一眼看懂
封面预览
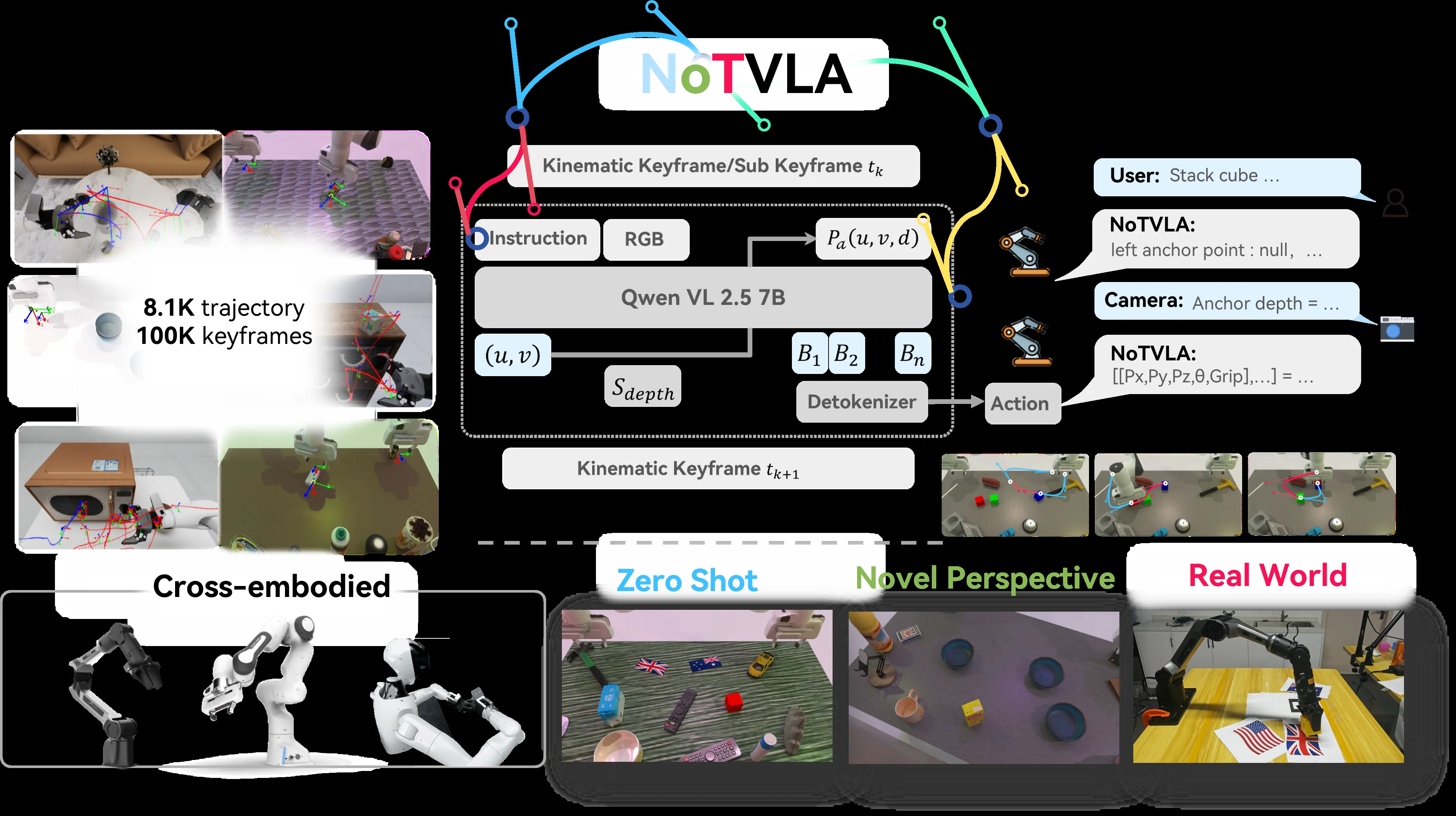
NoTVLA 是一种用于通用机器人操作的新型 Vision-Language-Action (VLA) 框架,旨在解决 VLA 模型中的灾难性…
- NoTVLA 是一种用于通用机器人操作的新型 Vision-Language-Action (VLA) 框架,旨在解决 VLA 模型中的灾难性…
- 核心思路是将传统的密集动作轨迹(dense action trajectories)压缩为稀疏的关键帧轨迹(sparse trajectori…
- 该方法同时实现了高效的计算资源利用:在计算量比 π₀ 少一个数量级的前提下,仍能保持接近单任务专家模型的精度
Card 01
研究单位
研究单位
- 浙江大学 (Zhejiang University)
Card 02
论文概述
论文概述
- NoTVLA 是一种用于通用机器人操作的新型 Vision-Language-Action (VLA) 框架,旨在解决 VLA 模型中的灾难性遗忘问题
- 核心思路是将传统的密集动作轨迹(dense action trajectories)压缩为稀疏的关键帧轨迹(sparse trajectories),避免因重复微调密集轨迹而导致的知识遗忘
- 该方法同时实现了高效的计算资源利用:在计算量比 π₀ 少一个数量级的前提下,仍能保持接近单任务专家模型的精度
Card 03
核心贡献
核心贡献
- 提出解耦高层 VLM 与底层动作专家的架构,在显著降低微调计算成本的同时,提高具身任务成功率
- 引入基于运动学的关键帧选择(Kinematics-Based Keyframe Selection),通过稀疏化、语义剪枝的轨迹监督增强跨 embodiment 和跨任务的泛化能力,缓解灾难性遗忘
- 设计了基于锚点的深度推理(Anchor-Based Depth Inference)和样条动作去分词器(Spline-Based Action Detokenizer),分别简化 3D 感知和生成平滑高频控制轨迹
- 保持 VLM 的语言理解和推理能力,支持零样本泛化到新指令、新物体和新场景,以及跨机器人平台部署
Card 04
方法描述
方法描述
- Anchor Point Prediction (APP):给定 RGB 图像和语言指令,预测图像中任务相关的 2D 锚点坐标 $(u_a, v_a)$
- Depth Acquisition:从外部深度传感器或单目深度估计器获取锚点深度 $d_a$,组合为三维锚点 $a = (u_a, v_a, d_a)$
