一眼看懂
封面预览
提出了 LARY 基准,用于评估视觉到动作对齐中的潜在动作表示。
- 提出了 LARY 基准,用于评估视觉到动作对齐中的潜在动作表示。
- 解决了当前缺乏对潜在动作表示质量和有效性进行严格量化评估框架的问题。
- 证明了通用的视觉基础模型在无需显式动作监督的情况下,能够捕获语义动作特征,且优于专门的具身动作模型。
Card 01
研究单位
研究单位
- Meituan(北京,中国)
Card 02
论文概述
论文概述
- 提出了 LARY 基准,用于评估视觉到动作对齐中的潜在动作表示。
- 解决了当前缺乏对潜在动作表示质量和有效性进行严格量化评估框架的问题。
- 证明了通用的视觉基础模型在无需显式动作监督的情况下,能够捕获语义动作特征,且优于专门的具身动作模型。
Card 03
核心贡献
核心贡献
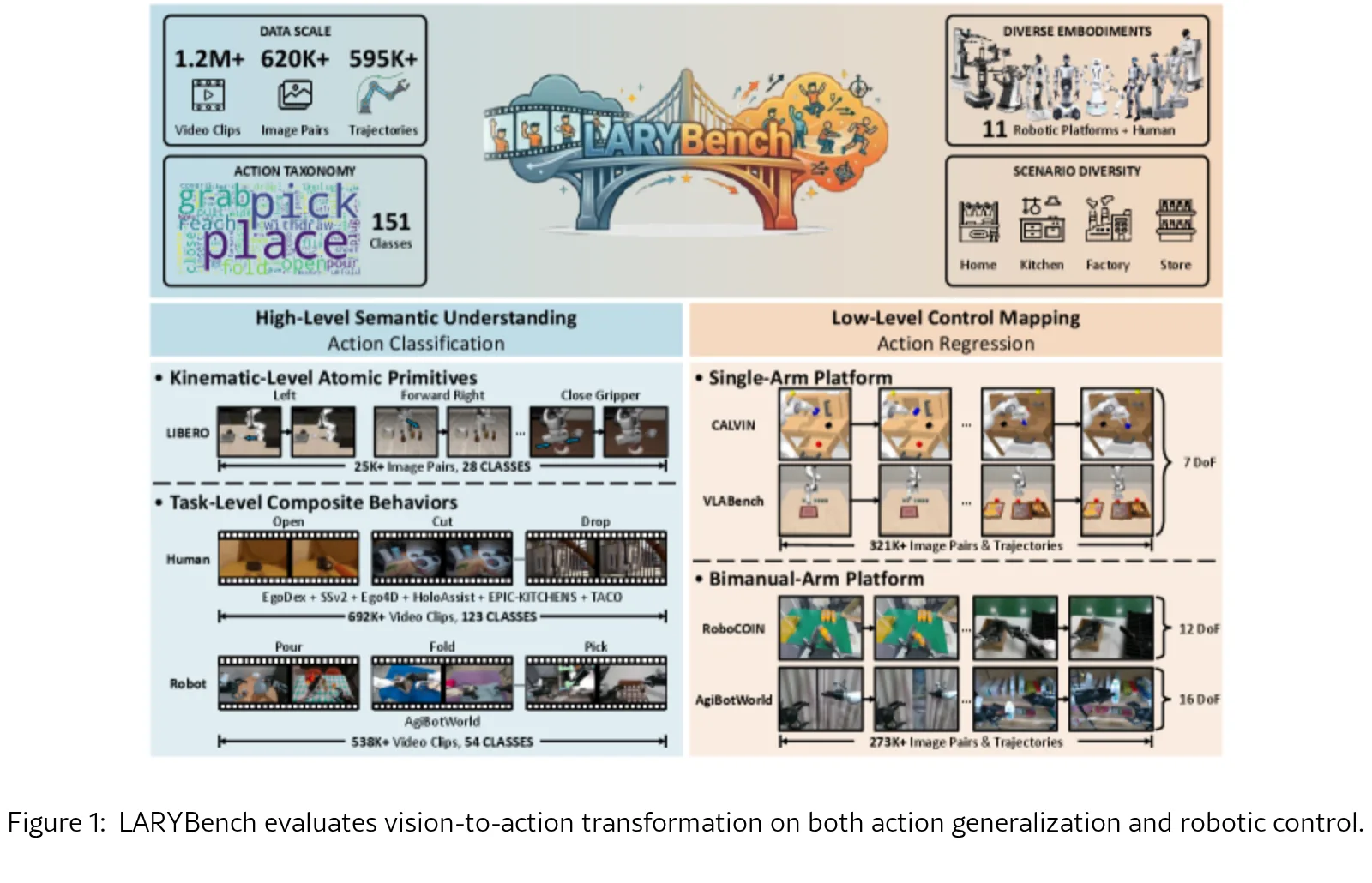
- 提出了 LARYBench,首个将潜在动作表示评估与下游策略性能解耦的基准,涵盖高层语义动作(做什么)和低层物理控制(怎么做)两个维度。
- 开发了自动化数据引擎,构建了大规模数据集,包含 120 万视频、151 个动作类别、620K 图像对 和 595K 运动轨迹,覆盖 11 种机器人形态。
- 通过对 11 种模型 的系统评估,揭示了通用视觉表示和基于潜在特征的学习路径优于像素级重建和特定具身训练的关键发现。
Card 04
方法描述
方法描述
- 设计了分层语义探测协议,通过分类任务评估高层语义理解,使用回归任务评估低层物理控制能力。
- 提出了一类新的模型 General LAMs,将 LAPA 训练框架嫁接到冻结的通用视觉骨干网络(如 DINOv3、SigLIP2)上。
- 使用 Motion-Guided Sampler (MGSampler) 解决视频采样中的时间动态捕捉问题,并使用 Attentive Probe 进行语义分类评估。
Card 05
数据集与资源
数据集与资源
- 使用的数据集为自建的 LARYBench,整合了 HoloAssist、Ego4D、Something-Somethingv2、AgiBotWorld-Beta、CALVIN 等多个现有数据集。
- 数据集规模超过 1000 小时 视频,涵盖人类和机器人操作场景。
- 评估的模型参数量范围从 84M 到 704M(如 V-JEPA 2 303M,DINOv3 303M,LAPA 343M)。
Card 06
评估与结果
评估与结果
- 评估指标包括语义动作分类的 Top-1 Accuracy 和低层控制回归的 MSE。
- V-JEPA 2 在分类任务上取得最佳平均准确率(76.62%),证明了自监督视觉模型无需显式动作监督即可学习有效的动作表示。
- DINOv3 在回归任务上取得最佳平均 MSE(0.19),表明基于潜在特征的空间比基于像素的空间更适合机器人控制。
- 实验表明 General LAMs(如 LAPA-DINOv3)性能优于原始的 Embodied LAMs(如 LAPA, UniVLA),但仍略逊于纯视觉编码器。
- 消融实验发现,适中的码本大小(cs=64)和序列长度(sl=49)能避免码本坍塌并保持高性能。