一眼看懂
封面预览
论文提出 M²-VLA 模型,旨在通过 混合层机制 和 元技能模块 提升视觉语言模型在机器人操作任务中的泛化能力
- 论文提出 M²-VLA 模型,旨在通过 混合层机制 和 元技能模块 提升视觉语言模型在机器人操作任务中的泛化能力
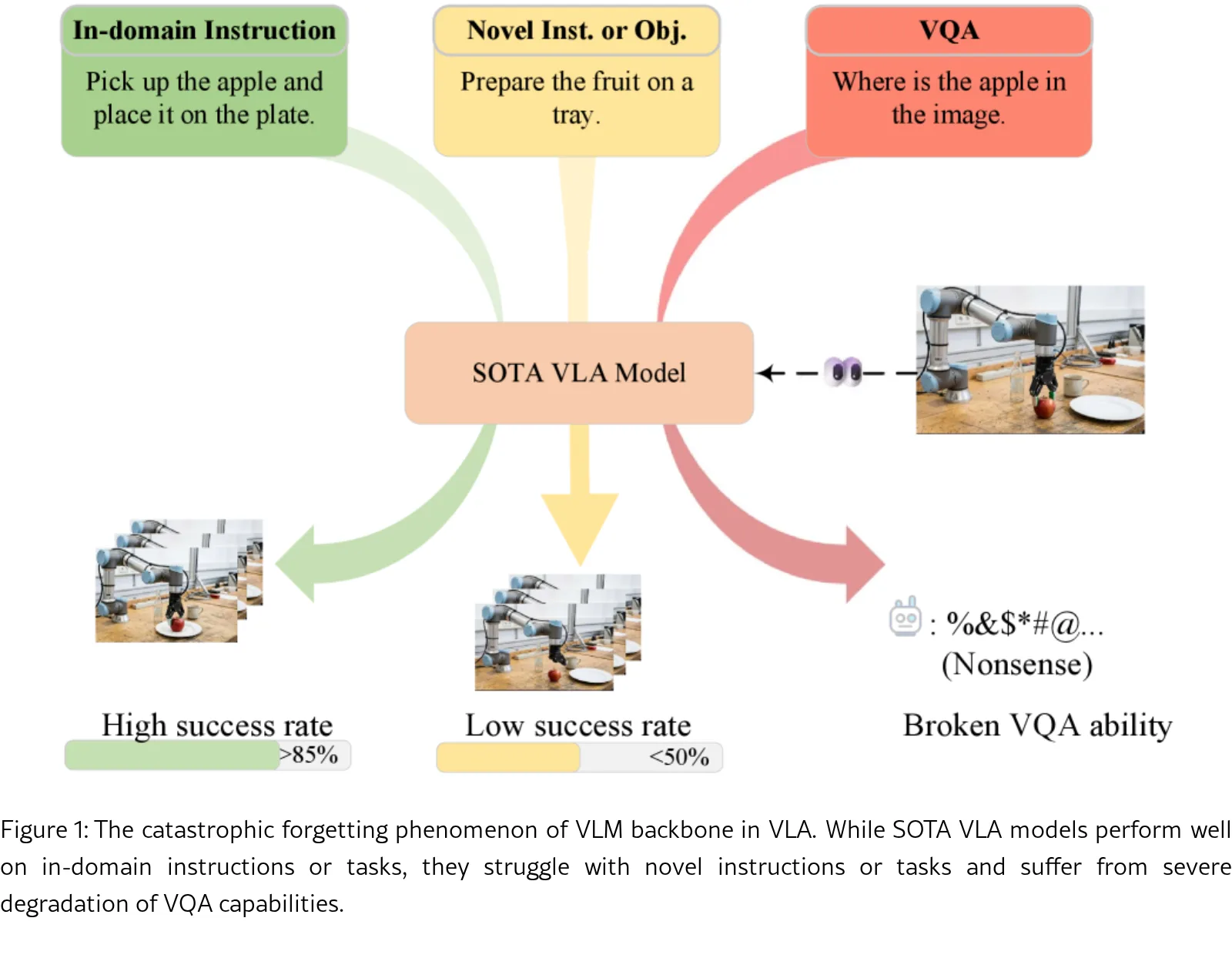
- 核心目标是解决当前 视觉语言动作模型 端到端微调导致的 灾难性遗忘 问题,损害了原始 视觉语言模型 的泛化能力
- 证明通用 视觉语言模型 可以作为强大的骨干网络直接用于机器人操作任务
Card 01
研究单位
研究单位
- 清华大学深圳国际研究生院
- 鹏城实验室
- 复旦大学智能机器人与先进制造学院
- Synapath
Card 02
论文概述
论文概述
- 论文提出 M²-VLA 模型,旨在通过 混合层机制 和 元技能模块 提升视觉语言模型在机器人操作任务中的泛化能力
- 核心目标是解决当前 视觉语言动作模型 端到端微调导致的 灾难性遗忘 问题,损害了原始 视觉语言模型 的泛化能力
- 证明通用 视觉语言模型 可以作为强大的骨干网络直接用于机器人操作任务
Card 03
核心贡献
核心贡献
- 提出 混合层机制,通过提取操作关键的细粒度空间信息来连接高层语义理解和底层精确控制
- 设计 元技能模块,通过知识重用和强归纳偏置增强轻量级动作头的轨迹学习能力
- 通过新颖架构设计使冻结的通用 视觉语言模型 能够作为高性能机器人操作的骨干网络,避免灾难性遗忘
Card 04
方法描述
方法描述
- 采用预训练 视觉语言模型 作为冻结的感知骨干,保持参数不变以维持泛化能力
- 引入 混合层机制,包含三个解耦注意力分支,动态过滤和聚合任务相关特征
- 设计轻量级动作头作为去噪 transformer,结合 元技能模块 的技能检索和动作细化机制
- 使用 DINOv2 和 SigLIP 处理视觉输入,结合可学习查询提取跨模态信息
Card 05
数据集与资源
数据集与资源
- 使用 Libero 数据集进行仿真实验,包含 Spatial、Object、Goal、Long 四个测试套件
- 模型参数量约 0.3B(可训练部分),远小于基准方法的 7B
- 训练资源:4 NVIDIA A800 GPU,单卡 RTX 3090 仅需8小时完成训练
- 真实世界实验使用 AgileX PiPer 机械臂和2个RGB相机采集数据
Card 06
评估与结果
评估与结果
- 在 Libero 仿真基准上取得最佳平均成功率 95.3%,显著优于其他方法
- 在指令跟随泛化任务中成功率 66.2%,性能下降仅 29.4%,优于基线方法
- 在新物体泛化任务中成功率 34.4%,性能下降仅 30.4%
- 真实世界任务中基础操作成功率 85-90%,泛化任务成功率 75-80%
- 消融研究验证 混合层机制 和 元技能模块 均对性能提升有显著贡献