一眼看懂
封面预览
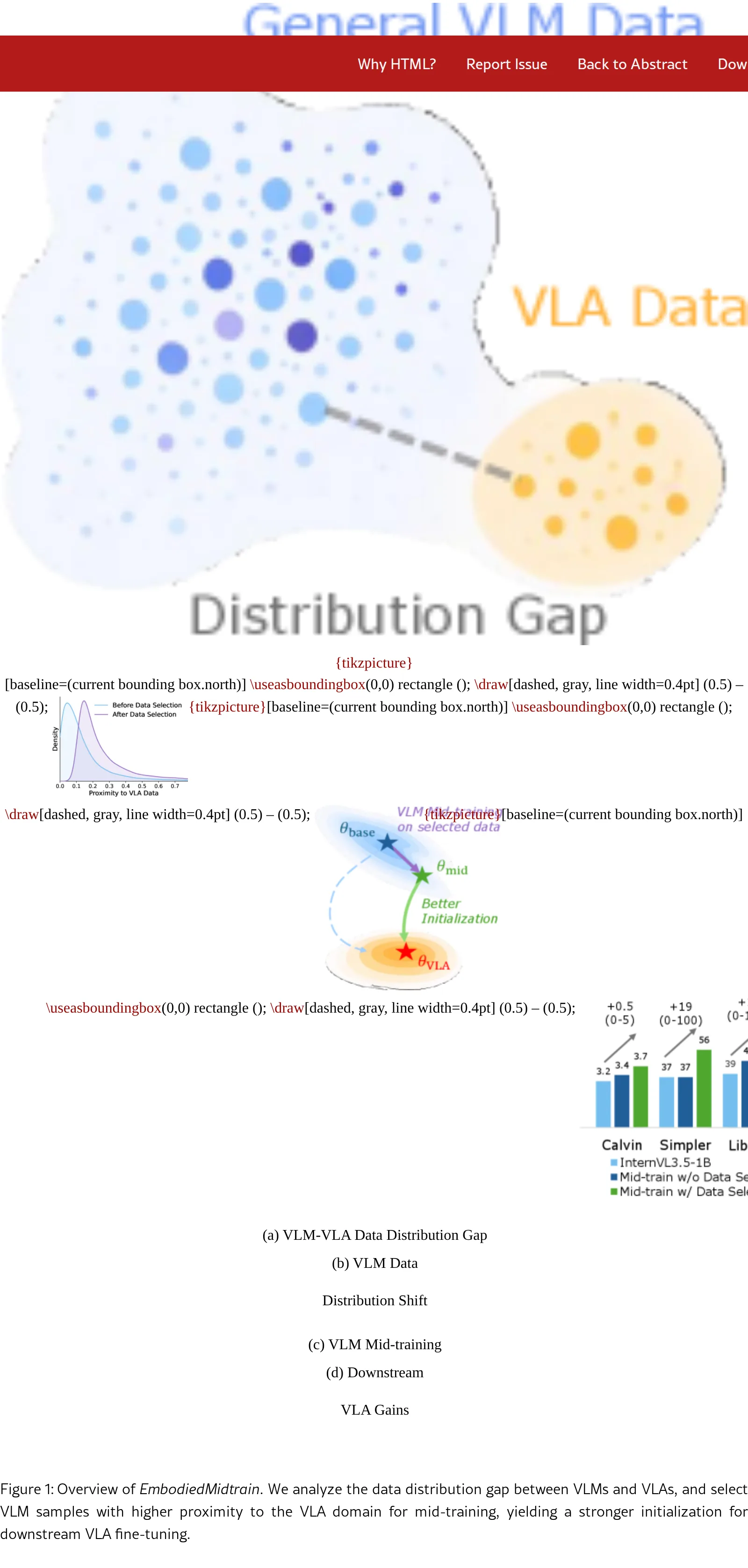
核心问题:视觉语言动作模型(VLAs)继承自视觉语言模型(VLMs)的视觉和语言能力,但大多数VLAs使用通用的现成VLMs,这些模型未针对具…
- 核心问题:视觉语言动作模型(VLAs)继承自视觉语言模型(VLMs)的视觉和语言能力,但大多数VLAs使用通用的现成VLMs,这些模型未针对具…
- 研究目标:通过中间训练(mid-training)缩小VLM和VLA之间的数据分布差距,使VLAs能真正受益于VLM backbone的能力
- 核心方法:构建一个轻量级的近邻估计器(proximity estimator),在冻结的VLM特征上训练二分类器,识别与VLA领域最接近的VL…
Card 01
研究单位
研究单位
- Language Technologies Institute, Carnegie Mellon University(卡内基梅隆大学语言技术研究所)
- Bosch Research North America & Bosch Center for Artificial Intelligence (BCAI)(博世北美研究院及博世人工智能中心)
Card 02
论文概述
论文概述
- 核心问题:视觉语言动作模型(VLAs)继承自视觉语言模型(VLMs)的视觉和语言能力,但大多数VLAs使用通用的现成VLMs,这些模型未针对具身领域进行适配,导致下游任务性能受限
- 研究目标:通过中间训练(mid-training)缩小VLM和VLA之间的数据分布差距,使VLAs能真正受益于VLM backbone的能力
- 核心方法:构建一个轻量级的近邻估计器(proximity estimator),在冻结的VLM特征上训练二分类器,识别与VLA领域最接近的VLM样本,并用这些精选样本对VLM进行中间训练
Card 03
核心贡献
核心贡献
- 近邻选择的中间训练管道:提出EmbodiedMidtrain,通过学习近邻估计器对VLM样本进行评分,选取与VLA分布最接近的样本构建中间训练数据混合
- 跨基准和backbone的一致性能提升:在Calvin ABC-D、SimplerEnv Bridge和Libero-10三个机器人操作基准上,1.1B模型的性能显著提升,效果与更大规模的专家VLAs和现成VLMs相当
