一眼看懂
封面预览
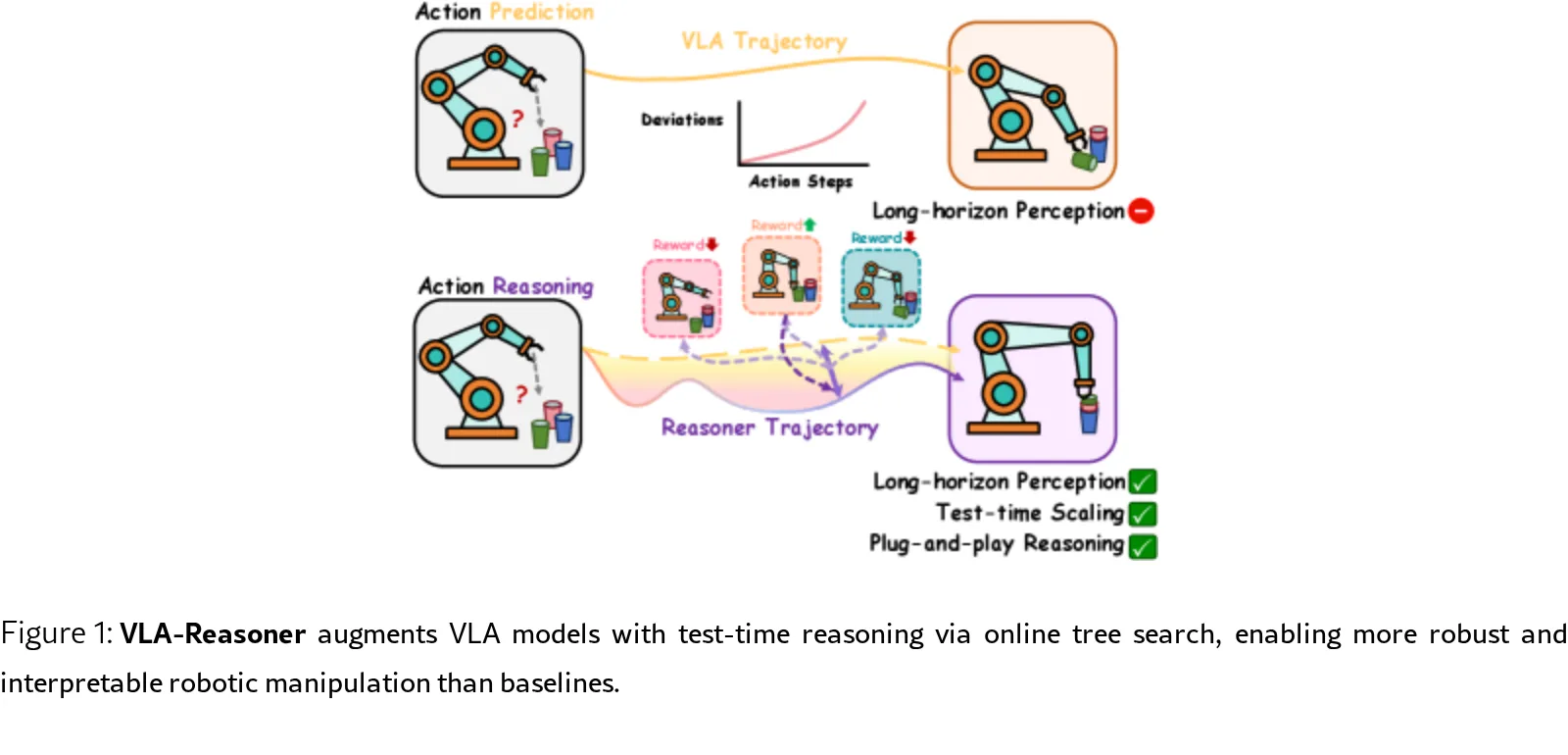
VLA-Reasoner 是一个即插即用的框架,通过在线蒙特卡洛树搜索(MCTS)增强视觉语言动作模型(VLA)的推理能力,解决VLA在长程轨…
- VLA-Reasoner 是一个即插即用的框架,通过在线蒙特卡洛树搜索(MCTS)增强视觉语言动作模型(VLA)的推理能力,解决VLA在长程轨…
- 核心思想是利用世界模型模拟未来状态,结合MCTS在动作空间中进行高效搜索,通过离线价值估计评估中间状态,提供密集的反馈信号来纠正偏差
- 该方法可在测试时扩展计算,无需大规模后训练即可显著提升现有VLA的性能
Card 01
研究单位
研究单位
- 南洋理工大学 (Nanyang Technological University) - 电气与电子工程学院
- 清华大学 (Tsinghua University) - 深圳国际研究生院
- 北京邮电大学 (Beijing University of Posts and Telecommunications) - 智能工程与自动化学院
Card 02
论文概述
论文概述
- VLA-Reasoner 是一个即插即用的框架,通过在线蒙特卡洛树搜索(MCTS)增强视觉语言动作模型(VLA)的推理能力,解决VLA在长程轨迹任务中因短视预测导致的累积偏差问题
- 核心思想是利用世界模型模拟未来状态,结合MCTS在动作空间中进行高效搜索,通过离线价值估计评估中间状态,提供密集的反馈信号来纠正偏差
- 该方法可在测试时扩展计算,无需大规模后训练即可显著提升现有VLA的性能
Card 03
核心贡献
核心贡献
- 提出VLA-Reasoner插件框架,赋予VLA结构化推理能力,解决部署时的累积偏差问题
- 将修改后的MCTS应用于测试时推理,使用KDE进行高效采样,并设计基于离线数据的价值估计方法评估中间状态
- 在模拟环境和真实机器人上进行了广泛实验,验证了方法的有效性,在LIBERO基准上超越OpenVLA-SFT等先进VLA模型
