一眼看懂
封面预览
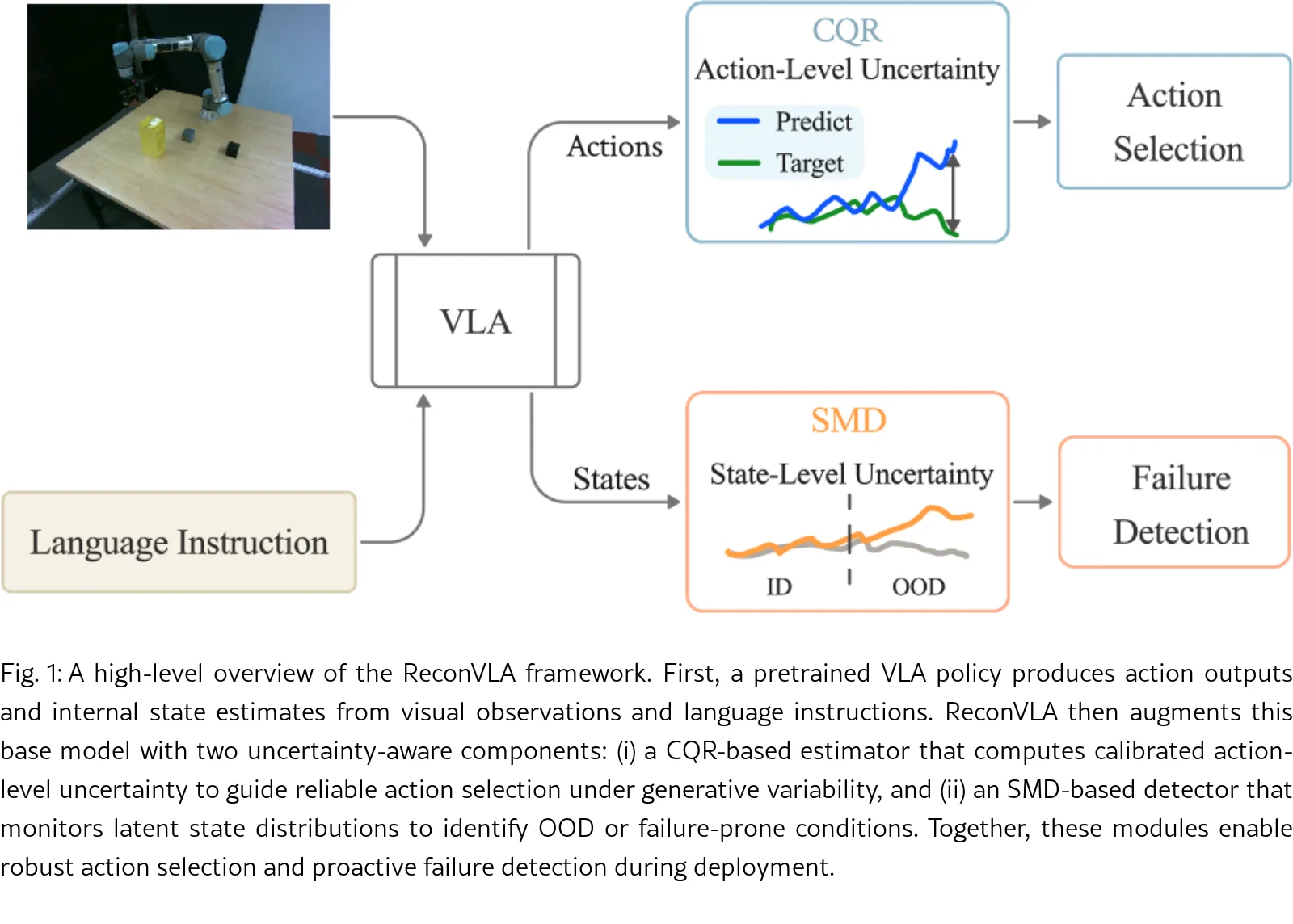
提出了 ReconVLA 框架,旨在为预训练的视觉-语言-动作(VLA)模型提供校准的不确定性估计和主动故障检测能力
- 提出了 ReconVLA 框架,旨在为预训练的视觉-语言-动作(VLA)模型提供校准的不确定性估计和主动故障检测能力
- 解决现有VLA模型缺乏置信度度量的问题,使机器人能够预测并避免执行失败,提升实际部署中的可靠性
- 通过在不修改底层模型的情况下,利用 共形预测(Conformal Prediction) 技术增强VLA策略的鲁棒性
Card 01
研究单位
研究单位
- 德克萨斯大学阿灵顿分校 计算机科学与工程系
Card 02
论文概述
论文概述
- 提出了 ReconVLA 框架,旨在为预训练的视觉-语言-动作(VLA)模型提供校准的不确定性估计和主动故障检测能力
- 解决现有VLA模型缺乏置信度度量的问题,使机器人能够预测并避免执行失败,提升实际部署中的可靠性
- 通过在不修改底层模型的情况下,利用 共形预测(Conformal Prediction) 技术增强VLA策略的鲁棒性
Card 03
核心贡献
核心贡献
- 提出对VLA策略动作生成过程不确定性的系统性分解,将其分为 输入不确定性 和 噪声不确定性 两大类
- 设计了基于 共形分位数回归(CQR) 的动作级不确定性量化方法,用于评估候选动作的可靠性并指导选择
- 开发了基于 马氏距离(SMD) 的状态级运行时故障检测机制,用于识别偏离安全状态分布的异常情况
- 构建了一个统一的不确定性感知控制框架,将动作级和状态级模块集成,实现端到端的可靠性增强
Card 04
方法描述
方法描述
- 框架包含两个核心模块:动作级不确定性感知动作选择模块 和 状态级运行时故障检测模块
- 动作级模块使用CQR对VLA输出的动作Token进行校准不确定性估计,并通过计算预测区间宽度或相似度分数来筛选低不确定性动作
- 状态级模块通过计算机器人当前状态与专家演示状态分布之间的马氏距离,实时检测分布外(OOD)或不安全状态
- 整个框架作为轻量级运行时层部署在冻结的VLA策略旁,无需重新训练或修改原模型
Card 05
数据集与资源
数据集与资源
- 使用了 LIBERO基准 的LIBERO-Object任务套件,包含10个物体操作任务和50条专家演示轨迹
- 在真实环境中使用 Universal Robots UR5 机械臂 进行验证,收集了100条轨迹用于4个移动导向型操作任务
- 模型选择上,使用了 π₀ 模型作为生成式(随机)策略的代表,以及 OpenVLA-OFT 模型作为确定性策略的代表
- 项目代码、文档和演示可在指定网站获取:https://robotic-vision-lab.github.io/reconvla
Card 06
评估与结果
评估与结果
- 采用 EU-VLA基准 的评估指标,包括Spearman等级相关系数、Vargha-Delaney A12效应量和Cohen's d标准化差异
- 额外采用 SAFE框架 的评估协议,将不确定性分数作为二元故障分类器并计算AUC值
- 在仿真实验中,CQR校准的动作预测显著改善了故障预测、降低了灾难性错误,并提供了校准的置信度度量
- 真实机器人实验验证了框架的有效性,成功实现了成功-失败分离、分布偏移下的可靠性保持以及工作空间边缘的故障检测