一眼看懂
封面预览
论文提出 AEGIS (Anchor-Enforced Gradient Isolation System),解决视觉语言动作(VLA)模型微…
- 论文提出 AEGIS (Anchor-Enforced Gradient Isolation System),解决视觉语言动作(VLA)模型微…
- 核心问题:跨模态梯度不对称——flow-matching 动作专家产生的高幅度低秩MSE梯度与交叉熵预训练的高维语义流形不匹配,导致VQA能力…
- 现有工业界方法(stop-gradient、LoRA)要么完全丢弃连续监督信号,要么无法防止低秩子空间内的破坏性更新
Card 01
研究单位
研究单位
- Guransh Singh - Independent Researcher (guransh766@gmail.com)
Card 02
论文概述
论文概述
- 论文提出 AEGIS (Anchor-Enforced Gradient Isolation System),解决视觉语言动作(VLA)模型微调中的灾难性遗忘问题
- 核心问题:跨模态梯度不对称——flow-matching 动作专家产生的高幅度低秩MSE梯度与交叉熵预训练的高维语义流形不匹配,导致VQA能力快速退化
- 现有工业界方法(stop-gradient、LoRA)要么完全丢弃连续监督信号,要么无法防止低秩子空间内的破坏性更新
- AEGIS无需VQA协同训练数据或回放缓冲区,通过层-wise正交梯度投影直接保留预训练VQA流形
Card 03
核心贡献
核心贡献
- 识别跨模态梯度不对称为VLA微调中VQA退化的根本原因,证明高集中度的MSE梯度会覆盖分散在高维奇异方向上的语义参数
- 提出 AEGIS 框架:在Wasserstein-2流形上构建静态高斯锚点,通过顺序双反向传播分解任务梯度和锚点梯度,应用Gram-Schmidt正交投影消除破坏性梯度干扰
- 提出层-wise粒度的正交投影,在全局(零和漏洞)和逐张量(破坏注意力头同步)之间找到几何最优位置
- 投影仅损失不到1%的梯度能量,即可消除导致严重遗忘的累积激活漂移
Card 04
方法描述
方法描述