Card 04
方法描述
方法描述
- 在线蒙特卡洛树搜索(MCTS):通过展开、模拟、反向传播和选择四个步骤,在动作空间中构建搜索树,利用VLA预测作为根节点
- 基于KDE的高效采样:使用核密度估计(KDE)从离线数据中学习动作分布,在MCTS扩展阶段高效采样候选动作,避免重复查询VLA
- 视觉价值估计:采用ResNet-34作为视觉编码器,通过2层MLP训练MSE损失,对MCTS中的中间状态进行价值评估
- 动作注入机制:将MCTS搜索得到的最优动作与VLA预测通过加权融合(公式:$a_t = \alpha \cdot a_t^{VLA} + (1-\alpha) \cdot a_t^{Reasoner}$)生成最终执行动作
Card 05
数据集与资源
数据集与资源
- 模拟环境:LIBERO基准(包含Spatial、Goal、Object、Long四个任务套件)和SimplerEnv
- 真实机器人任务:5个真实世界任务(Block、Fruit、1 Cup、2 Cups、Circle)
- 基础VLA模型:OpenVLA-7B、Octo-Small (27M参数)、SpatialVLA-4B
- 世界模型:基于iVideoGPT架构训练的动作感知世界模型(600M参数)
- 训练资源:6块NVIDIA RTX 6000 GPU
Card 06
评估与结果
评估与结果
- 模拟环境(LIBERO):VLA-Reasoner将OpenVLA-SFT平均成功率从76%提升至81%,在Spatial任务上达91.2%,在Long任务上达59.8%
- 模拟环境(SimplerEnv):将Octo-Small从26.5%提升至37.3%,SpatialVLA从34%提升至41.8%
- 真实世界:将OpenVLA成功率从22%提升至41%(相对提升86.4%),将π₀-FAST从64%提升至74%(相对提升15.6%)
- 消融实验:最优注入强度α=0.6,KDE采样和价值估计均对性能提升有显著贡献