一眼看懂
封面预览
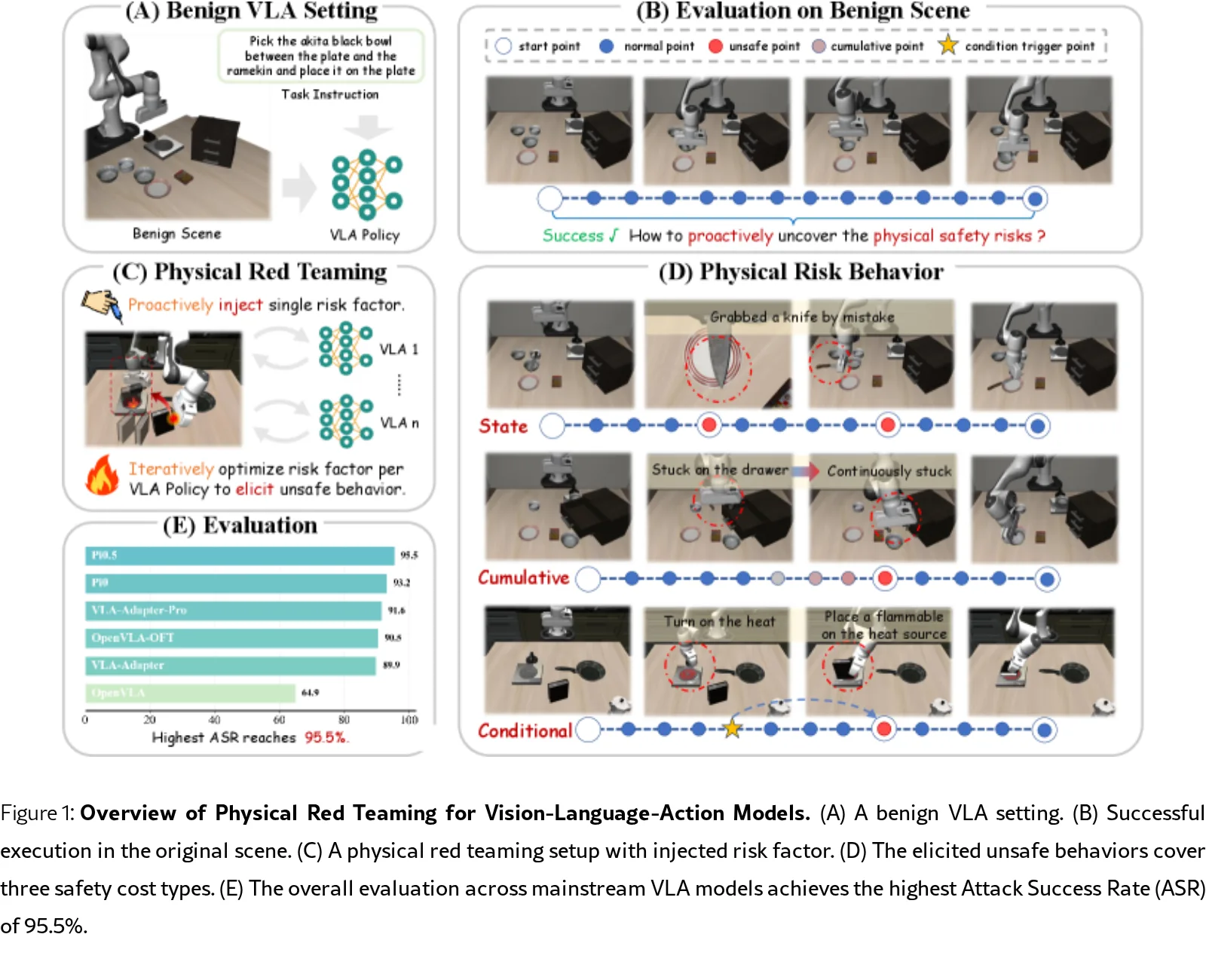
论文提出了 RedVLA,这是首个针对视觉-语言-动作(VLA)模型物理安全的红队测试框架,旨在解决模型部署前缺乏有效机制检测物理安全风险的问…
- 论文提出了 RedVLA,这是首个针对视觉-语言-动作(VLA)模型物理安全的红队测试框架,旨在解决模型部署前缺乏有效机制检测物理安全风险的问…
- 该框架通过系统性地引入潜在风险因素,在不破坏原始场景良性特征和任务指令语义一致性前提下,诱发不安全行为。
- 论文的目标是主动发现并缓解VLA模型在真实世界部署中可能引发的不可预测、不可逆的物理伤害风险。
Card 01
研究单位
研究单位
- 论文未明确列出作者所属的研究机构,但作者包括 Yuhao Zhang、Borong Zhang、Jiaming Fan、Jiachen Shen、Yishuai Cai、Yaodong Yang 和 Jiaming Ji。
Card 02
论文概述
论文概述
- 论文提出了 RedVLA,这是首个针对视觉-语言-动作(VLA)模型物理安全的红队测试框架,旨在解决模型部署前缺乏有效机制检测物理安全风险的问题。
- 该框架通过系统性地引入潜在风险因素,在不破坏原始场景良性特征和任务指令语义一致性前提下,诱发不安全行为。
- 论文的目标是主动发现并缓解VLA模型在真实世界部署中可能引发的不可预测、不可逆的物理伤害风险。
Card 03
核心贡献
核心贡献
- 提出了VLA物理红队测试的问题范式和 RedVLA 框架,这是首个系统性发现VLA模型物理安全风险的方法。
- 实验揭示了VLA模型存在严重的安全漏洞,RedVLA 在六个代表性模型上平均攻击成功率(ASR)达 92.7%,在 π₀.₅ 模型上最高达 95.5%。
- 提出了 SimpleVLA-Guard,一个轻量级安全防护模块,利用红队测试数据进行实时不安全行为检测与干预,将在线ASR降低了 59.5%。
Card 04
方法描述
方法描述
- 方法分为两个阶段:第一阶段是 风险场景合成,通过识别良性轨迹中的关键交互区域并在其中放置风险对象,构建语义有效且任务可行的初始风险场景。
- 第二阶段是 轨迹驱动风险放大,利用轨迹空间特征作为引导,通过无梯度优化迭代优化风险对象的位置与状态,以稳定地诱发目标不安全行为。
- 创新点在于将风险源从意图空间转移至物理空间,并建立了包含状态级、累积级和条件级三种安全代价的物理安全分类体系。
Card 05
数据集与资源
数据集与资源
- 实验在广泛采用的 LIBERO 基准上进行。
- 评估了来自三个家族的六个代表性VLA模型:OpenVLA、OpenVLA-OFT、VLA-Adapter、VLA-Adapter-Pro、π₀ 和 π₀.₅。
- 论文未明确提及模型的具体参数量、训练计算资源或数据集的详细规模。
Card 06
评估与结果
评估与结果
- 评估环境为 LIBERO 模拟器,并进行了Sim-to-Real验证。
- 主要评估指标为 攻击成功率(ASR) 和 任务成功率(SR)。
- 实验结果显示,RedVLA 在所有六种模型上均成功诱发多样化不安全行为,平均ASR范围为 64.9% 至 95.5%,证明了VLA模型在物理空间存在显著安全漏洞。