一眼看懂
封面预览
论文提出 CodeGraphVLP,旨在解决现有视觉-语言-动作(VLA)模型在非马尔可夫长程任务中的局限性,即模型通常仅依赖最新观察而忽略历…
- 论文提出 CodeGraphVLP,旨在解决现有视觉-语言-动作(VLA)模型在非马尔可夫长程任务中的局限性,即模型通常仅依赖最新观察而忽略历…
- 核心方案是结合持久的语义图状态、可执行的代码规划器以及进度引导的视觉语言提示,以实现鲁棒的长程机器人操作。
- 该方法通过显式维护任务相关的实体和关系,并利用代码规划器高效推断进度,避免了高昂的 VLM 在线推理成本,同时增强了在杂乱场景下的视觉定位能力。
Card 01
研究单位
研究单位
- University of Arkansas(美国阿肯色大学,主要单位)
- Max Planck Research School for Intelligent Systems and University of Stuttgart(德国斯图加特大学)
- Google Research(谷歌研究院)
- TU Wien(奥地利维也纳工业大学)
- University of Liverpool(英国利物浦大学)
Card 02
论文概述
论文概述
- 论文提出 CodeGraphVLP,旨在解决现有视觉-语言-动作(VLA)模型在非马尔可夫长程任务中的局限性,即模型通常仅依赖最新观察而忽略历史关键信息。
- 核心方案是结合持久的语义图状态、可执行的代码规划器以及进度引导的视觉语言提示,以实现鲁棒的长程机器人操作。
- 该方法通过显式维护任务相关的实体和关系,并利用代码规划器高效推断进度,避免了高昂的 VLM 在线推理成本,同时增强了在杂乱场景下的视觉定位能力。
Card 03
核心贡献
核心贡献
- 提出了 CodeGraphVLP 框架,将代码规划器、持久语义图状态和去杂乱的视觉语言提示相结合,实现了对非马尔可夫长程任务的鲁棒控制。
