一眼看懂
封面预览
研究解决云端部署的 Vision-Language-Action (VLA) 模型 在移动机器人导航中面临的网络延迟和时序错位问题
- 研究解决云端部署的 Vision-Language-Action (VLA) 模型 在移动机器人导航中面临的网络延迟和时序错位问题
- 云端推理延迟导致机器人执行的是过去时刻的指令意图,在连续位移场景下会造成严重的时空错位,可能引发碰撞
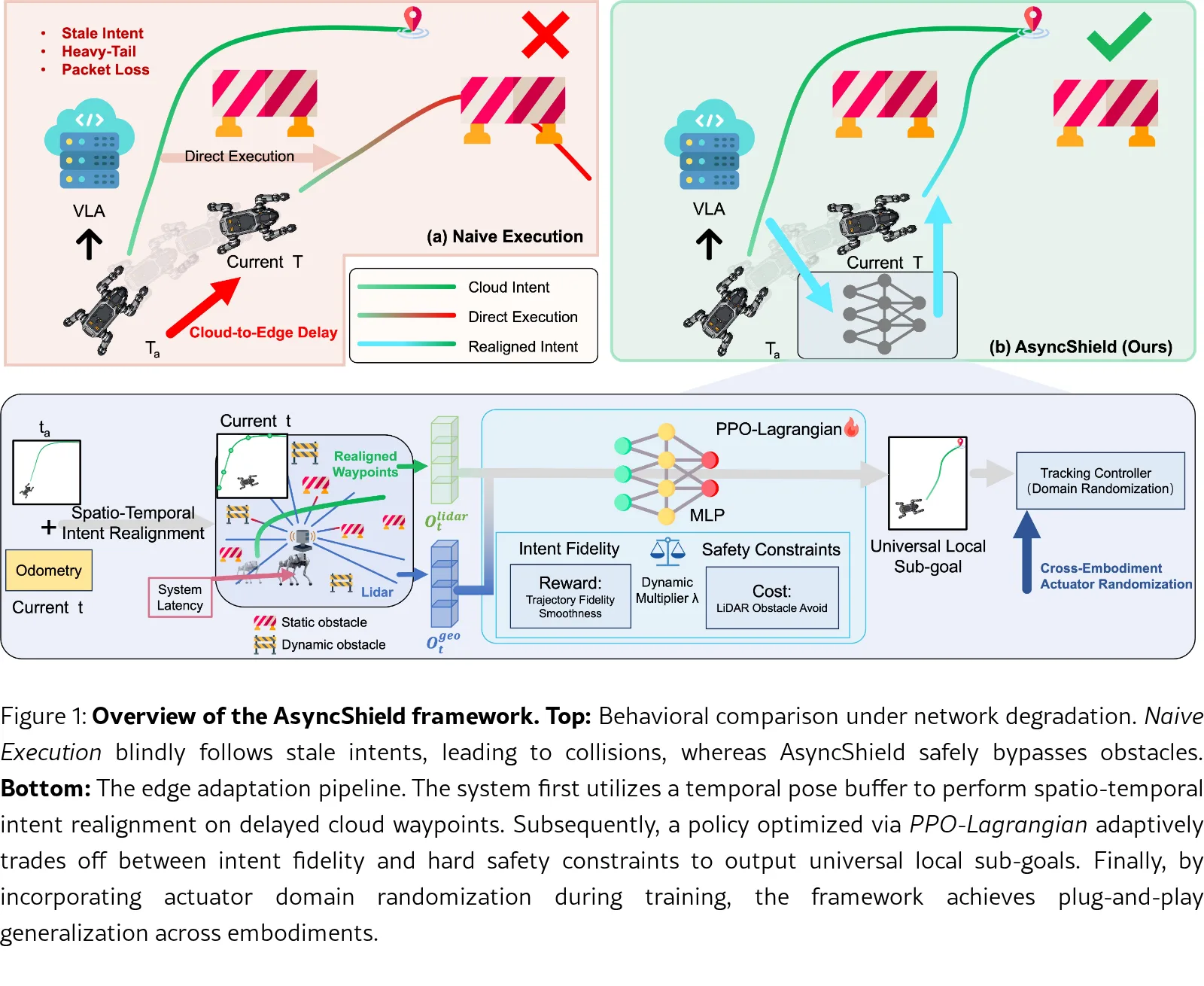
- 提出 AsyncShield 框架,将传统黑盒时序预测转变为确定性物理白盒空间映射,并通过约束马尔可夫决策过程(CMDP)实现意图追踪与安全避…
Card 01
研究单位
研究单位
- Amap, Alibaba Group, Beijing, China(高德地图,阿里巴巴集团)
- Beijing Jiaotong University, Beijing, China(北京交通大学)
Card 02
论文概述
论文概述
- 研究解决云端部署的 Vision-Language-Action (VLA) 模型 在移动机器人导航中面临的网络延迟和时序错位问题
- 云端推理延迟导致机器人执行的是过去时刻的指令意图,在连续位移场景下会造成严重的时空错位,可能引发碰撞
- 提出 AsyncShield 框架,将传统黑盒时序预测转变为确定性物理白盒空间映射,并通过约束马尔可夫决策过程(CMDP)实现意图追踪与安全避障的自适应平衡
Card 03
核心贡献
核心贡献
- 云端VLA导航边缘适配器:将黑盒时间预测替换为确定性白盒空间映射,通过 SE(2) 运动学变换消除云端边缘延迟错位
- 安全执行闭环:将边缘适配问题表述为 CMDP,使用 PPO-Lagrangian 算法实现 VLA 几何意图恢复与高频 LiDAR 障碍物规避之间的自适应动态权衡
- 强即插即用能力:标准化通用子目标接口,结合域随机化和感知级碰撞半径膨胀,无需微调云端基础模型即可零样本适配多种 VLA 模型并泛化到多种异构机器人底盘
