一眼看懂
封面预览
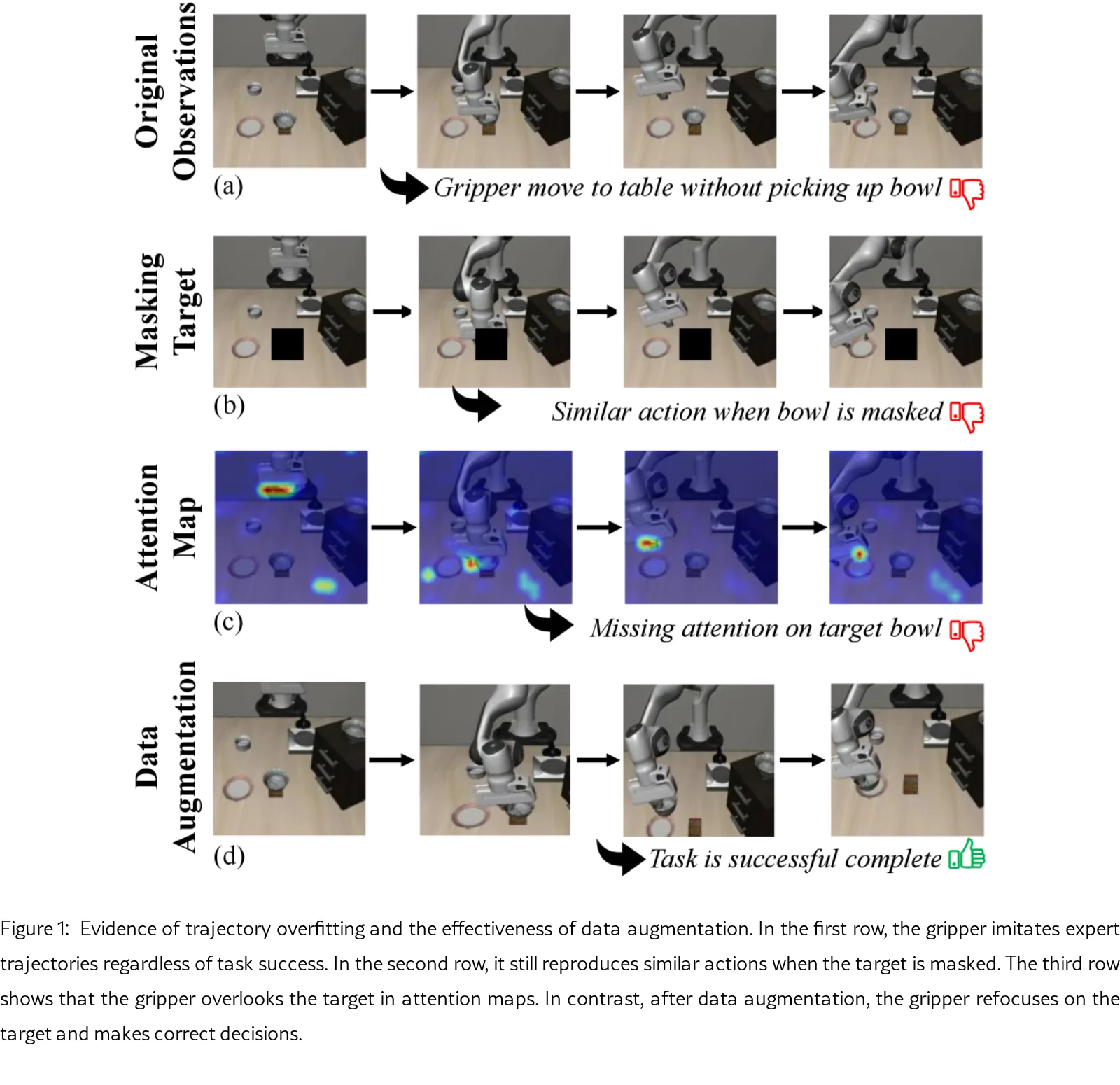
研究 Vision-Language-Action (VLA) 模型在顺序决策任务中的鲁棒性问题,发现 VLA 存在轨迹过拟合现象,即模型过度…
- 研究 Vision-Language-Action (VLA) 模型在顺序决策任务中的鲁棒性问题,发现 VLA 存在轨迹过拟合现象,即模型过度…
- 提出 PDF (Perturbation learning with Delayed Feedback),一种无需验证器的测试时适配框架,通过…
- 在 LIBERO 机器人操作基准和 Atari-57 游戏基准上验证方法有效性,显著提升任务成功率
Card 01
研究单位
研究单位
- 中国科学院软件研究所,北京
- 中国科学院大学,北京
- 清华大学,北京
- 北京大学王选计算机技术研究所,北京
- 国防大学,北京
Card 02
论文概述
论文概述
- 研究 Vision-Language-Action (VLA) 模型在顺序决策任务中的鲁棒性问题,发现 VLA 存在轨迹过拟合现象,即模型过度依赖动作与实体之间的虚假相关性,在环境轻微变化时性能急剧下降
- 提出 PDF (Perturbation learning with Delayed Feedback),一种无需验证器的测试时适配框架,通过数据增强和延迟反馈引导的扰动学习来提升 VLA 决策性能,无需对基础模型进行微调
- 在 LIBERO 机器人操作基准和 Atari-57 游戏基准上验证方法有效性,显著提升任务成功率
Card 03
核心贡献
核心贡献
- 首次系统性地识别并分析轨迹过拟合现象,揭示 VLA 在环境变化下脆弱性的根本原因
- 提出 PDF 框架,包含不确定性动作投票和延迟反馈引导的适配两大核心组件,在保持基础模型参数冻结的情况下提升决策性能
- 在 LIBERO (+7.4% 成功率) 和 Atari (+10.3 人类标准化分数) 上实现一致的性能提升,优于现有 VLA 和测试时适配基线方法
Card 04
方法描述
方法描述
- 不确定性动作投票:通过计算输出 logits 的标准化香农熵估计模型决策不确定性,根据不确定性自适应分配数据增强预算 N_t = N_max × U_t,对高不确定性决策分配更多增强视图
- 延迟反馈引导适配:引入轻量级扰动头 h_θ(·),在每轮交互后根据延迟反馈信号更新扰动参数,使用 REINFORCE 风格目标函数增加成功动作的似然,并结合 KL 散度正则化稳定更新
- 维度-wise 投票策略:在动作各维度上进行多数投票,而非对完整动作元组投票,以更灵活地偏离原始策略
Card 05
数据集与资源
数据集与资源
- LIBERO 基准:四个 10 任务套件(Spatial、Object、Goal、Long),Franka Panda 仿真环境,RGB 视图、机器人状态、文本指令和末端执行器增量动作
- Atari-57:57 个 Atari 2600 游戏,像素输入,4-18 个离散动作
- 基础模型:OpenVLA(LIBERO)和 Jat/GATO(Atari)
- 训练资源:单卡 Tesla V100-PCIE-32GB,每游戏 50 评估回合
Card 06
评估与结果
评估与结果
- LIBERO 基准:PDF 达到最高平均成功率 0.77(排名 2.5),Spatial 套件 0.90,Goal 套件 0.86,Long 套件 0.59(+4.1% 超越最佳基线)
- Atari-57:人类标准化分数达到 1.07(基线 0.97,+0.10),47/57 游戏性能提升,最大增益出现在 BOXING (+60.25%) 和 TIME PILOT (+53%)
- 消融实验:数据增强和延迟反馈两个组件均对性能有贡献,KL 正则化项对稳定性至关重要,最佳数据增强预算设为 3