一眼看懂
封面预览
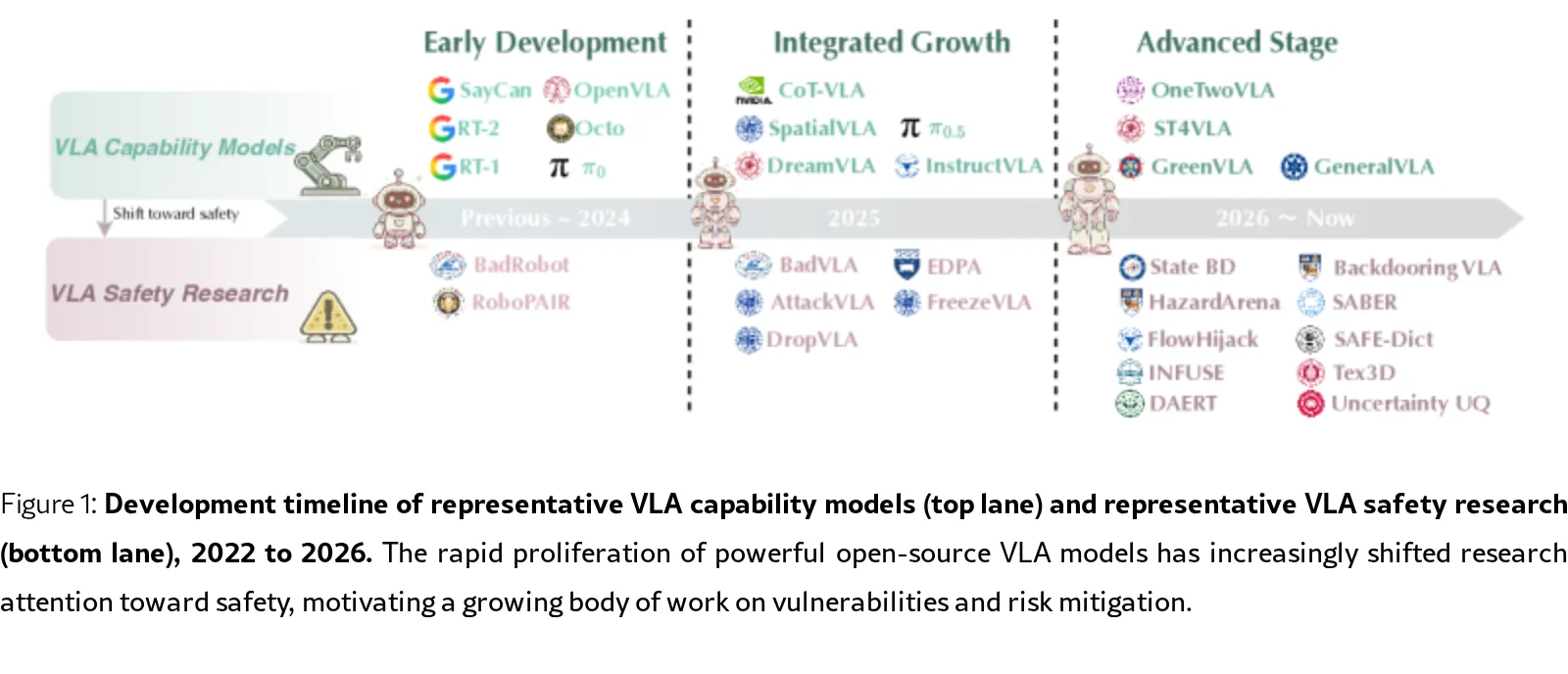
本文是首篇系统综述 Vision-Language-Action (VLA) 模型安全性的论文,旨在为具身智能体的安全研究提供统一视角
- 本文是首篇系统综述 Vision-Language-Action (VLA) 模型安全性的论文,旨在为具身智能体的安全研究提供统一视角
- 论文指出了VLA安全不同于文本LLM安全与传统机器人安全的独特挑战,包括不可逆的物理后果、多模态攻击面、实时约束下的安全能力权衡等
- 系统梳理了VLA安全领域的威胁、防御、评估与部署问题,以解决现有研究碎片化、缺乏统一框架的现状
Card 01
研究单位
研究单位
- National University of Singapore (多位主要作者所属,包括项目主导和通讯作者)
- Monash University (作者 Jingwen Ye 所属)
- Peking University (作者 Bojun Zou 和 Weihao Yu 所属)
Card 02
论文概述
论文概述
- 本文是首篇系统综述 Vision-Language-Action (VLA) 模型安全性的论文,旨在为具身智能体的安全研究提供统一视角
- 论文指出了VLA安全不同于文本LLM安全与传统机器人安全的独特挑战,包括不可逆的物理后果、多模态攻击面、实时约束下的安全能力权衡等
- 系统梳理了VLA安全领域的威胁、防御、评估与部署问题,以解决现有研究碎片化、缺乏统一框架的现状
Card 03
核心贡献
核心贡献
- 提出基于“攻击时机”与“防御时机”双轴的 统一威胁与防御分类体系,将每类威胁与可被缓解的阶段进行关联
- 全面综述了训练时攻击(如数据投毒、后门)、推理时攻击(如对抗扰动、越狱)、及对应的训练与运行时防御机制
- 对现有 VLA安全基准与评估指标 进行了结构化分析,指出了关键缺口并提出了未来基准设计准则
- 从六个现实部署领域出发,分析了跨域安全挑战,并指出了 认证鲁棒性、物理可实现防御 等关键未来研究方向
Card 04
方法描述
方法描述
- 采用双轴分类法:按 攻击时机(训练时 vs. 推理时)与 防御时机(训练时 vs. 推理时)系统组织威胁与防御文献
- 分析训练时攻击如 BadVLA、DropVLA 的目标劫持机制,以及 SilentDrift 利用动作分块视觉盲区的隐蔽漂移攻击
- 讨论防御机制,包括训练时的安全对齐、数据完整性检查,以及推理时的决策层护栏、运行时监控和物理失效保护
Card 05
数据集与资源
数据集与资源
- 主要讨论并分析基于 Open X-Embodiment 数据集和 LIBERO 基准训练的代表性VLA模型
- 涵盖代表性模型如 RT-1、RT-2、Octo、OpenVLA、π₀、π₀.5、SpatialVLA,参数规模从35M至55B不等
- 论文本身为综述,未涉及新模型的训练资源消耗细节
Card 06
评估与结果
评估与结果
- 评估对象为现有VLA安全研究方法与基准,而非提出新模型或新实验
- 指出当前评估指标包括 安全违规率 (SVR)、碰撞率 (CR)、攻击成功率 (ASR) 等任务级、行为级及鲁棒性指标
- 分析发现现有安全基准开发滞后于模型能力进展,且评估多集中于仿真环境,缺乏对 仿真到现实 (Sim-to-Real) 差距 的系统性考量