一眼看懂
封面预览
提出 OccVLA(Occupancy Vision-Language-Action),一种将3D占用表示融入统一多模态推理过程的新型框架,用…
- 提出 OccVLA(Occupancy Vision-Language-Action),一种将3D占用表示融入统一多模态推理过程的新型框架,用…
- 针对两个关键挑战:(1)无需昂贵人工标注即可构建可访问且有效的3D表示;(2)通过大规模3D视觉-语言预训练保留细粒度空间细节
- 将密集3D占用同时作为预测输出和监督信号,使模型仅通过2D视觉输入即可学习细粒度空间结构
Card 01
研究单位
研究单位
- Shanghai Qi Zhi Institute(上海期智研究院)
- Xi'an Jiaotong University(西安交通大学)
- Fudan University(复旦大学)
- Shanghai Jiao Tong University(上海交通大学)
- Tsinghua University(清华大学)
Card 02
论文概述
论文概述
- 提出 OccVLA(Occupancy Vision-Language-Action),一种将3D占用表示融入统一多模态推理过程的新型框架,用于解决自动驾驶中多模态大语言模型(MLLMs)缺乏鲁棒3D空间理解能力的问题
- 针对两个关键挑战:(1)无需昂贵人工标注即可构建可访问且有效的3D表示;(2)通过大规模3D视觉-语言预训练保留细粒度空间细节
- 将密集3D占用同时作为预测输出和监督信号,使模型仅通过2D视觉输入即可学习细粒度空间结构
Card 03
核心贡献
核心贡献
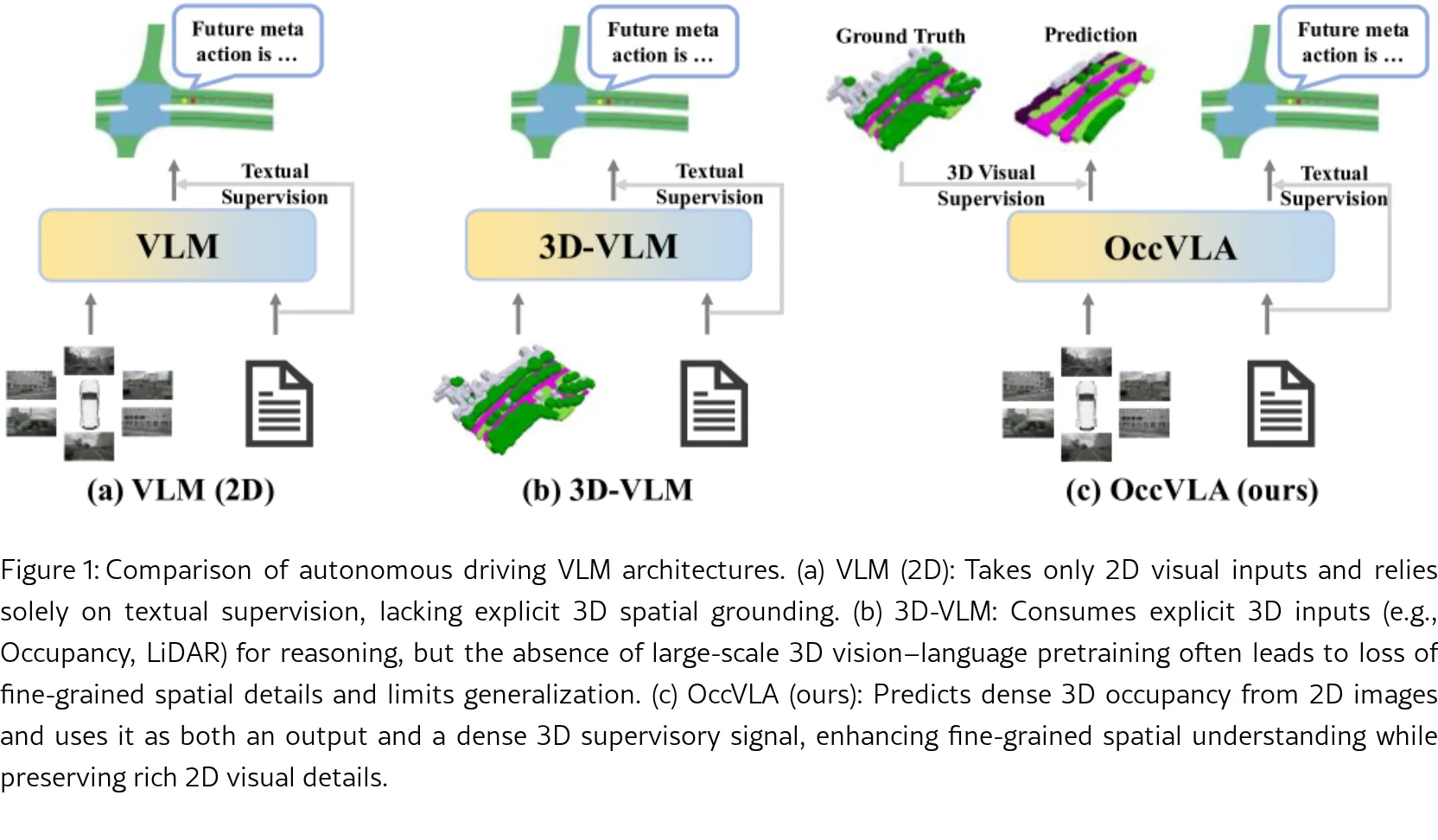
- 提出OccVLA框架,通过占用预测过程扩展视觉语言模型(VLMs)的3D推理能力,同时有效保留来自2D图像的视觉信息
- 设计跨模态注意力机制,允许模型在推理阶段跳过占用预测过程,不引入额外计算复杂度
- 在端到端轨迹规划和3D视觉问答(VQA)任务上取得优异性能,在nuScenes公开基准上达到最先进结果
- 提供可扩展、可解释且完全基于视觉的自动驾驶解决方案,占用预测在推理时可选择性激活
- 仅用3B参数模型超越7B参数竞品(如OccLLaMA),展现更强的实际应用潜力
Card 04
方法描述
方法描述
