一眼看懂
封面预览
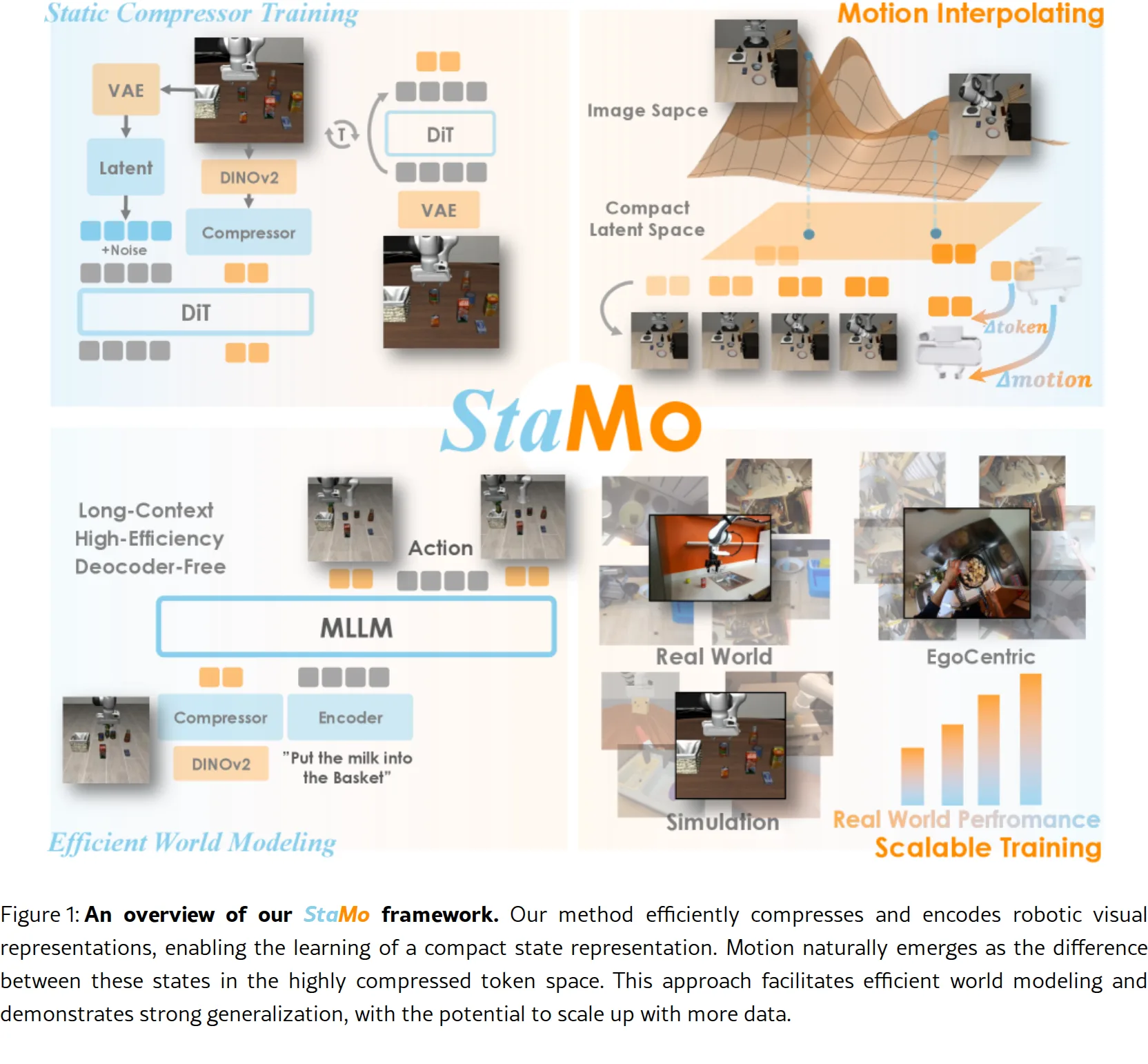
提出 StaMo 框架,从静态图像中学习高度紧凑的两 token 状态表示,使用轻量级编码器结合预训练的 Diffusion Transfor…
- 提出 StaMo 框架,从静态图像中学习高度紧凑的两 token 状态表示,使用轻量级编码器结合预训练的 Diffusion Transfor…
- 发现该表示中 token 之间的差异(通过潜在插值获得)自然地表示运动,可解码为可执行的机器人动作,无需显式的运动监督
- 挑战了从视频数据学习复杂时间建模的流行范式,证明了从单帧学习足够表达性的状态表示可使简单差异自然封装有意义的潜在动作
Card 01
研究单位
研究单位
- 浙江大学 (Zhejiang University)
- 南京大学 (Nanjing University)
- 香港科技大学 (Hong Kong University of Science and Technology)
Card 02
论文概述
论文概述
- 提出 StaMo 框架,从静态图像中学习高度紧凑的两 token 状态表示,使用轻量级编码器结合预训练的 Diffusion Transformer (DiT) 解码器
- 发现该表示中 token 之间的差异(通过潜在插值获得)自然地表示运动,可解码为可执行的机器人动作,无需显式的运动监督
- 挑战了从视频数据学习复杂时间建模的流行范式,证明了从单帧学习足够表达性的状态表示可使简单差异自然封装有意义的潜在动作
Card 03
核心贡献
核心贡献
- 提出 StaMo 框架,从静态图像中编码紧凑状态表示,运动从中自然涌现
- 该表示可用于高效世界建模,并作为连接视觉语言模型 (VLM) 和动作专家模块的中间表示,可无缝集成到现有 VLM 框架中
- 运动提取方法具有更强的泛化能力和优秀的可迁移性,可用于联合训练下游模型和目标图像规划任务
- 在模拟和真实世界的全面实验表明方法有效,可随数据增加轻松扩展
Card 04
方法描述
方法描述
- 使用 Diffusion Autoencoder 架构:编码器由预训练的 DINOv2(冻结特征提取器)+ 基于 Transformer 的压缩器组成,解码器是来自 Stable Diffusion 3 的 DiT (Diffusion Transformer)
