一眼看懂
封面预览
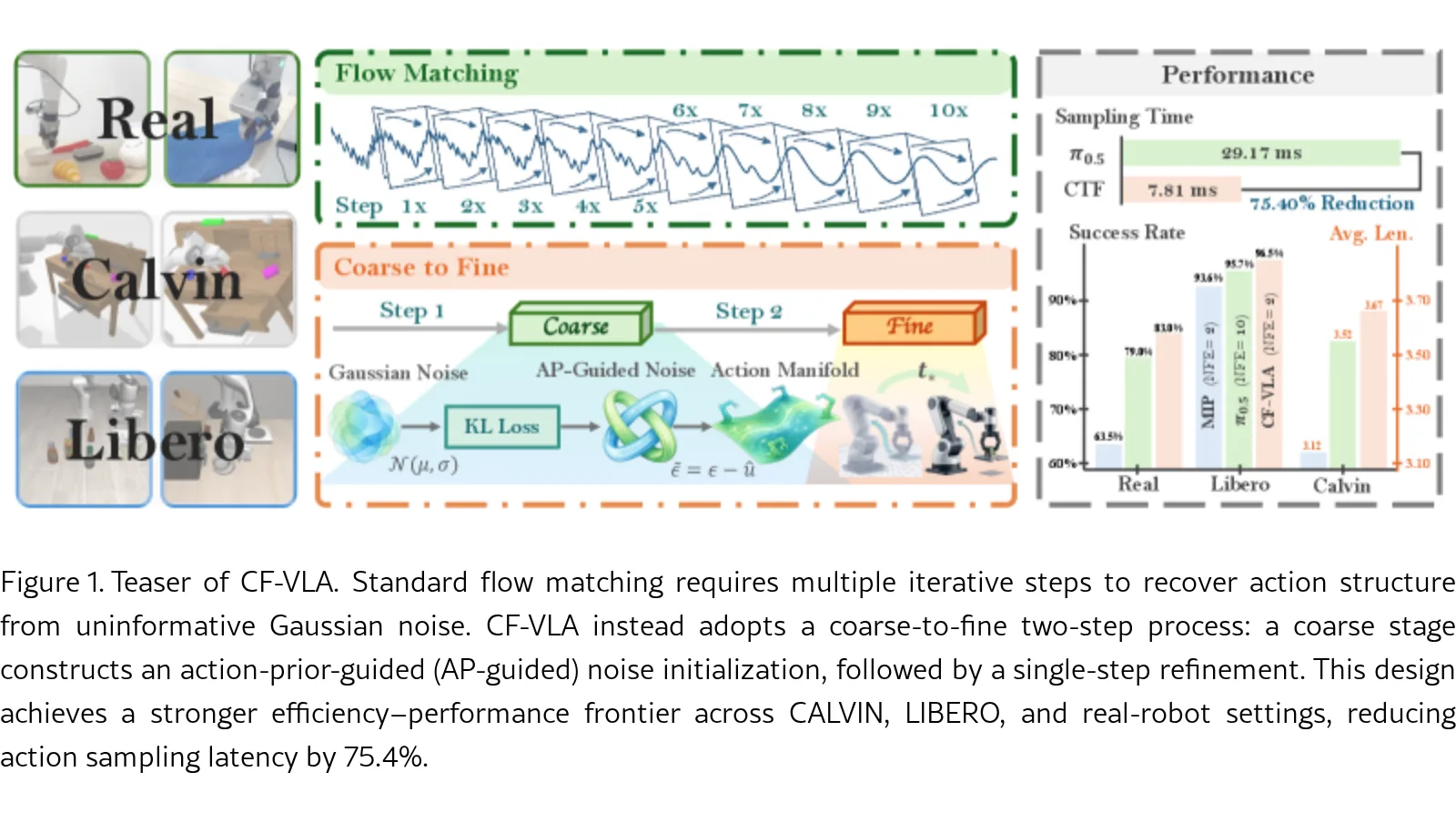
论文提出 CF-VLA,一种高效的“粗到细”两阶段动作生成框架,旨在解决流式视觉-语言-动作策略在实时约束下因多步推理导致的效率低下问题。
- 论文提出 CF-VLA,一种高效的“粗到细”两阶段动作生成框架,旨在解决流式视觉-语言-动作策略在实时约束下因多步推理导致的效率低下问题。
- 核心思想是重构动作生成的起始点而非缩短采样轨迹,将生成过程分解为构建动作先验引导的初始化和单步局部细化。
- 该方法在低函数评估次数(NFE)预算下,显著提升了效率-性能前沿,并在真实机器人上取得了更高的成功率。
Card 01
研究单位
研究单位
- 南方科技大学
- 西安交通大学
- 联合创新科技
- 中国科学技术大学
Card 02
论文概述
论文概述
- 论文提出 CF-VLA,一种高效的“粗到细”两阶段动作生成框架,旨在解决流式视觉-语言-动作策略在实时约束下因多步推理导致的效率低下问题。
- 核心思想是重构动作生成的起始点而非缩短采样轨迹,将生成过程分解为构建动作先验引导的初始化和单步局部细化。
- 该方法在低函数评估次数(NFE)预算下,显著提升了效率-性能前沿,并在真实机器人上取得了更高的成功率。
Card 03
核心贡献
核心贡献
- 提出了一个可插拔的“粗到细”两阶段VLA框架,明确分离了全局对齐与局部细化过程。
- 提出了一种方差感知的端点分布建模方法,将高斯噪声转化为更贴近动作流形的初始化。
- 设计了一种分步训练策略,通过稳定性导向的预热阶段稳定跨阶段耦合,实现高效的低步数生成。
- 在 LIBERO 和 CALVIN 基准上,以 NFE=2 的低推理预算,匹配或超越 NFE=10 的基线性能,并将动作采样延迟降低 75.4%。
- 在真实机器人实验中,取得了 83.0% 的平均成功率,超越现有最优方法。
Card 04
方法描述
方法描述
- 方法将动作生成分为粗初始化和细细化两个阶段。粗阶段学习端点速度的条件后验,通过 KL 散度损失将高斯噪声转化为结构化的 AP-guided 初始化分布。
- 细阶段从该初始化出发,进行单步固定时间的局部修正,通过 MSE 损失恢复最终动作。
- 创新点在于将生成过程从全局传输问题转变为基于学习初始化的局部修正问题,并设计了分步训练策略以确保粗阶段输出在细化前已具备良好结构。
Card 05
数据集与资源
数据集与资源
- 主要使用 LIBERO 和 CALVIN 仿真基准数据集进行训练和评估。
- 模型骨干网络参数量为 3B。
- 训练使用 8 NVIDIA A100 GPU,采用 PyTorch FSDP,全局批次大小为 16,学习率为 5e-5。
Card 06
评估与结果
评估与结果
- 评估环境包括 LIBERO 仿真基准、CALVIN 长序列基准及真实机器人操作平台。
- 主要评估指标为任务平均成功率及动作采样延迟。
- 关键实验结果:在 LIBERO 上,以 NFE=2 取得 96.5% 平均成功率,超越现有 NFE=2 方法,并匹配 NFE=10 的强基线 π0.5。
- 在真实机器人任务上,平均成功率达 83.0%,比 MIP 高出 19.5个百分点,比 π0.5 高出 4.0个百分点。
- 动作采样延迟相比基线方法降低了 75.4%,证明了极高的推理效率。