- 架构设计:基于共享的Vision-Language-Occupancy(V-L-O)骨干网络,统一3D占用预测和语言建模
- 占用预测模块:使用可学习的占用查询通过交叉注意力从VLM中间层获取视觉特征;采用紧凑隐空间预测解决占用稀疏性问题,通过VQ-VAE解码器映射回高分辨率占用空间
- 运动规划:将任务分解为元动作预测(速度动作+方向动作)和轨迹生成两阶段;使用GPT-4o自动生成思维链(CoT)训练数据,轻量级MLP规划头将元动作转换为未来轨迹坐标
- 三阶段训练:阶段1为自动驾驶场景VLM预训练;阶段2为占用-语言联合训练;阶段3为规划头训练
- 关键创新:占用令牌作为隐式推理过程,推理时可跳过;采用非自回归占用损失与自回归文本损失的联合优化
Card 05
数据集与资源
数据集与资源
- nuScenes:700个训练场景,150个验证场景,用于运动规划评估
- Occ3D:基于nuScenes传感器信息的大规模3D占用数据集
- NuScenes-QA:46万问答对,用于3D定位、物体查询和关系比较等VQA任务评估
- OmniDrive数据集:用于VLM预训练
- 模型规模:Paligemma2-3B-224px作为视觉语言模型骨干,场景VQVAE初始化自OccWorld
- 训练资源:8× NVIDIA A800 GPUs,使用AdamW优化器
Card 06
评估与结果
评估与结果
- 运动规划(nuScenes):平均L2距离0.28m,优于EMMA(0.32m)和OmniDrive(0.33m);1s/2s/3s L2距离分别为0.18m/0.26m/0.40m,在2s和3s上达到最优
- 与占用输入方法对比:仅使用相机输入(C)达到与使用真值占用输入(Occ-LLM)相当性能(平均0.28m vs 0.28m),显著优于其他相机输入方法
- NuScenes-QA:总体准确率59.5%,超越LLaVA(47.4%)、LiDAR-LLM(48.6%)、OccLLaMA3.1(54.5%)和OpenDriveVLA(58.2%);在exist(84.3%)、object(54.5%)、status(59.5%)、comparison(67.2%)等子任务上取得最优或次优
- 占用预测:mIoU约10%,对车道、车辆、行人等关键元素预测准确,但受限于单时间步输入在处理遮挡区域时的局限
- 消融实验:占用监督使元动作预测性能提升约1.5%;自车轨迹信息显著改善规划性能(平均L2从0.48m降至0.28m)