一眼看懂
封面预览
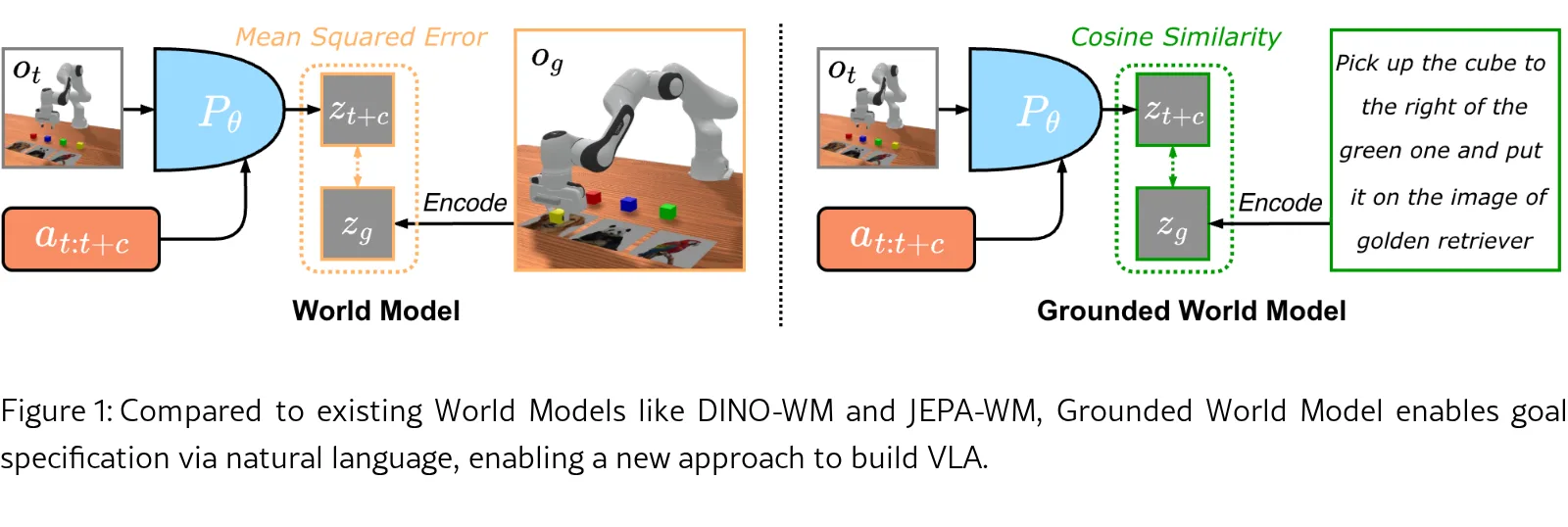
论文提出 Grounded World Model (GWM),旨在解决传统世界模型难以通过自然语言指定目标的问题,实现语义泛化规划。
- 论文提出 Grounded World Model (GWM),旨在解决传统世界模型难以通过自然语言指定目标的问题,实现语义泛化规划。
- 核心思想是在预训练的视觉语言对齐潜在空间中学习状态转换函数,利用文本指令与预测未来结果的嵌入相似度进行规划。
- 研究构建了 WISER 基准测试,用于评估视觉语言动作模型在面对未见视觉信号和指称表达时的语义泛化能力。
Card 01
研究单位
研究单位
- Independent Researcher
- EPFL
- Beihang University
- University of Toronto
- NUS (National University of Singapore)
Card 02
论文概述
论文概述
- 论文提出 Grounded World Model (GWM),旨在解决传统世界模型难以通过自然语言指定目标的问题,实现语义泛化规划。
- 核心思想是在预训练的视觉语言对齐潜在空间中学习状态转换函数,利用文本指令与预测未来结果的嵌入相似度进行规划。
- 研究构建了 WISER 基准测试,用于评估视觉语言动作模型在面对未见视觉信号和指称表达时的语义泛化能力。
Card 03
核心贡献
核心贡献
- 提出了 Grounded World Model (GWM),在视觉语言对齐的潜在空间中学习世界模型,使规划能够通过自然语言指令进行目标指定。
- 构建了 WISER (World-knowledge Integrated Semantic Embodied Reasoning) 基准,包含24个世界知识类别、共288个训练与测试任务,专门用于评估语义泛化能力。
- 实验证明,基于GWM的规划系统 GWM-MPC 在WISER基准上达到87%测试成功率,显著优于平均成功率仅为22%的现有VLA模型。
- 提出了 Rendering-based Action Tokenization (RAT),一种无需训练、与具体机器人无关的动作编码方法,实现了跨机器人平台的零样本泛化。
- 通过对比实验揭示了现有基于VLM微调的VLA模型普遍存在知识遗忘和语义泛化能力不足的问题。
Card 04
方法描述
方法描述
- 采用基于 Qwen3-VL-Embedding 多模态检索模型的冻结潜在空间,在其中从头训练世界模型的转换函数。
- 使用 Model Predictive Control (MPC) 框架,通过 KNN 从演示数据中检索候选轨迹,利用GWM预测其未来结果。
- 利用预训练检索模型计算预测结果嵌入与指令嵌入之间的余弦相似度,选择得分最高的轨迹执行。
- 创新点在于将世界模型的预测目标与多模态嵌入空间结合,避免了像素重建,并直接利用了基础模型的视觉语言理解能力。
Card 05
数据集与资源
数据集与资源
- 提出了 WISER 模拟基准数据集,包含24个类别,每个类别有12个训练任务和12个测试任务,共288个任务。
- 数据在 ManiSkill 仿真环境中收集,使用 Franka Panda 机器人,控制频率为20Hz,仿真频率为100Hz。
- 训练数据包含1728条轨迹,每个任务收集6条随机初始状态的轨迹。
- 数据集格式提供了 LeRobot V2.1/V3.0 和 RLDS 版本。
- 模型训练仅需 20 GPU小时,推理效率受限于需进行N=12次模型推理。
Card 06
评估与结果
评估与结果
- 评估在 WISER 基准上进行,使用三个二元指标:Grasp(抓取正确立方体)、Reach(到达目标点)和 Success(完整完成任务)。
- 主要结果显示,GWM-MPC 在测试集上达到87%成功率,而十个主流VLA基线模型(如π0, π0.5, InternVLA-A1等)平均测试成功率仅为22%,训练集平均成功率达90%。
- 消融实验表明,渲染动作tokenization (RAT) 优于可学习的动作编码器,并实现了对 xArm6 机器人的零样本跨本体泛化。
- GT-MPC(使用真实未来嵌入)实验设定了性能上限,表明系统性能瓶颈在于预训练检索模型本身的评分能力。
- 实验证实现有VLA模型尽管在训练集表现优异,但在面对未见过的世界知识和指称表达时泛化能力严重不足。