- 展示了在语义图上运行的可执行代码如何高效跟踪任务进度、选择子任务,并生成子任务相关对象以辅助下游执行。
- 设计了三个具有非马尔可夫依赖特性的真实桌面操作任务,证明了该方法在提高任务成功率的同时显著降低了规划延迟。
Card 04
方法描述
方法描述
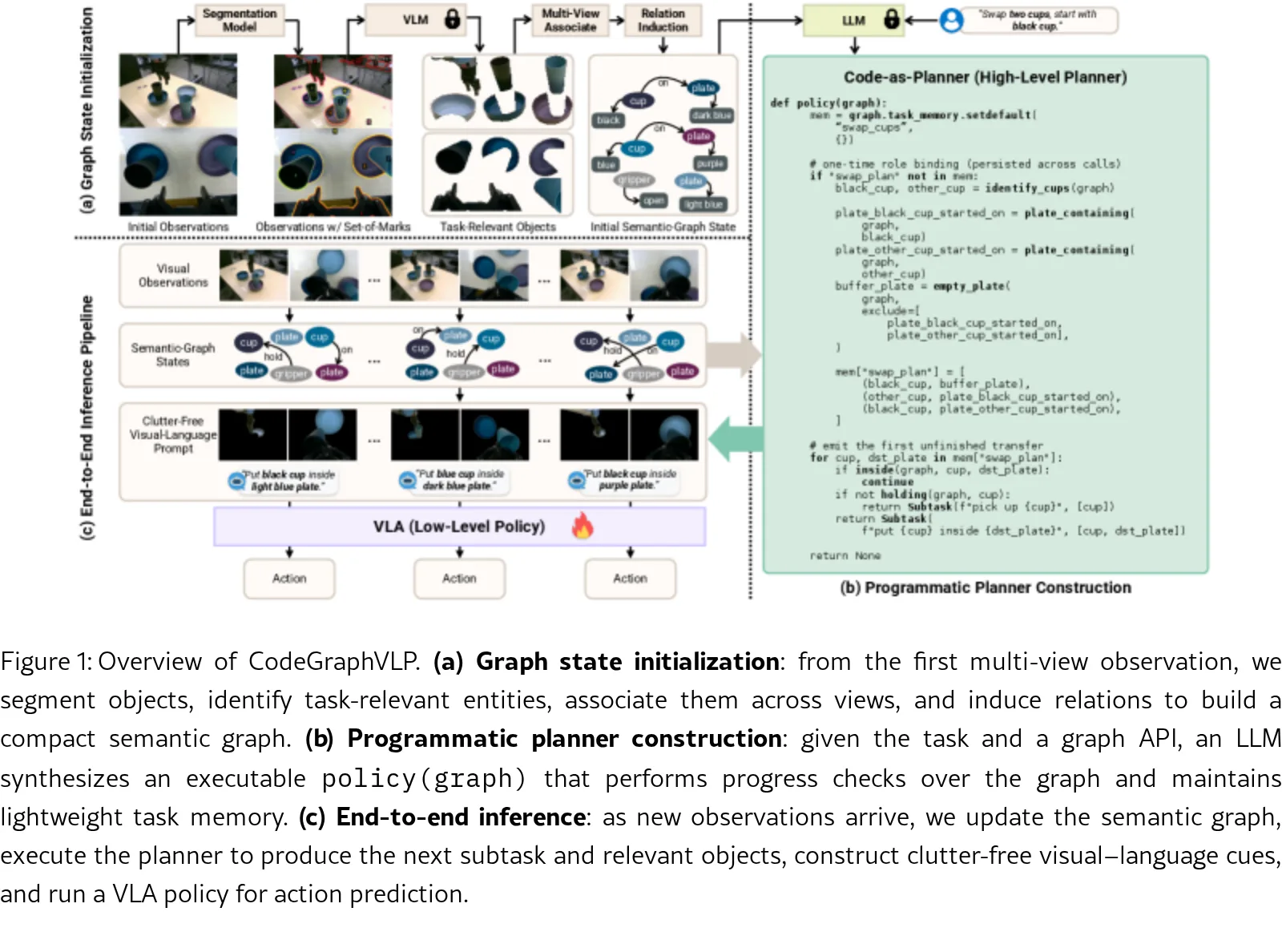
- 构建语义图状态:通过对象分割、任务相关性识别、多视图关联和关系推导,初始化并在线更新包含实体节点和关系边的结构化状态。
- 代码规划器:利用 LLM(如 GPT-5)一次性合成可执行的 Python 程序,该程序查询语义图以检查进度并输出下一个子任务指令及相关对象,无需在执行过程中反复调用 VLM。
- 去杂乱视觉语言提示:根据规划器输出的相关对象集合,对原始 RGB 图像进行掩码处理,屏蔽无关物体(杂乱),生成仅包含关键视觉证据的输入,配合子任务语言指令引导 VLA 执行器。
Card 05
数据集与资源
数据集与资源
- 使用了自采集的遥操作演示数据集:Pick-and-Place Twice(100 条轨迹)、Place-and-Stack(100 条轨迹)、Swap Cups(200 条轨迹)。
- 基础模型为 $\pi_0$,并使用 LoRA 进行微调,训练在 4 张 NVIDIA A6000 GPU 上进行。
- 代码规划器由 GPT-5 合成。
Card 06
评估与结果
评估与结果
- 在真实世界的 UR10e 机械臂平台上进行评估,包含三个非马尔可夫桌面任务。
- 主要评估指标为任务成功率及规划延迟时间。
- 实验结果显示,CodeGraphVLP 的平均成功率达到 81.7%,显著优于最强基线 Gr00T N1.5 + Multi-frame(56.7%)及其他 VLA 模型。
- 规划延迟方面,CodeGraphVLP 仅需 0.328 sec/step,远低于基于 VLM 在线规划的 2.967 sec/step,证明了代码规划的高效性。