一眼看懂
封面预览
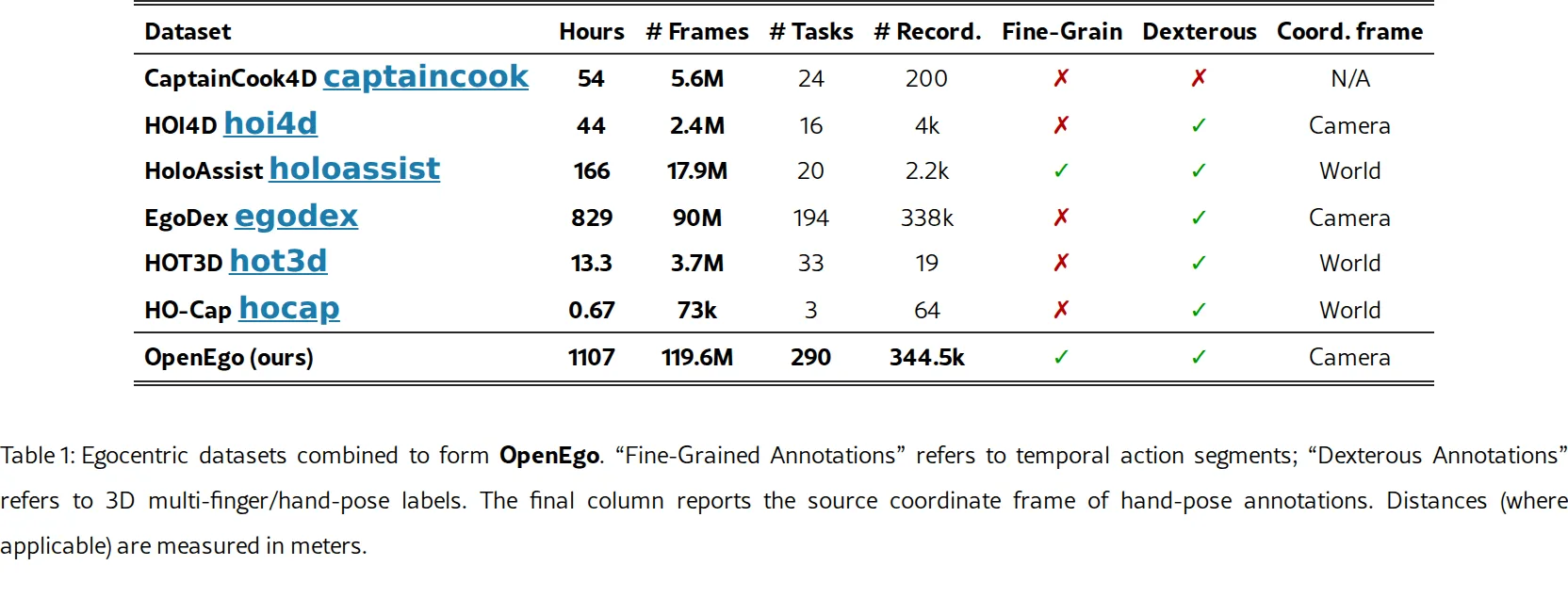
论文提出 OpenEgo,一个大规模多模态第一人称视角(egocentric)灵巧操作数据集,旨在解决现有数据集缺乏细粒度时间定位动作描述和灵…
- 论文提出 OpenEgo,一个大规模多模态第一人称视角(egocentric)灵巧操作数据集,旨在解决现有数据集缺乏细粒度时间定位动作描述和灵…
- 通过整合六个公开数据集,提供标准化的21关节手部姿态标注和意图对齐的动作原语语言描述,支持从第一人称视频学习灵巧操作
- 验证数据集有效性:训练语言条件化的模仿学习策略来预测3D手部轨迹
Card 01
研究单位
研究单位
- The University of Texas at Dallas (Department of Computer Science)
- Physical Automation, Inc.
Card 02
论文概述
论文概述
- 论文提出 OpenEgo,一个大规模多模态第一人称视角(egocentric)灵巧操作数据集,旨在解决现有数据集缺乏细粒度时间定位动作描述和灵巧手部标注的问题
- 通过整合六个公开数据集,提供标准化的21关节手部姿态标注和意图对齐的动作原语语言描述,支持从第一人称视频学习灵巧操作
- 验证数据集有效性:训练语言条件化的模仿学习策略来预测3D手部轨迹
Card 03
核心贡献
核心贡献
- 构建统一的大规模第一人称操作数据集,包含 1107小时 视频、290个 操作任务、600+ 环境,覆盖厨房任务、装配和日常活动
- 标准化 MANO 21关节 手部姿态格式(每根手指4个关节加腕部),统一转换到相机坐标系
- 提供意图对齐的语言动作原语,包含描述性动作、操作对象、绝对时间戳(t_start, t_end)和手部标签
- 建立针对灵巧3D手部轨迹预测的评估协议,验证数据集可用于训练世界模型、分层VLA和基础VLM模型
- 整合六个现有数据集(CaptainCook4D、HOI4D、HoloAssist、EgoDex、HOT3D、HO-Cap),填补规模化灵巧标注与细粒度语言原语兼得的空白
Card 04
方法描述
方法描述
- 手部姿态统一处理:将所有来源的手部姿态对齐到MANO 21关节布局,转换到相机坐标系;对于缺乏3D标注的数据(CaptainCook4D),使用 MediaPipe 检测2D关键点并通过深度图反投影
- 坐标系转换:世界坐标系数据(HoloAssist、HOT3D、HO-Cap)通过外参矩阵转换到相机坐标系;EgoDex的25关节格式通过剔除非MANO关节并重索引转换
- 语言原语生成:自动生成描述性动作原语,标注操作对象、动作类型、时间范围、执行手部(左手/右手/双手),区分导航和操作动作
- 策略训练:采用 ViLT(Vision-and-Language Transformer)策略,输入RGB图像、语言指令和当前手部关节,预测未来T步的3D手部轨迹,使用带掩码的MSE损失函数
Card 05
数据集与资源
数据集与资源
- 数据集来源:CaptainCook4D、HOI4D、HoloAssist、EgoDex、HOT3D、HO-Cap
- 规模:总计 119.6M帧、344.5k条 录制、10个厨房 和 610个室内房间、24种烹饪食谱、1.4k个不同物体、至少 258名 独特参与者
- 训练资源:2 × NVIDIA RTX 4090 GPU,批次大小896,约1344万采样训练实例,15,000梯度步,AdamW优化器配合余弦退火学习率调度
- 训练数据量:由于计算限制,仅使用OpenEgo的 0.1% 子集进行训练
Card 06
评估与结果
评估与结果
- 评估环境:10%数据作为留出测试集,避免数据泄漏
- 评估指标:
- AED(Average Euclidean Distance):预测 horizon 内的平均欧氏距离
- FED(Final Euclidean Distance):最终步骤的欧氏距离
- DTW(Dynamic Time Warping):预测与参考关节序列的动态时间规整距离
- 关键实验结果(15 fps预测):
- 8帧(0.5秒):AED=0.0491,FED=0.0633,DTW=0.3918
- 16帧(1.0秒):AED=0.0714,FED=0.0795,DTW=1.1284
- 32帧(2.0秒):AED=0.0893,FED=0.0926,DTW=2.7150
- 64帧(4.0秒):AED=0.1045,FED=0.1076,DTW=6.7975
- 结果分析:短horizon预测误差更低,AED和FED随horizon增加而平滑上升;DTW增长更快,反映时间错位敏感性,表明任务难度随预测horizon平滑扩展