一眼看懂
封面预览
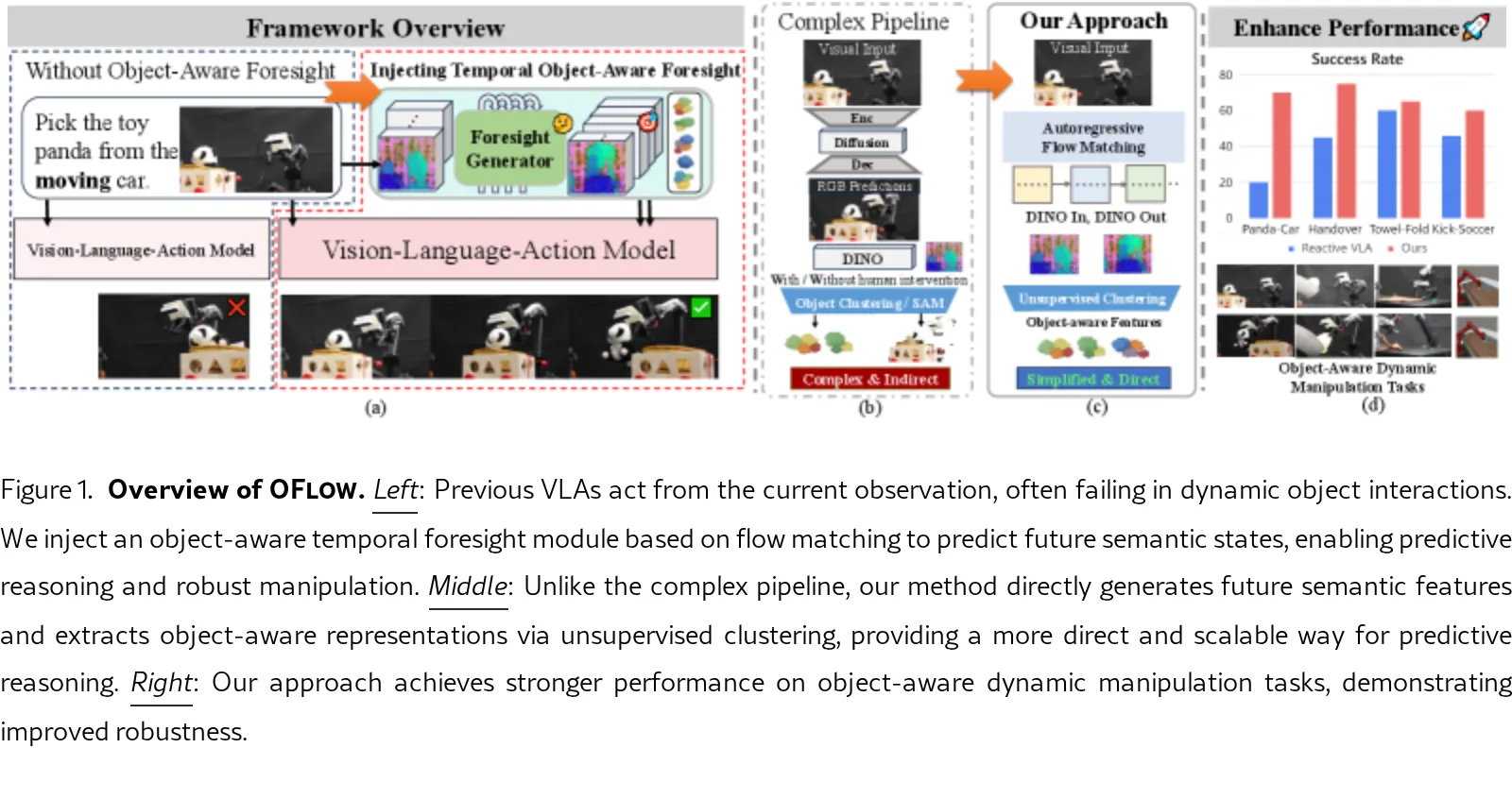
论文提出了 OFlow 框架,将对象感知的时间流匹配注入到视觉-语言-动作(VLA)模型中,以解决现有模型仅依赖当前帧进行反应式决策的局限性。
- 论文提出了 OFlow 框架,将对象感知的时间流匹配注入到视觉-语言-动作(VLA)模型中,以解决现有模型仅依赖当前帧进行反应式决策的局限性。
- 该方法在共享的语义潜在空间中统一了时间前瞻和对象感知推理,通过预测未来的语义状态并分解为对象感知表示来增强环境推理能力。
- 实验证明,该方法在分布偏移下能实现更可靠的机器人控制,显著提升了操作任务的鲁棒性和成功率。
Card 01
研究单位
研究单位
- Fudan University
- University of Southern California
- KAUST
Card 02
论文概述
论文概述
- 论文提出了 OFlow 框架,将对象感知的时间流匹配注入到视觉-语言-动作(VLA)模型中,以解决现有模型仅依赖当前帧进行反应式决策的局限性。
- 该方法在共享的语义潜在空间中统一了时间前瞻和对象感知推理,通过预测未来的语义状态并分解为对象感知表示来增强环境推理能力。
- 实验证明,该方法在分布偏移下能实现更可靠的机器人控制,显著提升了操作任务的鲁棒性和成功率。
Card 03
核心贡献
核心贡献
- 提出了 OFlow 框架,将语义前瞻能力与连续动作生成相结合,克服了现有 VLA 模型缺乏预测性推理的问题。
- 设计了基于 DINOv2 特征空间的因果时间流匹配模型,用于预测未来场景动态,并结合无监督聚类实现了对象感知的场景分解。
- 引入了 ControlNet 风格的条件注入机制,利用预测的对象感知未来特征引导流匹配动作策略的生成。
- 在多个模拟基准和真实世界任务中进行了广泛验证,证明了方法在提升环境推理和鲁棒性方面的显著效果。
Card 04
方法描述
