一眼看懂
封面预览
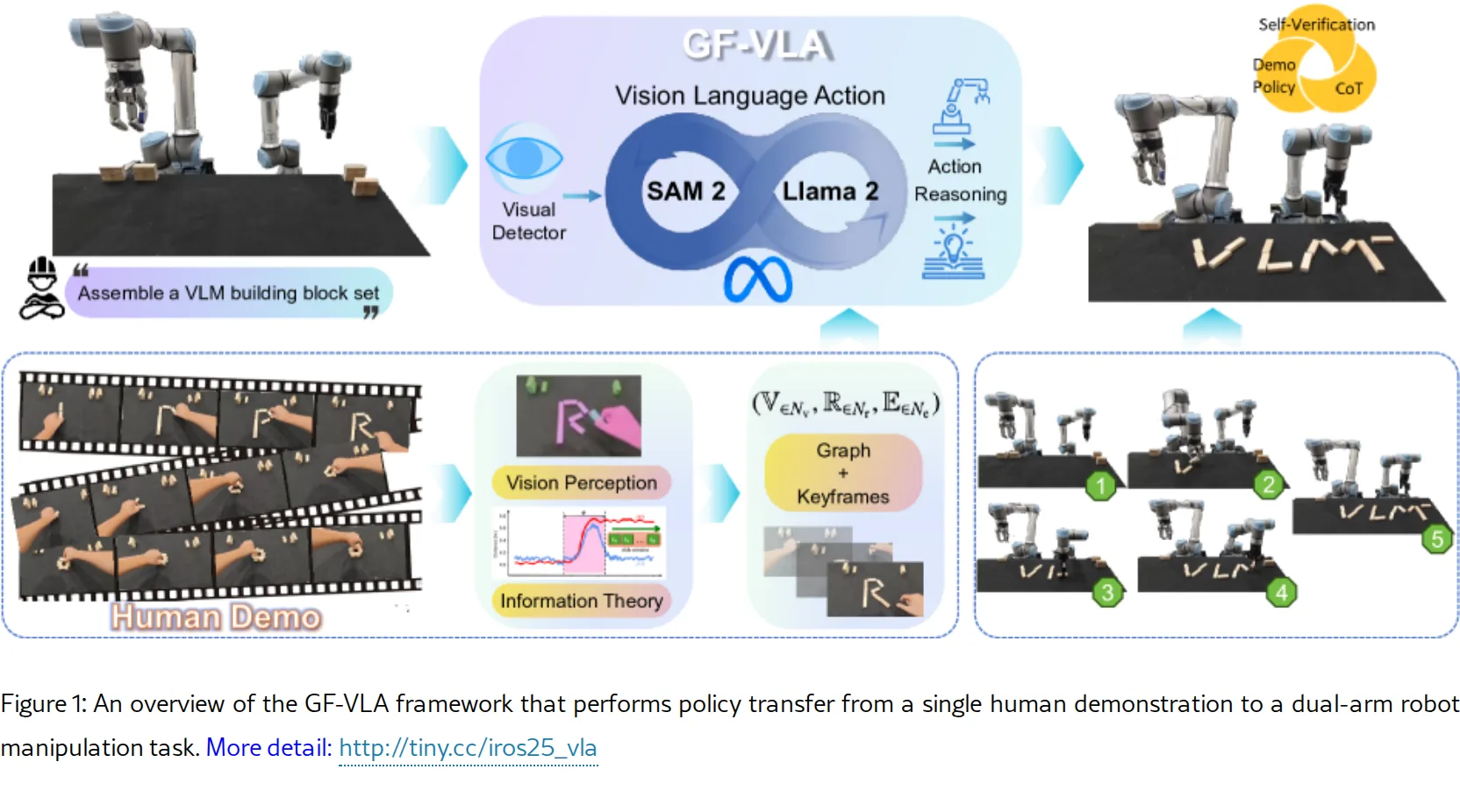
提出 GF-VLA(Graph-Fused Vision-Language-Action) 统一框架,使双臂机器人能够从单个人类RGB-D演示…
- 提出 GF-VLA(Graph-Fused Vision-Language-Action) 统一框架,使双臂机器人能够从单个人类RGB-D演示…
- 解决传统基于低层轨迹模仿的方法在跨物体、跨空间布局和跨机械臂配置泛化性不足的问题
- 通过信息论方法提取任务相关线索,构建时序场景图,并与语言条件Transformer融合生成可解释的行为树和笛卡尔运动基元
Card 01
研究单位
研究单位
- Hangzhou Dianzi University(杭州电子科技大学):Shunlei Li, Jiuwen Cao(浙江省机器学习与智能健康国际合作基地、人工智能研究院)
- The University of New Mexico:Longsen Gao(电气与计算机工程系)
- Technical University of Munich(慕尼黑工业大学):Yingbai Hu(计算、信息与技术学院)
Card 02
论文概述
论文概述
- 提出 GF-VLA(Graph-Fused Vision-Language-Action) 统一框架,使双臂机器人能够从单个人类RGB-D演示视频中直接进行任务级推理和执行
- 解决传统基于低层轨迹模仿的方法在跨物体、跨空间布局和跨机械臂配置泛化性不足的问题
- 通过信息论方法提取任务相关线索,构建时序场景图,并与语言条件Transformer融合生成可解释的行为树和笛卡尔运动基元
Card 03
核心贡献
核心贡献
- 提出信息论方法从多模态人类演示中构建结构化场景图,显式编码动态物理交互(手-物交互HO、物-物交互OO)
- 首创 GF-VLA 统一框架,将结构化交互建模与VLA推理相结合,实现鲁棒且可泛化的操作
- 将 Chain-of-Thought(CoT)提示 嵌入VLA模型,提供透明的子目标分解并提高执行可靠性
