一眼看懂
封面预览
论文研究 Vision-Language-Action (VLA) 模型在机器人端部署面临的计算约束、成本和能量挑战,目标是实现低成本、实时的…
- 论文研究 Vision-Language-Action (VLA) 模型在机器人端部署面临的计算约束、成本和能量挑战,目标是实现低成本、实时的…
- 核心问题在于现有评估多依赖桌面级高端 GPU(如 NVIDIA RTX 4090),掩盖了异构边缘加速器(GPUs/XPUs/NPUs)的权衡…
- 论文通过模型-硬件协同表征,分析 VLA 推理的计算瓶颈,并提出针对性的加速方案。
Card 01
研究单位
研究单位
- 作者所属机构为 上海交通大学 计算机学院
Card 02
论文概述
论文概述
- 论文研究 Vision-Language-Action (VLA) 模型在机器人端部署面临的计算约束、成本和能量挑战,目标是实现低成本、实时的 on-robot 部署。
- 核心问题在于现有评估多依赖桌面级高端 GPU(如 NVIDIA RTX 4090),掩盖了异构边缘加速器(GPUs/XPUs/NPUs)的权衡与机遇。
- 论文通过模型-硬件协同表征,分析 VLA 推理的计算瓶颈,并提出针对性的加速方案。
Card 03
核心贡献
核心贡献
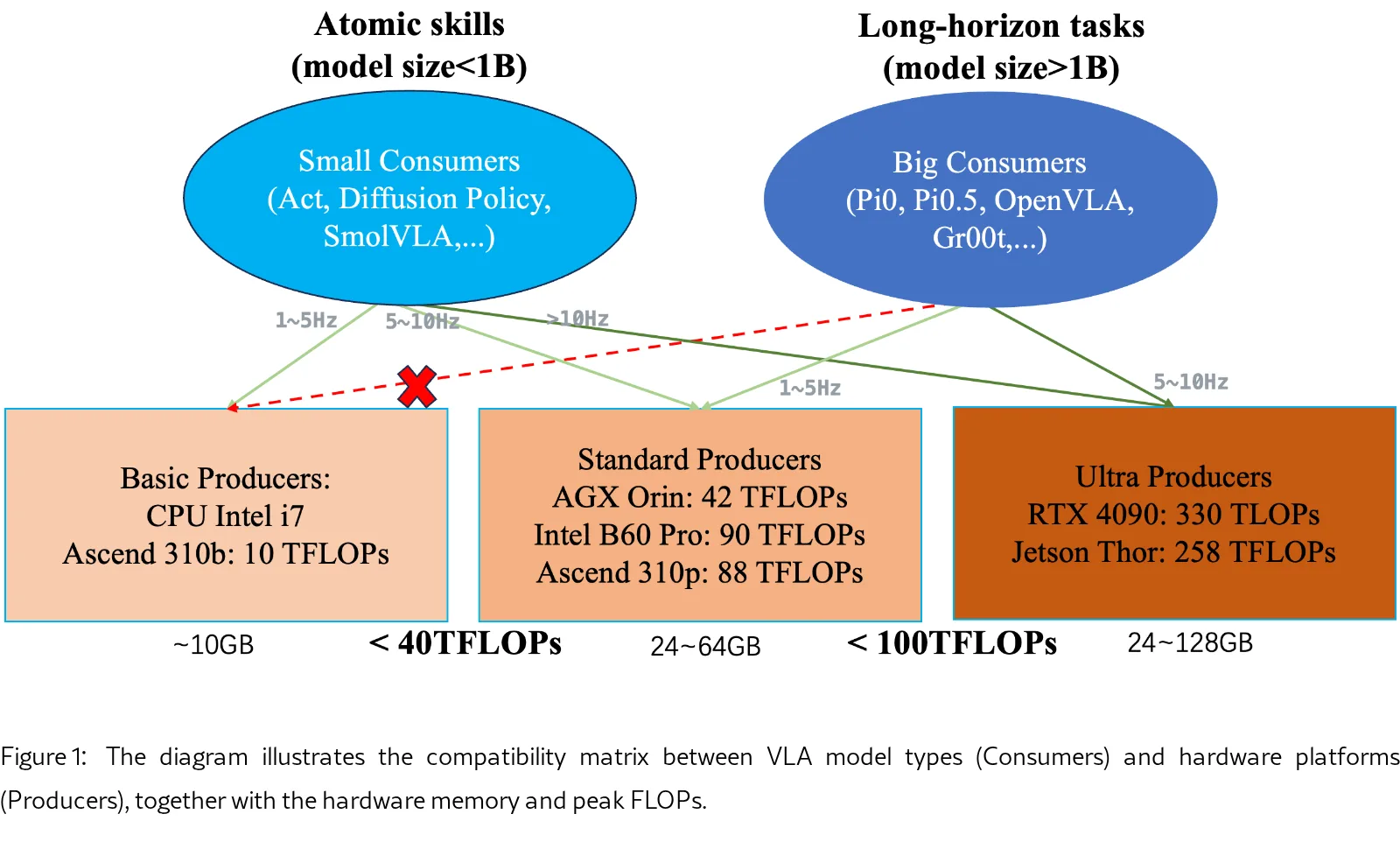
- 构建跨加速器的 VLA-XPU Leaderboard,基于 CET(Cost, Energy, Time)维度系统评估模型-硬件组合,指导“尺寸合适”的边缘设备选择。
- 通过深度 profiling 和 Roofline 分析,揭示主流 VLA 推理存在一致的两阶段模式:Compute-bound VLM Backbone 阶段后继以 Memory-bound Action Expert 阶段,导致硬件利用率低下。
- 提出两项训练无依赖的优化方法:DP-Cache 减少扩散过程冗余,V-AEFusion 实现异步流水线并行,在保持任务成功率的同时实现显著加速。
Card 04
方法描述
方法描述
- 使用 Roofline 模型 分析和端-to-end profiling(如 NVIDIA Nsight Systems)刻画 VLA 工作负载的计算特性。
- 创新性地识别出 VLA 推理中 VLM Backbone 为 Compute-bound,而 Action Expert(基于扩散或流匹配)为 Memory-bound,此相位转换导致硬件效率问题。
- 针对两阶段瓶颈,提出 DP-Cache 缓存扩散步骤中的冗余计算,并提出 V-AEFusion 通过时间相干性将 Action Expert 的早期去噪步骤与 VLM 推理重叠。
Card 05
数据集与资源
数据集与资源
- 主要使用 LIBERO 机器人学习基准数据集进行模型能力评估。
- 评估的代表性 VLA 模型包括 OpenVLA、π₀、π₀.5、Diffusion Policy、SmolVLA 等。
- 测试硬件平台覆盖 NVIDIA GPUs(RTX 4090, Jetson Orin/Thor)、Intel XPU(Arc B60 Pro)及 华为 Ascend NPUs(310B/310P)。
Card 06
评估与结果
评估与结果
- 在仿真环境(LIBERO)和真实机器人(Franka 机械臂、JAKA S5 双臂机器人)上进行部署验证。
- 主要评估指标包括:推理延迟(控制频率)、任务成功率(SR)、能量消耗及硬件成本。
- 关键结果:DP-Cache 在 RTX 4090 上实现 2.9× 加速,在 Ascend 310P 上实现 6× 加速;V-AEFusion 在 RTX 4090 上实现 1.3× 加速,所有优化仅导致任务成功率轻微下降。