方法描述
- 使用 Eagle-2.5 作为 VLM 主干提取视觉-语言特征,并利用 DINOv2 提取图像的语义潜在嵌入以保留高层语义结构。
- 采用基于 Diffusion Transformer (DiT) 的自回归流匹配进行时间外推,通过因果时间注意力机制和帧内密集注意力机制并行训练。
- 利用无监督聚类算法对预测的未来帧特征进行对象感知场景分解,生成分层级的语义原型以过滤背景噪声并强调任务相关对象。
- 通过零初始化的交叉注意力模块将对象感知特征注入到动作生成主干中,保持与预训练 VLA 模型的兼容性。
Card 05
数据集与资源
数据集与资源
- 基准数据集:LIBERO、LIBERO-Plus、MetaWorld (MT50)、SimplerEnv。
- 真实世界任务:包含动态交互、精确放置、可变形物体处理等 7 种任务(如 Panda-Car, Handover, Towel-Fold)。
- 训练硬件:使用 8 NVIDIA A100 GPUs。
- 真实世界部署硬件:NVIDIA RTX 6000 Ada GPU、ARX X5 机械臂、Intel RealSense D435 相机。
- 模型规模:VLM 主干 1.6B 参数,动作头 1.2B 参数,前瞻模型 0.2B 参数。
Card 06
评估与结果
评估与结果
- 在 LIBERO 基准上实现了 96.6% 的总体成功率,在长视野任务上达到 94.5%,优于 OpenVLA、$\pi_0$ 等基线。
- 在 LIBERO-Plus 鲁棒性测试中总体成功率达到 72.3%,面对视觉和物理扰动时表现最稳健。
- 在 SimplerEnv 和 MetaWorld 上分别取得了 67.1% 和 85.6% 的最佳平均成功率,显著优于 GR00T-N1.5 等对比模型。
- 在真实世界实验中,总体平均成功率为 69%,特别是在动态任务 Panda-Car 中将成功率从基线的约 20-25% 提升至 70%。