一眼看懂
封面预览
提出 Asynchronous Action Chunk Correction (A2C2),一种轻量级实时动作块校正机制,用于解决视觉-语言…
- 提出 Asynchronous Action Chunk Correction (A2C2),一种轻量级实时动作块校正机制,用于解决视觉-语言…
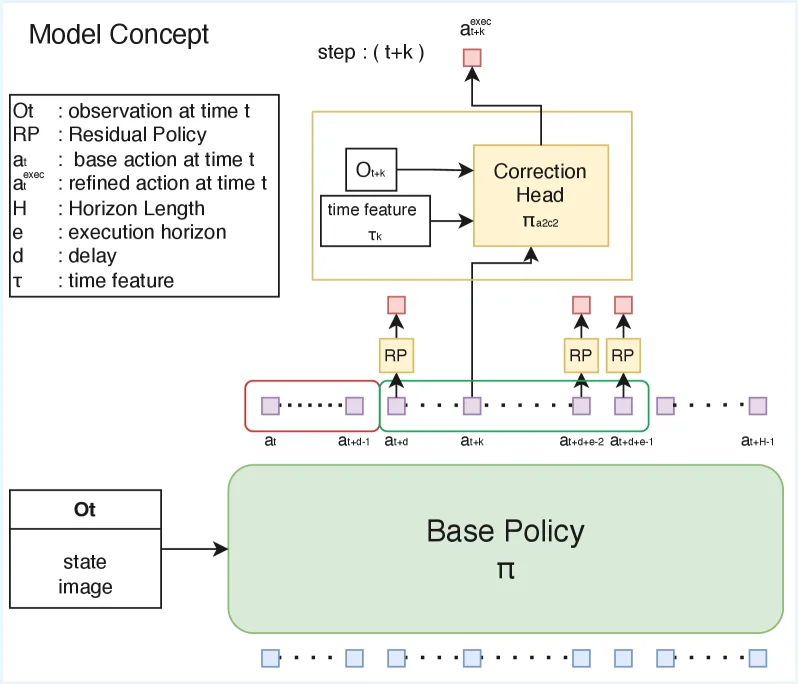
- 核心思想是在每个控制步骤运行一个轻量校正头,结合最新观测、基础策略预测的动作、时序位置特征和基础策略特征,输出残差修正量
- 解决大型 VLA 模型(如 π₀、OpenVLA、SmolVLA)因推理延迟导致的开环执行误差累积问题
Card 01
研究单位
研究单位
- The University of Tokyo (东京大学)
Card 02
论文概述
论文概述
- 提出 Asynchronous Action Chunk Correction (A2C2),一种轻量级实时动作块校正机制,用于解决视觉-语言-动作 (VLA) 模型在推理延迟和长时域执行下的反应性问题
- 核心思想是在每个控制步骤运行一个轻量校正头,结合最新观测、基础策略预测的动作、时序位置特征和基础策略特征,输出残差修正量
- 解决大型 VLA 模型(如 π₀、OpenVLA、SmolVLA)因推理延迟导致的开环执行误差累积问题
Card 03
核心贡献
核心贡献
- 形式化定义了 VLA 动作块策略中的推理延迟问题,明确延迟 d、执行时域 e 和动作块长度 H 的关系
- 提出 A2C2 插件式校正头,无需重新训练基础策略,可与任意现成 VLA 模型结合
- 引入时间感知校正机制,通过正弦位置编码 τₖ 显式建模动作在块内的位置
- 在动态任务 Kinetix (12个任务) 和机器人操作基准 LIBERO Spatial 上验证,在延迟和长时域设置下分别提升 +23% 和 +7% 成功率
- 校正头参数量仅 0.31M (Kinetix) 和 32M (LIBERO),推理开销极小
Card 04
方法描述
方法描述
- 两阶段训练流程:先训练基础策略 π,再用基础策略输出构建校正数据集训练 π_a2c2
- 校正头输入:最新观测 o_{t+k}、基础动作 a^{base}_{t+k}、时序特征 τₖ、基础策略表征 z_{t+k}、语言指令 l
- 残差学习:预测残差动作 Δa_{t+k},与基础动作相加得到执行动作 a^{exec}_{t+k} = a^{base}_{t+k} + Δa_{t+k}
- 架构设计:Kinetix 使用 3层 MLP (512隐藏单元);LIBERO 使用 6层 Transformer 编码器 + 3层 MLP
- 正弦位置编码:τₖ = (sin(2πk/H), cos(2πk/H)) 提供块内位置的周期性结构
Card 05
数据集与资源
数据集与资源
- Kinetix:12个动态任务,每任务100万步专家数据,状态维度2722,动作维度6
- LIBERO Spatial:10个空间推理任务,432条演示,52,970帧,包含顶部/腕部RGB图像 (256×256)、8维状态、语言指令
- 基础模型:Kinetix 使用流匹配策略;LIBERO 使用 SmolVLA (450M参数)
- 训练资源:使用 AdamW 优化器,Kinetix 批次大小512,LIBERO 批次大小64
- 开源代码:https://github.com/k1000dai/a2c2-kinetix 和 https://github.com/k1000dai/a2c2-libero
Card 06
评估与结果
评估与结果
- Kinetix 评估:2048次 rollout/任务,测试延迟 d∈{0,1,2,3,4} 和执行时域 e∈{1,...,8} 的组合
- d=4 时,A2C2 比朴素异步提升 ~35%,比 RTC 提升 ~23%
- 长时域 H=7 时,成功率保持 85% 以上
- LIBERO Spatial 评估:10任务×10 rollout (初步),50 rollout/任务 (精确评估)
- H=40, d=10 时,A2C2 成功率 84.2% vs 朴素 64.4%
- H=50, d=0 时,A2C2 成功率 81.6% vs 朴素 72.2%
- 关键指标:任务成功率 (Success Rate)
- 对比基线:Naïve async (朴素异步)、RTC (Real Time Chunking)