- 跨backbone的可迁移性:用InternVL3.5-1B特征空间选择的近邻数据应用于Qwen3VL-2B也能获得一致提升
- 更好的VLA初始化:中间训练的优势从微调最早阶段就显现,并随训练推移持续扩大
Card 04
方法描述
方法描述
- 数据分布分析:使用最大均值差异(MMD)量化VLM和VLA数据的分布差距,发现VLA数据形成紧凑的簇,与VLM分布明显分离,但部分VLM样本与VLA领域存在内在对齐
- 近邻估计器:在冻结VLM特征上训练轻量级二分类器(线性层),用VLA样本作为正例、VLM样本作为负例,分类器的输出作为每个VLM样本与VLA领域接近程度的连续度量
- 数据选择:对所有候选VLM样本按近邻分数排序,保留分数最高的子集进行中间训练,使训练分布向VLA域倾斜
- VLA微调:采用VLM4VLA的适配设计,将VLM backbone与双分支MLP动作解码器级联,预测连续机械臂动作和二进制夹爪动作
Card 05
数据集与资源
数据集与资源
- VLM数据源:
- 通用VLM数据:LAION-400M、CC-12M(BLIP重新标注)、LLaVA-Instruct-665k、VCR
- 具身导向VLM数据:RefSpatial、EmbSpatial-Bench、Robo2VLM、RoboPoint
- 评估基准:Calvin ABC-D、SimplerEnv Bridge、Libero-10
- 模型规模:InternVL3.5-1B(1.1B参数)、Qwen3VL-2B(2.1B参数)
- 训练资源:使用LLaMA-Factory框架,全参数微调,batch size 256,5000步
Card 06
评估与结果
评估与结果
- Calvin ABC-D:中间训练的InternVL3.5-1B达到3.714平均任务序列长度,超越OpenVLA(2.548)和π₀(3.509)
- SimplerEnv Bridge:达到56.3%成功率
- Libero-10:达到54.2%成功率
- 效率优势:使用约1.0M/4.1M样本(远少于其他模型7.7M/25.6M的训练预算),实现可比的性能
- 消融实验:随机选择明显不如近邻选择;学习的近邻估计器优于手工特征(特征空间平均距离、VLA条件困惑度、Delta困惑度)