA,利用超网络(Hypernetwork)架构,在推理时仅激活紧凑的任务特定策略
Card 03
核心贡献
核心贡献
- 提出基于超网络的 VLA 架构,推理时仅激活小型任务专用策略,显著降低推理成本
- 设计三项关键算法设计特征以稳定超网络训练:视觉骨干网(使用 DINOv2 预训练模型)、上下文嵌入归一化、线性动作头
- 在零样本泛化和少样本适应任务上达到与 monolithic VLAs 相似的性能
- 相比 OpenVLA,推理参数量减少 90 倍,推理速度提升 120 倍
- 训练成本大幅降低:HyperVLA 只需 4 张 A5000 GPU 训练一天,而 OpenVLA 需要 64 张 A100 GPU 训练 14 天
Card 04
方法描述
方法描述
- 基础策略:基于 Vision Transformer (ViT),包含 DINOv2 图像编码器、线性投影层、4 层 Transformer 策略头、线性动作头
- 超网络:使用 T5 编码指令、DINOv2 编码初始图像,通过 Transformer 上下文编码器生成基础策略参数
- 上下文嵌入归一化:将上下文嵌入除以 √d_e 以稳定超网络训练
- 动作生成策略:使用简单的线性动作头配合 MSE 损失训练
Card 05
数据集与资源
数据集与资源
- 训练数据:Open X-Embodiment (OXE) 数据集
- 评估基准:SIMPLER(Google Robot 和 WidowX 机器人)、LIBERO(4 个任务套件)
- 训练配置:100k 步,batch size 256,4 张 A5000 GPU 训练一天
Card 06
评估与结果
评估与结果
- 零样本泛化(SIMPLER):HyperVLA 在 Google Robot 平均成功率 63%,WidowX 平均 40%,整体性能与 OpenVLA 相当
- 少样本适应(LIBERO):HyperVLA 平均成功率 89%,显著优于 Octo(75%)和 OpenVLA(77%)
- 推理效率:
- 推理激活参数量:86M(共享)+ 0.1M(生成)
- 推理速度:每步 4ms(NVIDIA L4 GPU)
- 相比 OpenVLA 加速 120 倍
- 消融实验:验证了视觉骨干网、上下文归一化、线性动作头三个设计均对性能有贡献