一眼看懂
封面预览
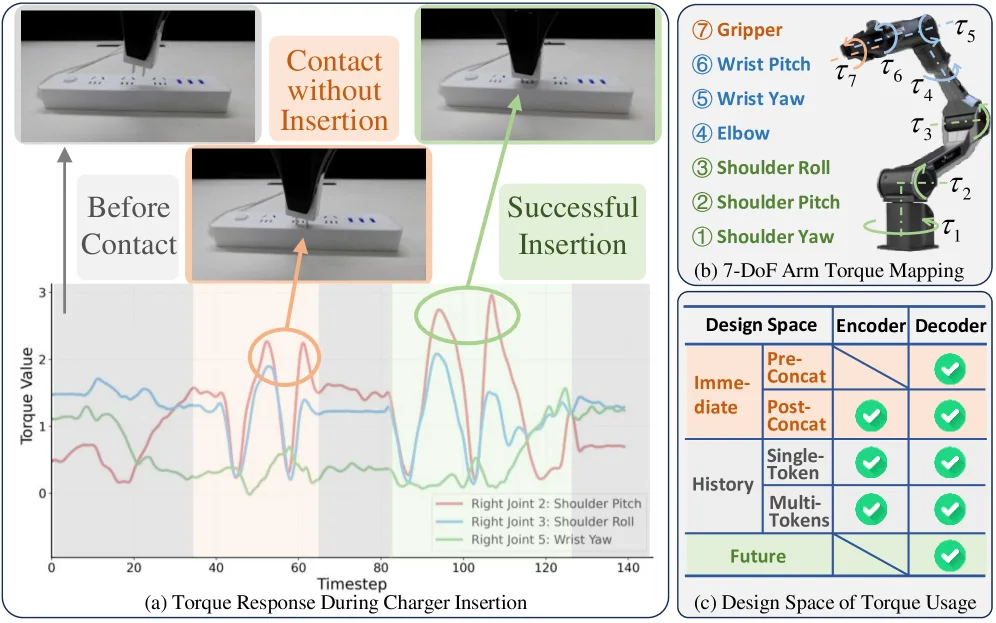
探索如何将扭矩信号(torque)系统性地集成到视觉-语言-动作(VLA)模型中,以提升接触丰富型机器人操作任务的性能
- 探索如何将扭矩信号(torque)系统性地集成到视觉-语言-动作(VLA)模型中,以提升接触丰富型机器人操作任务的性能
- 解决当前VLA模型缺乏力觉反馈感知能力的问题,使机器人能够通过关节扭矩信号感知末端执行器的接触状态
- 通过理论分析和大量实验,阐明了扭矩感知VLA模型的设计空间,包括信号嵌入位置、历史信息编码方式以及预测目标的设计
Card 01
研究单位
研究单位
- 北京人工智能研究院 (BAAI)
- 清华大学智能产业研究院 (AIR, Tsinghua University)
- 南洋理工大学 (Nanyang Technological University)
Card 02
论文概述
论文概述
- 探索如何将扭矩信号(torque)系统性地集成到视觉-语言-动作(VLA)模型中,以提升接触丰富型机器人操作任务的性能
- 解决当前VLA模型缺乏力觉反馈感知能力的问题,使机器人能够通过关节扭矩信号感知末端执行器的接触状态
- 通过理论分析和大量实验,阐明了扭矩感知VLA模型的设计空间,包括信号嵌入位置、历史信息编码方式以及预测目标的设计
Card 03
核心贡献
核心贡献
- 提出系统性的扭矩感知VLA模型设计框架,涵盖"何时/何处/如何"三个维度的设计选择
- 发现解码器侧单令牌嵌入是最佳实践:将扭矩历史聚合为单个令牌嵌入解码器,而非编码器,以保持架构稳定性和感知对齐
- 提出统一动作-扭矩扩散模型:将未来扭矩预测作为辅助任务,构建物理感知的隐式表示空间
- 在10项真实机器人任务中验证,尤其在接触丰富任务(如充电器插入、按钮按压)上实现显著性能提升
- 证明方法具有良好的跨模型(π₀、RDT)和跨本体(Cobot Magic ALOHA、ROKAE SR)泛化能力
Card 04
方法描述
方法描述
- 基于扩散策略的VLA架构,以π₀和RDT为基线模型
- 扭矩作为观测(Observations):通过MLP适配器将扭矩历史编码为单令牌,嵌入解码器(DePost架构),与关节角等本体感受信号融合
- 扭矩作为目标(Objectives):采用联合扩散损失 L_joint = L_action + β·L_torque,同时预测未来动作块和扭矩块,增强物理动态理解
- 利用HSIC分析验证扭矩与关节角信号的高度相关性,支持解码器嵌入策略
- 通过准静态简化从电机电流实时估计关节扭矩,无需额外力觉传感器
Card 05
数据集与资源
数据集与资源
- 硬件平台:Cobot Magic ALOHA双臂机器人(7自由度/臂),配备D435深度相机
- 评估任务:10项真实世界任务(5项接触丰富型:按钮按压、充电器插入、USB插入、插座拔出、门把手旋转;5项常规任务)
- 基线模型:ACT、RDT-1B、π₀(基于PaliGemma的流匹配VLA模型)
- 扭矩信号从电机电流实时计算:τ = k_t · i,利用电流-扭矩常数转换
Card 06
评估与结果
评估与结果
- 评估指标:任务成功率(20次试验)
- 关键结果:完整方法(π₀+obs+obj)在接触丰富任务上显著超越基线
- 按钮按压:18/20 vs. π₀基线 5/20
- 充电器插入:17/20 vs. π₀基线 0/20
- USB插入:17/20 vs. π₀基线 0/20
- 消融验证:解码器嵌入(DePost)优于编码器嵌入(Enc)和前拼接嵌入(DePre);单令牌历史编码优于多令牌帧级编码
- 跨模型验证:RDT+obs+obj在按钮按压上从4/20提升至16/20
- 跨本体验证:在ROKAE SR机械臂上成功实现充电器插入任务