- 静态Wasserstein锚点:在微调前,从3000个VQA v2样本的掩码前向传播中预计算26个transformer层的激活统计量(均值和方差),使用完整注意力掩码覆盖图像+文本token
- Wasserstein-2传输惩罚:对角协方差高斯之间的Wasserstein-2距离具有闭式Bures度量,可分解为均值漂移和标准差失配两项,生成锚点恢复梯度
- 顺序双反向传播:首先反向传播任务损失L_FM并缓存梯度,然后反向传播L_OT并缓存梯度,两者共享计算图
- 层-wise Gram-Schmidt投影:对每个transformer层,计算任务梯度和OT梯度的点积,当d_ℓ<0时执行正交投影:g_final = g_task - α_ℓ * g_ot,其中α_ℓ = d_ℓ/\|\|g_ot\|\|²
Card 05
数据集与资源
数据集与资源
- VLM backbone: PaliGemma2-3B-Mix-224(SigLIP-400M视觉编码器 + Gemma-2B语言模型 + 多模态投影器)
- 动作数据: LIBERO benchmark suite(桌面操作任务),每个样本包含两个RGB图像、感知状态、 语言指令、50步7-DoF motor commands
- 预计算成本: 单GPU约5分钟处理3000个VQA v2样本生成静态锚点
- 训练: 冻结视觉编码器,只微调Gemma-2B LM和多模态投影器
Card 06
评估与结果
评估与结果
- 评估协议: 周期性在VQA v2验证集上测量VQA holdout loss
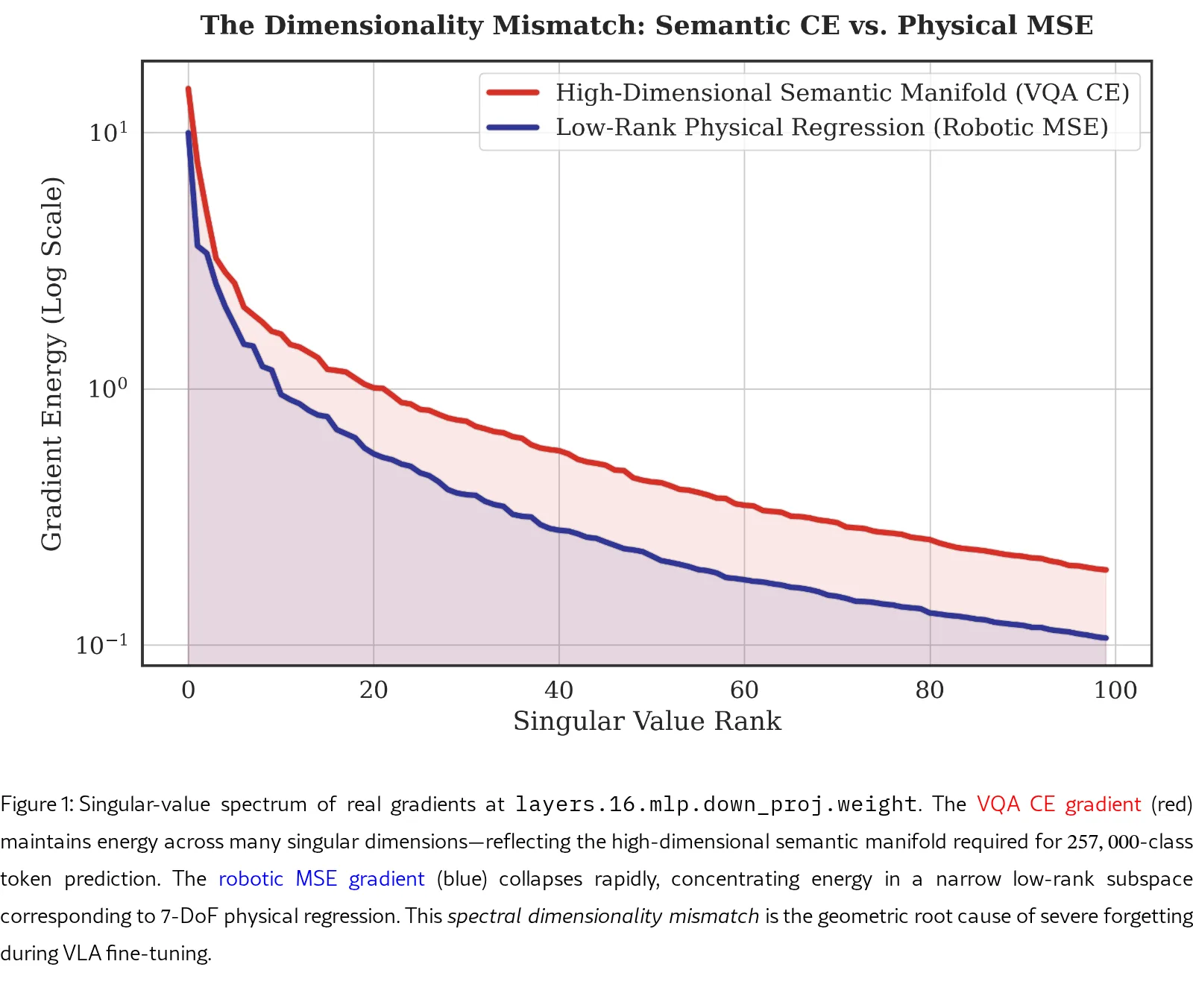
- 光谱维度不匹配: VQA CE梯度能量分散在数百个奇异维度(MSE梯度在20个方向上集中超过90%能量)
- VQA保持: AEGIS在1500步连续微调后VQA loss保持稳定,而naive微调显著退化,LoRA部分减缓但仍有退化
- 动作学习收敛: AEGIS保持完整的连续监督信号,动作学习收敛速度与naive微调相当
- 投影动力学: 节流率约30%层显示破坏性干扰,平均投影能量损失<1%,任务梯度和锚点梯度接近正交