- Anchor-Conditioned Token Generation (ACTG):以图像、语言和深度增强锚点为条件,自回归生成包含深度、图像 UV、夹爪状态和姿态的动作 token 序列
- Kinematics-Based Keyframe Selection:根据末端执行器加速度阈值和夹爪状态切换来选取关键帧,将密集轨迹压缩为稀疏关键帧序列,并在关键帧间插值生成子关键帧
- Spline-Based Action Detokenizer:使用三次样条插值(cubic spline)对位置进行平滑,用球面线性插值(SLERP)对四元数姿态进行插值,将低频关键帧转换为高频平滑轨迹
Card 05
数据集与资源
数据集与资源
- 训练数据:整合三个数据源共 8.1K 条轨迹,约 100K 关键帧
- ManiSkill:3000 条轨迹(3 个任务)
- RoboTwin 2.0:2000 条轨迹(40 个任务)
- AGIBOT World:500 条轨迹(10 个任务)
- 私有数据集:1000+ 条轨迹
- 模型规模:基于 Qwen VL 2.5 (7B) 作为 VLM 主干
- 支持的机器人平台:Aloha-AgileX、ARX-X5、Franka Panda、UR5、PiPER、AGIBOT G1 等
- 训练成本:RoboTwin 训练仅需 32 GPU 小时
Card 06
评估与结果
评估与结果
- RoboTwin 2.0 基准:在多任务场景下,NoTVLA 在多个操作任务上成功率超越 π₀、RDT 等通用 VLA 模型,例如 click bell 达到 94%、press stapler 达到 94%、handover mic 达到 99%
- AGIBOT Challenge:官方评测总分 3.697,超越 UniVLA 的 2.795,特别是在 "Open drawer and store items" 和 "Pickup items from the freezer" 任务上提升显著
- 零样本泛化:在逆向指令(stack red on green)、新颜色组合(stack random color blocks)、抽象概念(flags)等未见场景中,NoTVLA 达到 57-78% 成功率,显著优于 π₀ 的 0-32%
- 跨视角泛化:在训练时未见过的新相机视角下,性能仅轻微下降(如 Stack block three 从 0.35 降至 0.31),展现良好的视角不变性
- 训练效率:相比其他 VLA 模型,NoTVLA 无需单任务微调,训练步数大幅减少,同时保持更高的平均成功率