- 将图像压缩为仅 2 个 1024 维 tokens 的紧凑潜在状态
- 使用 Flow Matching 目标训练模型
- 运动通过状态差异自然表示:$a_t = s_{t+1} - s_t$
- 与 OpenVLA 集成时,添加 MLP 头预测下一状态,采用复合损失函数:$L_{total} = \lambda_{action}L_{action} + \lambda_{future}(L_{mse} + L_{1})$
Card 05
数据集与资源
数据集与资源
- 数据集:LIBERO (libero_10, libero_90, libero_goal, libero_object, libero_spatial)、DROID、Maniskill (OOD)、Open X-Embodiment、人类自我中心视频
- 模型规模:使用 2 个 1024 维 tokens,可选 256/512/1024 隐藏维度
- 训练资源:8 张 NVIDIA H100 GPU,训练约 10 天,AdamW 优化器,初始学习率 3e-5,批量大小 512/GPU
- 推理开销:OpenVLA + StaMo 推理频率 4.02 Hz,与 OpenVLA (4.16 Hz) 几乎相同
Card 06
评估与结果
评估与结果
- LIBERO 基准:OpenVLA + StaMo state 达到 86.0% 平均准确率(+14.3%),OpenVLA-OFT + StaMo state 达到 94.0% 平均准确率
- 策略联合训练 (RDT 架构):StaMo 达到 84.6% 平均准确率,优于 ATM (73.4%) 和 LAPA (74.2%),提升 10.4%
- 线性探针实验:StaMo 在 1/2/4/8 步预测中均达到最低 MSE,持续优于基线方法
- 真实世界实验:6 个任务(3 短 horizon + 3 长 horizon),OpenVLA + StaMo 达到 67% 整体成功率,相比 OpenVLA (25%) 提升 30%
- 重建质量:PSNR 20-31 dB,SSIM 0.73-0.95,取决于数据集
- 可扩展性:随模拟、真实机器人数据和人类自我中心数据规模增加,性能稳步提升