一眼看懂
封面预览
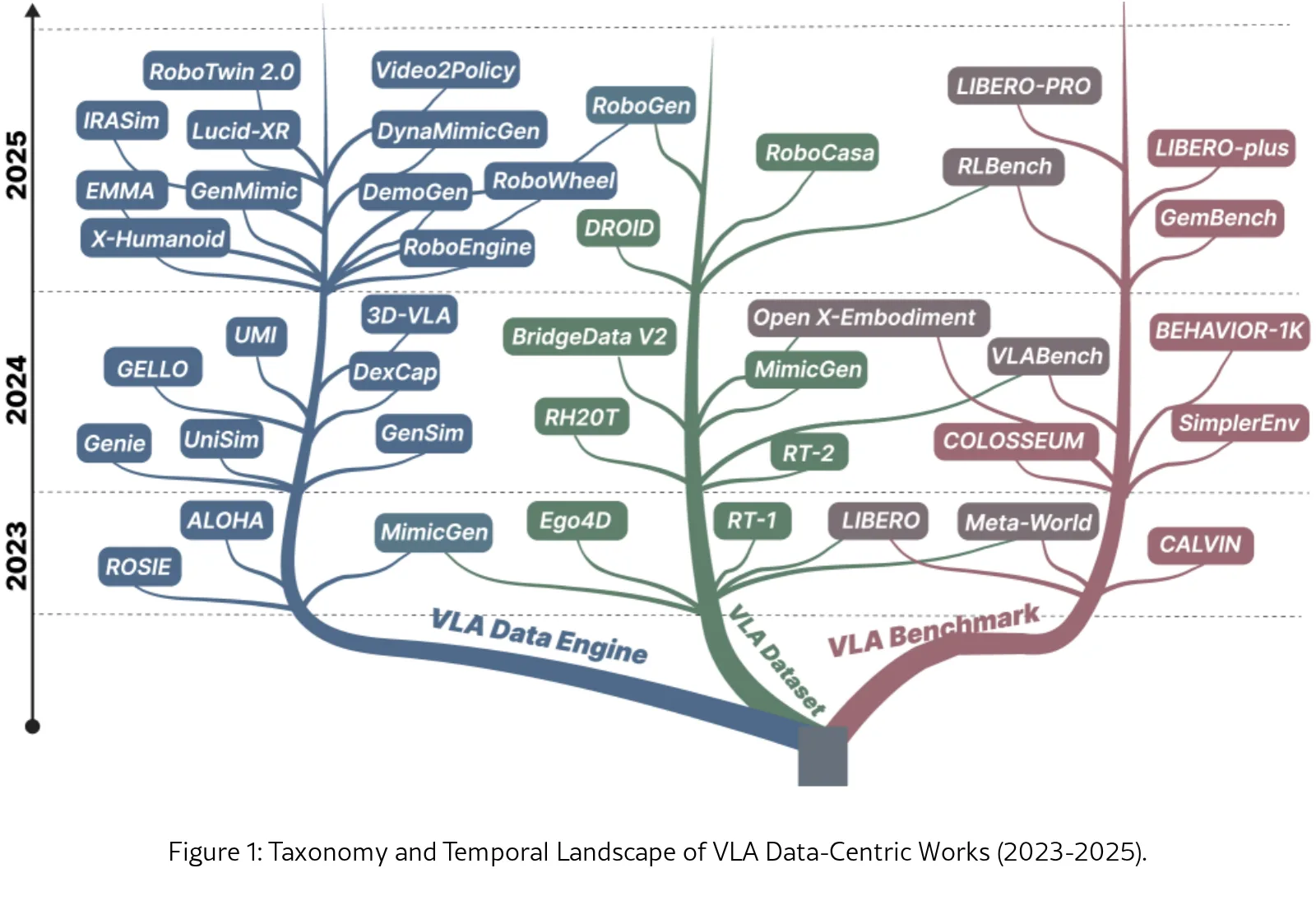
该论文是第一篇从数据中心视角系统分析视觉-语言-动作(VLA)领域的研究综述,将现有工作组织为三个核心类别:数据集、基准测试和数据引擎
- 该论文是第一篇从数据中心视角系统分析视觉-语言-动作(VLA)领域的研究综述,将现有工作组织为三个核心类别:数据集、基准测试和数据引擎
- 论文揭示了VLA研究中存在的保真度-成本权衡问题:真实世界数据质量高但收集成本高,合成数据可扩展但保真度不足
- 论文识别出三个结构性挑战:跨实体表征对齐、长程推理任务评估和可扩展数据生成,指出未来VLA的突破将更依赖于数据基础设施的协同设计而非模型架构
Card 01
研究单位
研究单位
- University of Maryland, College Park(马里兰大学帕克分校)
- University of Utah(犹他大学)
- Northeastern University(东北大学)
- University of Wisconsin–Madison(威斯康星大学麦迪逊分校)
Card 02
论文概述
论文概述
- 该论文是第一篇从数据中心视角系统分析视觉-语言-动作(VLA)领域的研究综述,将现有工作组织为三个核心类别:数据集、基准测试和数据引擎
- 论文揭示了VLA研究中存在的保真度-成本权衡问题:真实世界数据质量高但收集成本高,合成数据可扩展但保真度不足
- 论文识别出三个结构性挑战:跨实体表征对齐、长程推理任务评估和可扩展数据生成,指出未来VLA的突破将更依赖于数据基础设施的协同设计而非模型架构
Card 03
核心贡献
核心贡献
- 提出统一的VLA数据中心化分类体系,阐明数据集、基准测试和数据引擎在训练、评估和可扩展数据生产中的不同角色
- 引入结构化分析框架,包括二维基准表征(任务复杂度 × 环境结构)和数据集/数据引擎设计选择系统比较
- 识别出跨三个组件的三大挑战:跨实体表征对齐、长程组合任务可靠评估、可扩展数据生成保持物理真实性
