一眼看懂
封面预览
论文提出Caption-Guided Retrieval System (CGRS),解决跨模态无人机导航问题,即根据自然语言描述从大规模图像…
- 论文提出Caption-Guided Retrieval System (CGRS),解决跨模态无人机导航问题,即根据自然语言描述从大规模图像…
- 核心挑战在于弥合人类语言描述与航拍视角视觉表示之间的语义鸿沟,现有基线方法难以实现细粒度语义匹配
- 该研究针对IROS 2025 RoboSense Challenge Track 4竞赛,目标是实现稳健的自然语言引导跨视图图像检索,支持无人…
Card 01
研究单位
研究单位
- 清华大学 (Tsinghua University) - Lingfeng Zhang, Wenbo Ding
- 小米汽车 (Xiaomi EV) - Lingfeng Zhang, Yuchen Zhang, Long Chen, Hangjun Ye, Xiaoshuai Hao
- 香港科技大学广州 (HKUSTGZ) - Erjia Xiao
- 佐治亚理工学院 (Georgia Institute of Technology) - Yuchen Zhang
- 新加坡国立大学 (National University of Singapore) - Haoxiang Fu
- 香港中文大学 (The Chinese University of Hong Kong) - Ruibin Hu
- 中国人民大学 (Renmin University of China) - Yanbiao Ma
Card 02
论文概述
论文概述
- 论文提出Caption-Guided Retrieval System (CGRS),解决跨模态无人机导航问题,即根据自然语言描述从大规模图像库中检索相关无人机航拍图像
- 核心挑战在于弥合人类语言描述与航拍视角视觉表示之间的语义鸿沟,现有基线方法难以实现细粒度语义匹配
- 该研究针对IROS 2025 RoboSense Challenge Track 4竞赛,目标是实现稳健的自然语言引导跨视图图像检索,支持无人机、卫星和地面摄像头多平台数据
Card 03
核心贡献
核心贡献
- 提出CGRS两阶段粗到细检索框架,利用视觉语言模型弥合自然语言查询与航拍图像之间的语义鸿沟
