一眼看懂
封面预览
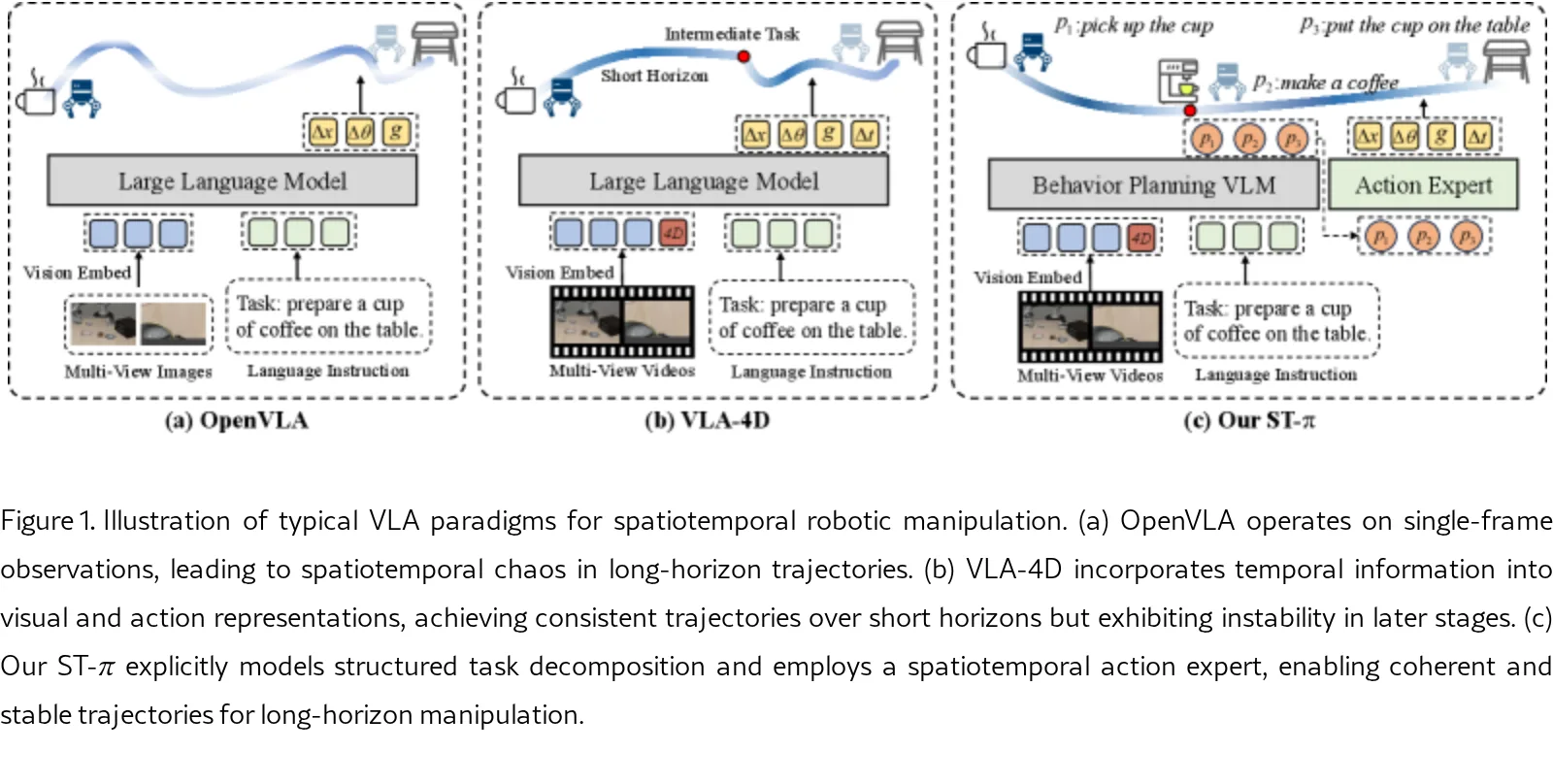
提出了 ST-π,一个结构化的时空视觉-语言-动作(VLA)模型,旨在解决机器人细粒度时空操控任务中的挑战
- 提出了 ST-π,一个结构化的时空视觉-语言-动作(VLA)模型,旨在解决机器人细粒度时空操控任务中的挑战
- 针对现有方法隐式时空推理难以处理长时序任务中多个连续行为及显式时空边界的问题,设计了一个显式建模时空结构的统一框架
- 核心目标是通过显式、结构化的时空建模,实现从块级任务规划到步级动作执行的精细操控
Card 01
研究单位
研究单位
- 华中科技大学 人工智能与自动化学院
- 新加坡国立大学 计算机学院
- 麦考瑞大学 计算机学院
Card 02
论文概述
论文概述
- 提出了 ST-π,一个结构化的时空视觉-语言-动作(VLA)模型,旨在解决机器人细粒度时空操控任务中的挑战
- 针对现有方法隐式时空推理难以处理长时序任务中多个连续行为及显式时空边界的问题,设计了一个显式建模时空结构的统一框架
- 核心目标是通过显式、结构化的时空建模,实现从块级任务规划到步级动作执行的精细操控
Card 03
核心贡献
核心贡献
- 提出统一的 ST-π 框架,显式构建块级任务分解与步级动作生成,实现精细操控
- 设计 ST-VLM(时空视觉-语言模型),用于行为规划,预测因果有序的子任务作为块级动作提示
- 引入 ST-AE(时空动作专家),采用互补的空间与时间生成器,生成空间连贯且时间一致的动作
- 构建 STAR 数据集,一个包含结构化子任务标注的真实世界长时序机器人操控数据集,用于模型微调
Card 04
方法描述
方法描述
- 模型由 ST-VLM 和 ST-AE 两个关键组件构成,前者负责全局时空行为规划,后者负责局部时空控制精炼
- ST-VLM 将4D观测和任务指令编码为潜在空间,通过大语言模型自回归生成包含语义意图、空间定位和时间属性的块级动作提示序列
- ST-AE 基于块级动作提示,采用结构化双生成器引导(空间生成器和时间生成器),通过流匹配过程联合建模空间依赖和时间因果性,预测步级动作参数
- 创新点在于显式结构化时空推理、块级因果注意力分解以及双生成器的互补时空引导
Card 05
数据集与资源
数据集与资源
- 使用的数据集包括:ScanNet系列(用于空间表示对齐)、DROID-ST(结构化任务分解数据集)和自建的 STAR 数据集(真实世界长时序操控,含30个任务,约300k交互步)
- 模型骨干网络采用 PaliGemma(来自π_0.5)、DINOv2(来自VGGT)和 Gemma-300M 作为动作专家
- 训练资源为 8块 NVIDIA RTX PRO 6000 GPU
Card 06
评估与结果
评估与结果
- 评估环境包括仿真基准 LIBERO、SIMPLER 和真实世界基准 STAR
- 主要评估指标为任务成功率(SR)和完成时间(CT)
- 在 LIBERO 基准上,ST-π 平均成功率达 97.3%,完成时间 5.9s,优于所有基线模型
- 在真实世界 STAR 基准上,ST-π 平均成功率达 80.1%,尤其在长时序任务中优势显著
- 消融实验验证了结构化时空框架、因果注意力机制和4D观测模态的有效性