一眼看懂
封面预览
研究如何将视觉语言模型(VLM)的规划和推理能力转化为物理世界的机器人动作,解决传统视觉语言动作(VLA)模型在稀缺、窄领域数据上微调后泛化能…
- 研究如何将视觉语言模型(VLM)的规划和推理能力转化为物理世界的机器人动作,解决传统视觉语言动作(VLA)模型在稀缺、窄领域数据上微调后泛化能…
- 提出使用稀疏3D轨迹作为中间表示,搭建VLM高层规划与动作专家低层执行之间的桥梁,实现"思考"与"行动"的真正解耦
- 目标是实现无需任务特定微调的零样本部署,使动作专家能够泛化到新环境和物体
Card 01
研究单位
研究单位
- 浙江大学(Zhejiang University):Mingyu Liu, Zheng Huang, Xiaoyi Lin, Muzhi Zhu, Canyu Zhao, Zongze Du, Hao Chen, Chunhua Shen
- 上海人工智能实验室(Shanghai Artificial Intelligence Laboratory):Yating Wang, Haoyi Zhu
Card 02
论文概述
论文概述
- 研究如何将视觉语言模型(VLM)的规划和推理能力转化为物理世界的机器人动作,解决传统视觉语言动作(VLA)模型在稀缺、窄领域数据上微调后泛化能力差的问题
- 提出使用稀疏3D轨迹作为中间表示,搭建VLM高层规划与动作专家低层执行之间的桥梁,实现"思考"与"行动"的真正解耦
- 目标是实现无需任务特定微调的零样本部署,使动作专家能够泛化到新环境和物体
Card 03
核心贡献
核心贡献
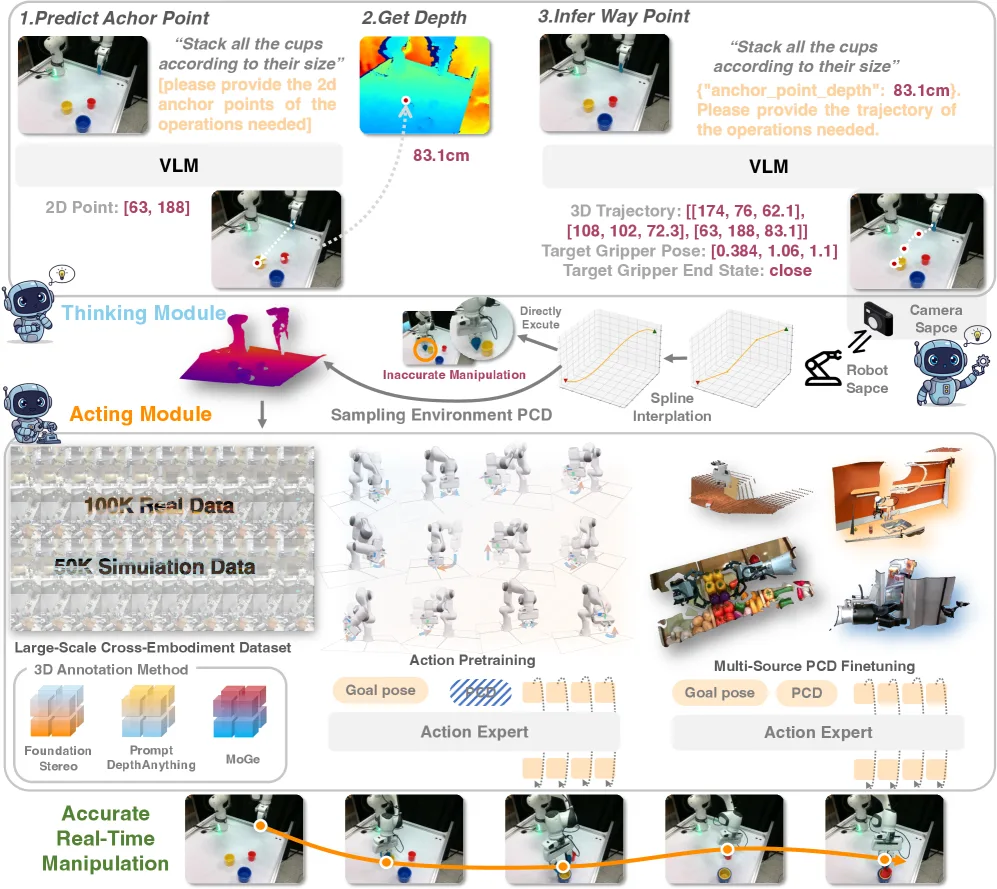
- 首次提出基于可泛化动作专家的框架,使用稀疏3D轨迹作为清晰接口,完全解耦VLM高层规划与低层电机控制,实现零样本部署
- 提出"动作预训练-点云微调"(Action Pre-training, Pointcloud Fine-tuning)策略,使动作专家专注于几何轨迹细化而非语义解释
- 系统展现出强大的多视觉域、相机视角和自然语言指令泛化能力,在长程任务中达到60%平均成功率
- 创新性地在相机帧中预测路标点,保持VLM的视觉中心先验知识,避免学习复杂的相机到机器人坐标转换
Card 04
方法描述
方法描述
- VLM规划阶段:VLM仅需生成粗略的3D路标点(waypoints),利用深度信息从2D锚点推理3D坐标,保留语言和推理能力
- 轨迹生成:使用B样条(B-spline)插值将稀疏路标点转换为连续平滑的末端执行器姿态轨迹
- 可泛化动作专家:基于3D Diffusion Policy架构的条件扩散模型,输入包括机器人本体状态、引导姿态和点云观测
- 两阶段训练:第一阶段在大批量纯轨迹数据上预训练(batch size可达31,824),第二阶段使用点云数据进行微调
- 在引导姿态中加入噪声(scale=0.1)模拟VLM生成轨迹的变异性,提高专家泛化能力
Card 05
数据集与资源
数据集与资源
- 模拟数据集:RoboTwin、CALVIN、LIBERO、RLBench,共50k轨迹
- 真实数据集:DROID(76,000条轨迹)、AgiBot World(10,000条)、BridgeV2(14,000条)
- 深度增强技术:FoundationStereo用于DROID,PromptDepthAnything用于AgiBot,MoGe用于BridgeV2
- 训练硬件:8块80GB NVIDIA A100 GPU
- VLM微调:1000步,batch size 32
- 动作专家训练:预训练2天(batch size 32,768)+ 微调3天(batch size 256)
Card 06
评估与结果
评估与结果
- 基准测试:RoboTwin(11个任务)和ManiSkill模拟环境,以及真实世界Frank机器人平台
- 主要指标:任务成功率
- 关键结果:
- 短程任务:81%平均成功率(与DP3专家模型持平)
- 中程任务:73%平均成功率(超越所有基线)
- 长程任务:60%平均成功率(显著领先,Pi0仅14%)
- 零样本泛化:新颜色/物体/语义任务显著超越Pi0基线
- 视角泛化:域外视角性能下降最小(仅2-8%)
- 真实机器人:6个任务平均78.3%成功率(VLM+DP(PromptDepth)设置)