- 引入Caption-guided重排序机制,将跨模态匹配转换为文本到文本的相似度计算,实现复杂航拍场景中更细粒度的语义对齐
- 相比基线方法在所有关键指标上实现一致约5%提升(Recall@1、Recall@5、Recall@10)
- 在IROS 2025 RoboSense挑战赛跨模态无人机导航赛道中荣获TOP-2(共8支参赛队伍)
Card 04
方法描述
方法描述
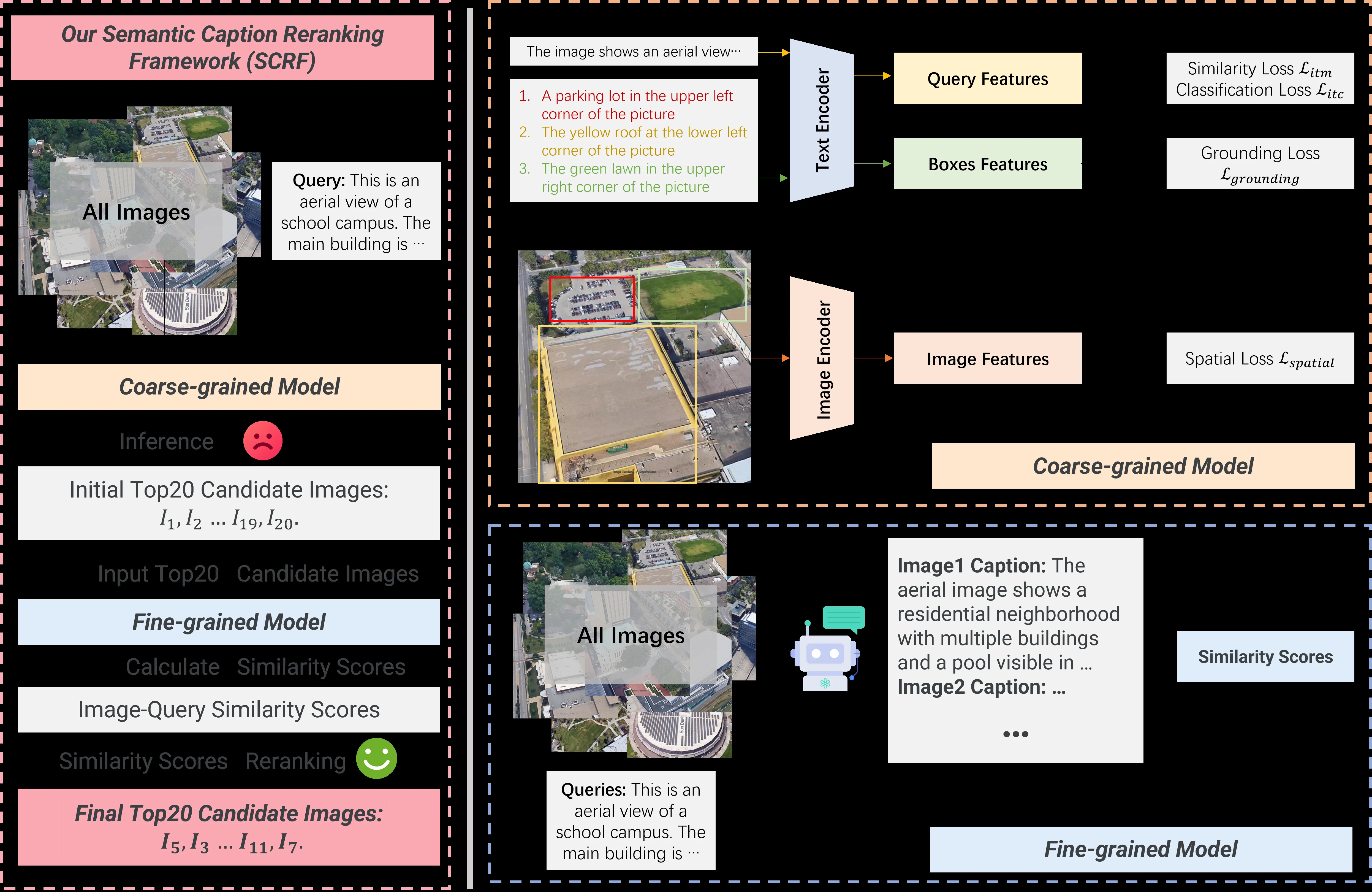
- 两阶段Pipeline:第一阶段使用GeoText-1652基线模型进行粗粒度检索,获取Top 20候选图像;第二阶段使用VLM生成详细图像描述Caption,通过文本-文本相似度进行细粒度重排序
- 粗粒度模型:采用Swin Transformer作为图像编码器,BERT作为文本编码器,使用对比学习(ITM/ITC)、视觉定位和空间关系预测进行训练
- 细粒度重排序:使用GPT-4o生成空间感知的详细Caption,使用BERT计算语义相似度,最终融合粗粒度和细粒度相似度(权重α=0.3)
- 核心创新:将跨模态匹配问题转化为更易处理的文本到文本相似度计算任务
Card 05
数据集与资源
数据集与资源
- 数据集:GeoText-1652数据集,训练集包含50,218张图像(来自33所大学),测试集包含54,227张图像(来自39所大学);每张图像平均3个全局描述和2.62个区域级描述
- 模型规模:基线模型使用Swin Transformer + BERT架构
- 训练资源:8块NVIDIA A800 GPU训练5个epoch,约30 GPU小时;Caption生成约12小时离线时间
Card 06
评估与结果
评估与结果
- 评估指标:Recall@1、Recall@5、Recall@10
- 竞赛结果:在IROS 2025 RoboSense Challenge Track 4中排名第二(R@1=31.33%, R@5=49.09%, R@10=57.15%)
- 相比基线提升:R@1提升5.89%,R@5提升8.48%,R@10提升8.05%
- 定性分析:VLM能够准确捕捉航拍图像中的细粒度空间细节和语义关系,如足球场标记、太阳能电池板布局、停车场与体育设施的区分等