Card 04
方法描述
方法描述
- 时空意图重对齐:维护时序姿态缓冲区,利用 SE(2) 运动学变换将延迟时间转换为空间姿态偏移
- 状态空间:包含 10 维几何特征(5 个前视点,0.2m 间隔)和 144 维 2D LiDAR 接近度数据
- 动作空间:定义为通用局部子目标 (Δx, Δy),与具体机器人动力学解耦
- 奖励设计:轨迹保真度和平滑度,独立于障碍物规避
- 安全约束:基于最小 LiDAR 距离的物理安全硬约束
- 训练策略:运动学域随机化(系统延迟、加速度约束、随机噪声与偏置)+ 碰撞半径膨胀机制
Card 05
数据集与资源
数据集与资源
- 仿真环境:OmniSafe 框架,10m × 10m 工作空间,6 静6 动障碍物
- 网络条件:理想(~200ms 延迟)与非理想(混合降质:0.5-1.5s 延迟峰值,15% 丢包率,5% 临时中断)
- 真实硬件:Unitree Go2 四足机器人,2D LiDAR,Wi-Fi 通信(~200ms 往返延迟)
- 测试 VLA 模型:SocialNav、TrackVLA、Nav-R²
Card 06
评估与结果
评估与结果
- 评估指标:成功率 (SR)、横迹误差 (CTE)、风险暴露率 (RER)、到达时间 (TTG)
- 关键结果:
- AsyncShield 在理想/非理想网络条件下分别达到 80.0%/76.7% SR,RER 仅 1.2%/1.3%
- 显著优于 baseline:A2C2 (56.7%→43.3%)、RTC (40.0%→30.0%)、Naive (20.0%→16.7%)
- 消融实验:时空对齐、RL 适配器、安全约束均为核心组件,移除任一模块性能大幅下降
- 跨本体验证:零样本泛化到 Doggo 四足机器人和 Racecar 车辆,SR 维持在 76-79%
- 真实部署:搭配三种云端 VLA 模型,SR 提升至 80-90%(直接 VLA 仅 25-40%)