- 提供持续更新的开源仓库:https://github.com/ziyaow1010/vla-datasets-benchmarks
Card 04
方法描述
方法描述
- 数据集分类:按数据源分为真实世界数据集(如Open X-Embodiment、DROID、RT-1/BridgeData V2)和合成数据集(如SynGrasp-1B、RoboCasa、RoboGen)
- 基准测试分类:按任务复杂度(短程原子操作 vs 长程组合任务)和环境结构(桌面基准 vs 多场景基准)进行分析
- 数据引擎分类:视频到数据引擎(如H2R、RoboWheel)、硬件辅助引擎(如ALOHA、UMI)、生成式数据引擎(如MimicGen、RoboGen)
- 动作空间设计分析:端 effector 空间 vs 关节空间、绝对目标 vs 相对(delta)命令
Card 05
数据集与资源
数据集与资源
主要数据集:
- Open X-Embodiment:22个机器人平台的跨实体聚合数据
- RT-1/RT-2:Everyday Robots平台的大规模数据
- DROID:Franka Panda机器人的真实世界大规模采集
- BridgeData V2:低成本标准化设置的WidowX 250数据
- SynGrasp-1B:十亿级合成抓取数据
主要基准测试:
- 桌面基准:Meta-World、LIBERO、CALVIN、RLBench
- 多场景基准:BEHAVIOR-1K(1000个日常活动)、VLABench
评估指标:主要使用任务成功率(Success Rate, SR)
Card 06
评估与结果
评估与结果
- 论文分析了现有基准在长程推理和组合泛化方面的不足:CALVIN中5个连续指令成功率降至0.08%
- 揭示了当前基准缺乏对VLA推理能力的结构化评估框架,特别是在时间组合、多因素变异和跨实体转移需联合评估的场景
- 指出数据引擎的核心限制是接地可靠性而非生成能力:物理 grounding、实体对齐和可靠性验证落后于可扩展性
- 总结了四大开放挑战:表征对齐、多模态监督、推理评估、可扩展数据生成