- 提出跨臂分配策略,无需显式几何建模即可自主确定夹爪分配,优化双臂执行效率
Card 04
方法描述
方法描述
- 信息论场景图生成:使用香农熵和互信息量化信号不确定性,通过滑动时间窗口检测手-物耦合运动(Coupled-Motion/Docked)和物-物交互(E-OO/T-OO)
- 统一双头架构:基于 LLaMA-2(7B参数) 主干,集成LLM Head(高层语义规划与CoT推理)和Action Head(低层运动控制)
- 动态双手选择策略:结合对侧先验策略(contralateral prior)与学习的MLP分类器,通过加权交叉熵优化实现双臂角色分配
- 参数高效微调:采用 LoRA 适配器分别微调LLM Head和Action Head,冻结视觉编码器和投影器
Card 05
数据集与资源
数据集与资源
- 人类演示数据集:250段RGB视频(10名参与者),涵盖字母符号组装和塔楼构建任务
- 机器人执行数据集:240次双臂试验(UR5e + Robotiq 2F-85 和 UR10e + Barrett BH282),4类任务 × 3种形状 × 20次重复
- 训练资源:单张 NVIDIA RTX 4090,约40小时微调,bfloat16推理延迟7.56秒
Card 06
评估与结果
评估与结果
- 评估基准:四类双臂积木操作任务(形状泛化、空间关系歧义、绝对6D位姿执行、相对位姿执行)及六项策略迁移变体
- 主要评估指标:图表示准确率(GRA)、任务分割准确率(TSA)、抓取成功率(GSR)、放置成功率(PSR)、6D位姿误差(6DPE)、指令符合度(ICS)、任务成功率(TSR)、双臂协调评分(BCS)、策略可迁移率(PTR)
- 关键实验结果:
- 图表示准确率 >95%,子任务分割准确率 93%
- 抓取可靠性 94%,放置准确率 89%,整体任务成功率 90%
- 形状泛化任务:GSR 98%,PSR 95%,6DPE 1.2cm + 2.5°
- 策略迁移:单演示泛化至6项新任务,TSR达 90%,PTR ≥83%