一眼看懂
封面预览
研究 Vision-Language-Action (VLA) 模型在真实世界中面对多模态扰动的鲁棒性问题
- 研究 Vision-Language-Action (VLA) 模型在真实世界中面对多模态扰动的鲁棒性问题
- 评估了主流 VLA 模型在 17 种扰动(4 个模态:动作、观测、环境、指令)下的鲁棒性表现
- 发现现有视觉鲁棒的 VLA 方法仅能提升视觉模态的鲁棒性,无法泛化到其他模态
Card 01
研究单位
研究单位
- 北京航空航天大学 (Beihang University)
- 北京大学 (Peking University)
- 香港中文大学 (The Chinese University of Hong Kong)
- PKU-Psibot Lab
- 清华大学 (Tsinghua University)
- 中关村实验室 (Zhongguancun Laboratory)
- 合肥综合性国家科学中心 (Hefei Comprehensive National Science Center)
Card 02
论文概述
论文概述
- 研究 Vision-Language-Action (VLA) 模型在真实世界中面对多模态扰动的鲁棒性问题
- 评估了主流 VLA 模型在 17 种扰动(4 个模态:动作、观测、环境、指令)下的鲁棒性表现
- 发现现有视觉鲁棒的 VLA 方法仅能提升视觉模态的鲁棒性,无法泛化到其他模态
- 提出 RobustVLA 框架,同时增强 VLA 输入和输出的鲁棒性
Card 03
核心贡献
核心贡献
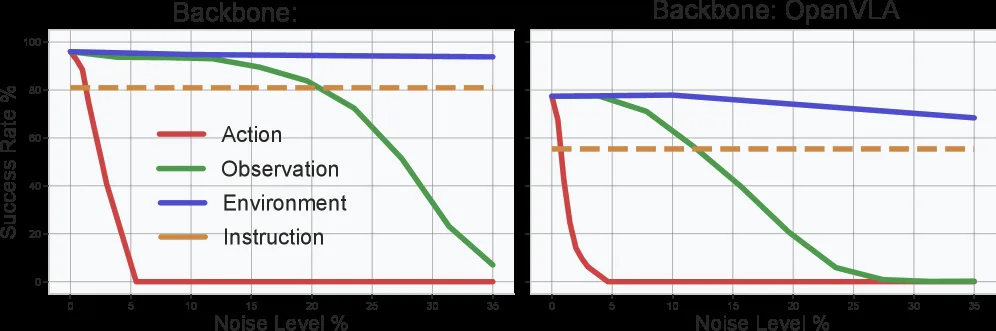
- 首次全面评估 VLA 在多模态噪声下的鲁棒性,发现动作模态最为脆弱
- 提出 RobustVLA 方法,在 π₀ backbone 上获得 12.6% 绝对提升,在 OpenVLA 上获得 10.4% 提升
- 推理速度比基于外部 LLM 的 BYOVLA 快 50.6 倍
- 在混合扰动下获得 10.4% 鲁棒性提升
- 真实世界实验中,使用 25 个演示即可超越 π₀ 达 65.6% 成功率
Card 04
方法描述
方法描述
- 输出鲁棒性:从 flow matching 目标函数推导最坏情况动作噪声,通过 PGD 生成对抗扰动,可理解为对抗训练 + 标签平滑 + 异常值惩罚的组合
- 输入鲁棒性:确保噪声不改变任务语义,最优动作保持不变,正则化输出动作在输入扰动下保持一致
- 多扰动平衡:将扰动选择建模为多臂老虎机问题,使用 UCB 算法 自动识别最有害的噪声类型进行对抗训练
- 基于 π₀ 的 rectified flow matching 动作头,支持泛化到其他扩散-based VLA 和自回归 VLA
Card 05
数据集与资源
数据集与资源
- 评估基准:LIBERO benchmark
- 测试扰动数量:17 种(动作 5 种、观测 6 种、环境 3 种、指令 3 种)
- 模型 backbone:π₀、π₀-FAST、OpenVLA
- 真实机器人:Fairino FR5 机械臂 + ZED2 外部相机 + Intel RealSense 435i 手腕相机
Card 06
评估与结果
评估与结果
- 模拟环境:在 LIBERO 上,RobustVLA 在 π₀ backbone 上平均成功率 76.6%(vs π₀ 的 62.6%)
- 各模态提升:动作扰动平均 +8.0%,输入扰动平均 +17.2%
- 消融实验:输入正则化和输出正则化相互增益,UCB 对平衡多扰动至关重要(下降 7.3%)
- 推理效率:~11 秒/轮次 vs BYOVLA 的 ~556 秒/轮次
- 真实世界:25 个演示下超越 π₀ 达 65.6%;100 个演示下仍超越 π₀ 达 30%